 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOPPR Medical-Grade Platform for Medical Imaging AI
Nov 26, 2024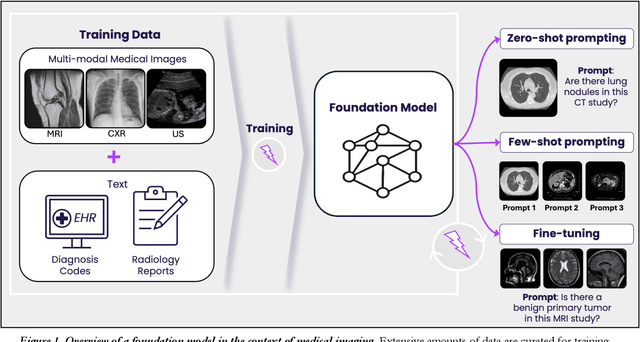
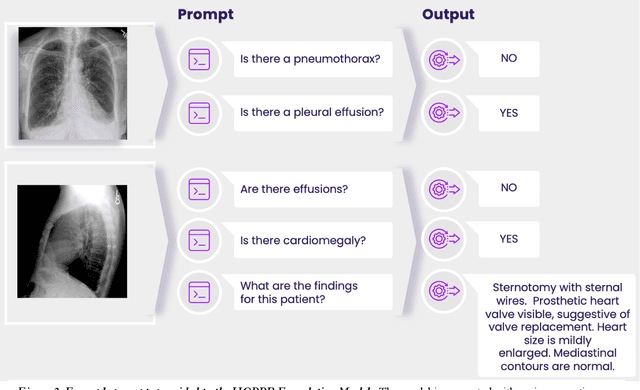
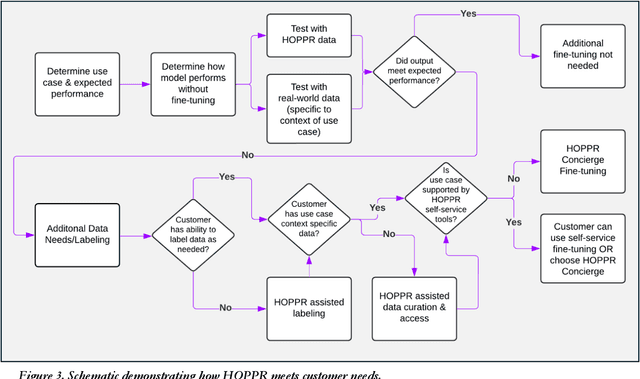
Technological advances in artificial intelligence (AI) have enabled the development of large vision language models (LVLMs) that are trained on millions of paired image and text samples. Subsequent research efforts have demonstrated great potential of LVLMs to achieve high performance in medical imaging use cases (e.g., radiology report generation), but there remain barriers that hinder the ability to deploy these solutions broadly. These include the cost of extensive computational requirements for developing large scale models, expertise in the development of sophisticated AI models, and the difficulty in accessing substantially large, high-quality datasets that adequately represent the population in which the LVLM solution is to be deployed. The HOPPR Medical-Grade Platform addresses these barriers by providing powerful computational infrastructure, a suite of foundation models on top of which developers can fine-tune for their specific use cases, and a robust quality management system that sets a standard for evaluating fine-tuned models for deployment in clinical settings. The HOPPR Platform has access to millions of imaging studies and text reports sourced from hundreds of imaging centers from diverse populations to pretrain foundation models and enable use case-specific cohorts for fine-tuning. All data are deidentified and securely stored for HIPAA compliance. Additionally, developers can securely host models on the HOPPR platform and access them via an API to make inferences using these models within established clinical workflows. With the Medical-Grade Platform, HOPPR's mission is to expedite the deployment of LVLM solutions for medical imaging and ultimately optimize radiologist's workflows and meet the growing demands of the field.
An untrained deep learning method for reconstructing dynamic magnetic resonance images from accelerated model-based data
May 04, 2022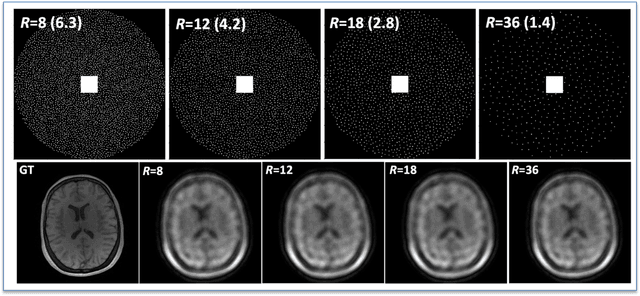

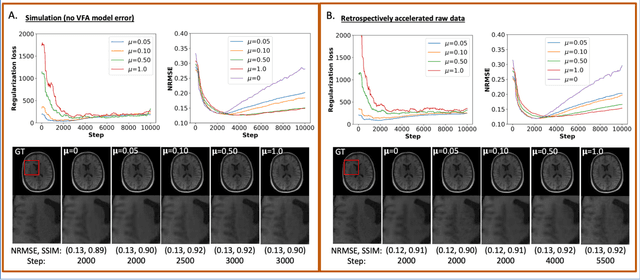
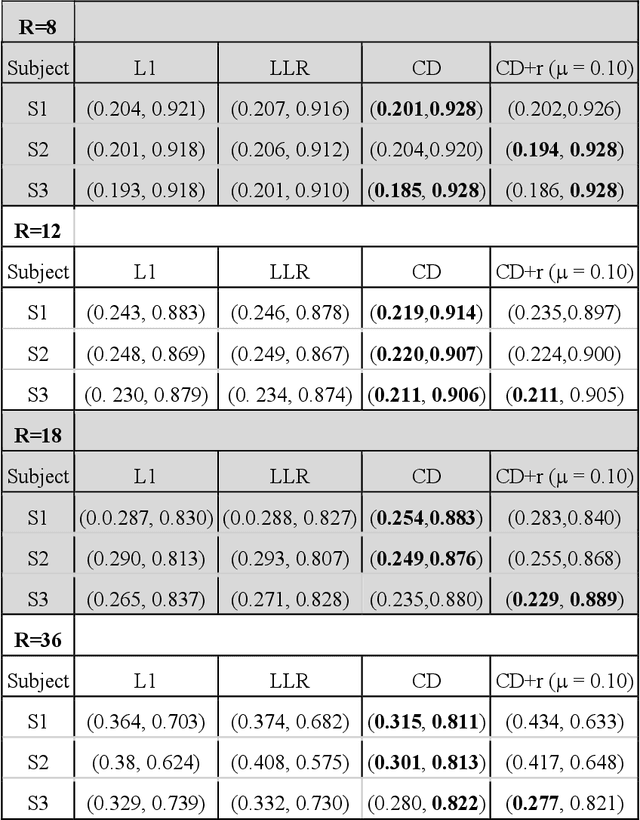
The purpose of this work is to implement physics-based regularization as a stopping condition in tuning an untrained deep neural network for reconstructing MR images from accelerated data. The ConvDecoder neural network was trained with a physics-based regularization term incorporating the spoiled gradient echo equation that describes variable-flip angle (VFA) data. Fully-sampled VFA k-space data were retrospectively accelerated by factors of R={8,12,18,36} and reconstructed with ConvDecoder (CD), ConvDecoder with the proposed regularization (CD+r), locally low-rank (LR) reconstruction, and compressed sensing with L1-wavelet regularization (L1). Final images from CD+r training were evaluated at the \emph{argmin} of the regularization loss; whereas the CD, LR, and L1 reconstructions were chosen optimally based on ground truth data. The performance measures used were the normalized root-mean square error, the concordance correlation coefficient (CCC), and the structural similarity index (SSIM). The CD+r reconstructions, chosen using the stopping condition, yielded SSIMs that were similar to the CD (p=0.47) and LR SSIMs (p=0.95) across R and that were significantly higher than the L1 SSIMs (p=0.04). The CCC values for the CD+r T1 maps across all R and subjects were greater than those corresponding to the L1 (p=0.15) and LR (p=0.13) T1 maps, respectively. For R > 12 (<4.2 minutes scan time), L1 and LR T1 maps exhibit a loss of spatially refined details compared to CD+r. We conclude that the use of an untrained neural network together with a physics-based regularization loss shows promise as a measure for determining the optimal stopping point in training without relying on fully-sampled ground truth data.