 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Image Super-Resolution for Domain-Specific Ultra-Low Bandwidth Image Transmission
Sep 22, 2020

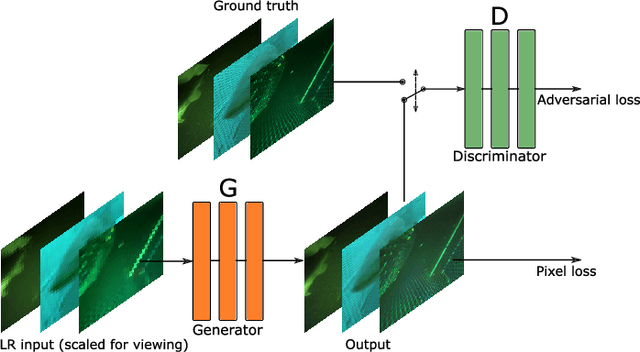

Low-bandwidth communication, such as underwater acoustic communication, is limited by best-case data rates of 30--50 kbit/s. This renders such channels unusable or inefficient at best for single image, video, or other bandwidth-demanding sensor-data transmission. To combat data-transmission bottlenecks, we consider practical use-cases within the maritime domain and investigate the prospect of Single Image Super-Resolution methodologies. This is investigated on a large, diverse dataset obtained during years of trawl fishing where cameras have been placed in the fishing nets. We propose down-sampling images to a low-resolution low-size version of about 1 kB that satisfies underwater acoustic bandwidth requirements for even several frames per second. A neural network is then trained to perform up-sampling, trying to reconstruct the original image. We aim to investigate the quality of reconstructed images and prospects for such methods in practical use-cases in general. Our focus in this work is solely on learning to reconstruct the high-resolution images on "real-world" data. We show that our method achieves better perceptual quality and superior reconstruction than generic bicubic up-sampling and motivates further work in this area for underwater applications.
SeaShark: Towards a Modular Multi-Purpose Man-Portable AUV
Sep 12, 2020



In this work, we present the SeaShark AUV: a modular, easily configurable, one-man portable micro-AUV. The SeaShark AUV is conceived as modular parts that fit around a central main tube, which holds battery and other vital parts. The head unit comprises easy exhangeable, stackable, and 360 degree rotatable payload sections to quickly obtain a suitable configuration for many objectives. We employ navigation no better than dead reckoning or relative navigation with respect to some well-known structure, and thus aim at underwater activities that do not require highly accurate geo-referenced data-points. Operating the SeaShark AUV requires only the vehicle itself and a tablet for mission planning and post-mission review. We have built several complete SeaShark systems and have begun exploring the many possibilities and use-cases in both research and commercial use. Here we present a comprehensive overview and introduction to our AUV and operation principles, and further show data examples for experimental operations for shore-to-sea bio-habitat mapping and in-harbor wall and pier inspection
Deep Learning based Segmentation of Fish in Noisy Forward Looking MBES Images
Jun 16, 2020



In this work, we investigate a Deep Learning (DL) approach to fish segmentation in a small dataset of noisy low-resolution images generated by a forward-looking multibeam echosounder (MBES). We build on recent advances in DL and Convolutional Neural Networks (CNNs) for semantic segmentation and demonstrate an end-to-end approach for a fish/non-fish probability prediction for all range-azimuth positions projected by an imaging sonar. We use self-collected datasets from the Danish Sound and the Faroe Islands to train and test our model and present techniques to obtain satisfying performance and generalization even with a low-volume dataset. We show that our model proves the desired performance and has learned to harness the importance of semantic context and take this into account to separate noise and non-targets from real targets. Furthermore, we present techniques to deploy models on low-cost embedded platforms to obtain higher performance fit for edge environments - where compute and power are restricted by size/cost - for testing and prototyping.
BatVision with GCC-PHAT Features for Better Sound to Vision Predictions
Jun 14, 2020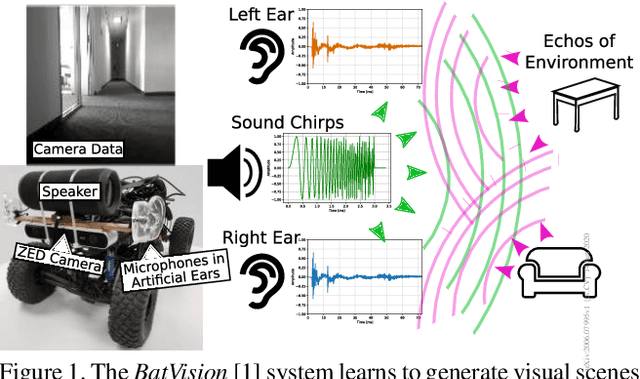
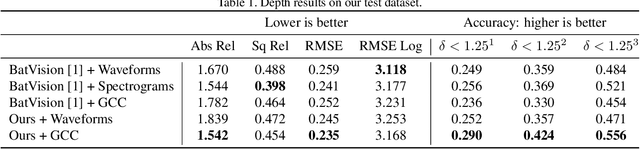


Inspired by sophisticated echolocation abilities found in nature, we train a generative adversarial network to predict plausible depth maps and grayscale layouts from sound. To achieve this, our sound-to-vision model processes binaural echo-returns from chirping sounds. We build upon previous work with BatVision that consists of a sound-to-vision model and a self-collected dataset using our mobile robot and low-cost hardware. We improve on the previous model by introducing several changes to the model, which leads to a better depth and grayscale estimation, and increased perceptual quality. Rather than using raw binaural waveforms as input, we generate generalized cross-correlation (GCC) features and use these as input instead. In addition, we change the model generator and base it on residual learning and use spectral normalization in the discriminator. We compare and present both quantitative and qualitative improvements over our previous BatVision model.
BatVision: Learning to See 3D Spatial Layout with Two Ears
Dec 15, 2019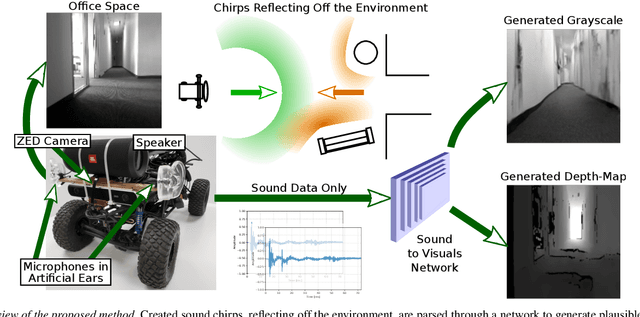
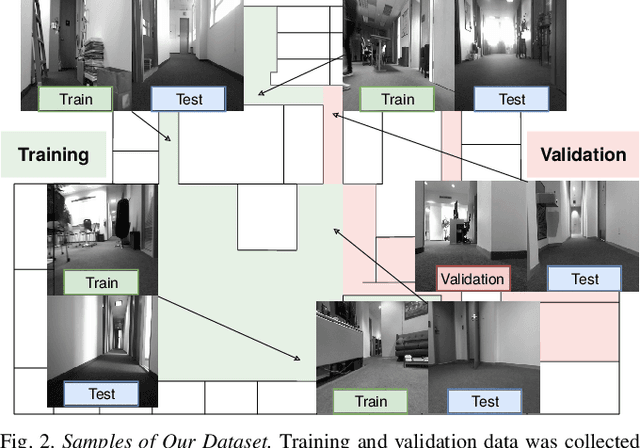
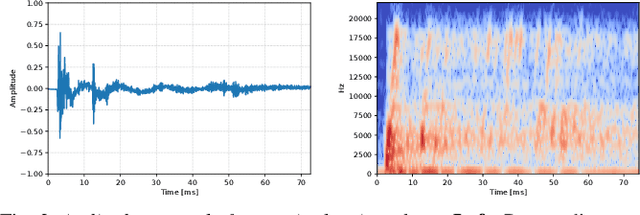
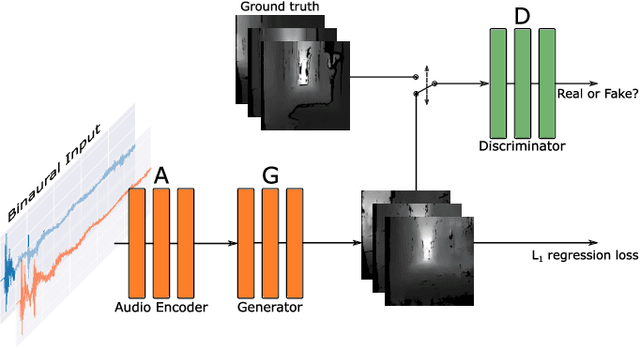
Virtual camera images showing the correct layout of a space ahead can be generated by purely listening to the reflections of chirping sounds. Many species evolved sophisticated non-visual perception while artificial systems fall behind. Radar and ultrasound are used where cameras fail, but provide very limited information or require large, complex and expensive sensors. Yet sound is used effortlessly by dolphins, bats, wales and humans as a sensor modality with many advantages over vision. However, it is challenging to harness useful and detailed information for machine perception. We train a network to generate representations of the world in 2D and 3D only from sounds, sent by one speaker and captured by two microphones. Inspired by examples from nature, we emit short frequency modulated sound chirps and record returning echoes through an artificial human pinnae pair. We then learn to generate disparity-like depth maps and grayscale images from the echoes in an end-to-end fashion. With only low-cost equipment, our models show good reconstruction performance while being robust to errors and even overcoming limitations of our vision-based ground truth. Finally, we introduce a large dataset consisting of binaural sound signals synchronised in time with both RGB images and depth maps.