Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonsense Scene Semantics for Cognitive Robotics: Towards Grounding Embodied Visuo-Locomotive Interactions
Paper and Code
Sep 15, 2017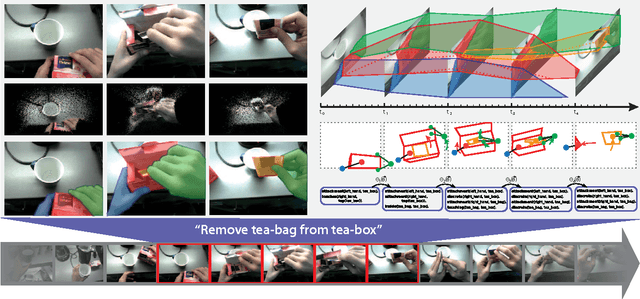



We present a commonsense, qualitative model for the semantic grounding of embodied visuo-spatial and locomotive interactions. The key contribution is an integrative methodology combining low-level visual processing with high-level, human-centred representations of space and motion rooted in artificial intelligence. We demonstrate practical applicability with examples involving object interactions, and indoor movement.
* to appear in: ICCV 2017 Workshop - Vision in Practice on Autonomous
Robots (ViPAR), International Conference on Computer Vision (ICCV), Venice,
Italy
View paper on