 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Object Localization on grocery shelves using simple FCN and Synthetic Dataset
Paper and Code
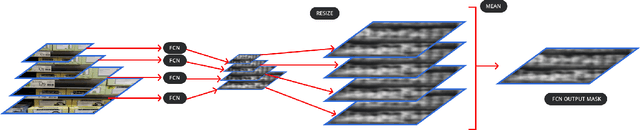



We propose a weakly supervised method using two algorithms to predict object bounding boxes given only an image classification dataset. First algorithm is a simple Fully Convolutional Network (FCN) trained to classify object instances. We use the property of FCN to return a mask for images larger than training images to get a primary output segmentation mask during test time by passing an image pyramid to it. We enhance the FCN output mask into final output bounding boxes by a Convolutional Encoder-Decoder (ConvAE) viz. the second algorithm. ConvAE is trained to localize objects on an artificially generated dataset of output segmentation masks. We demonstrate the effectiveness of this method in localizing objects in grocery shelves where annotating data for object detection is hard due to variety of objects. This method can be extended to any problem domain where collecting images of objects is easy and annotating their coordinates is hard.