 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Task-oriented Dialogue Systems: A Systematic Review of Measures, Constructs and their Operationalisations
Dec 21, 2023This review gives an extensive overview of evaluation methods for task-oriented dialogue systems, paying special attention to practical applications of dialogue systems, for example for customer service. The review (1) provides an overview of the used constructs and metrics in previous work, (2) discusses challenges in the context of dialogue system evaluation and (3) develops a research agenda for the future of dialogue system evaluation. We conducted a systematic review of four databases (ACL, ACM, IEEE and Web of Science), which after screening resulted in 122 studies. Those studies were carefully analysed for the constructs and methods they proposed for evaluation. We found a wide variety in both constructs and methods. Especially the operationalisation is not always clearly reported. We hope that future work will take a more critical approach to the operationalisation and specification of the used constructs. To work towards this aim, this review ends with recommendations for evaluation and suggestions for outstanding questions.
Neural Data-to-Text Generation Based on Small Datasets: Comparing the Added Value of Two Semi-Supervised Learning Approaches on Top of a Large Language Model
Jul 14, 2022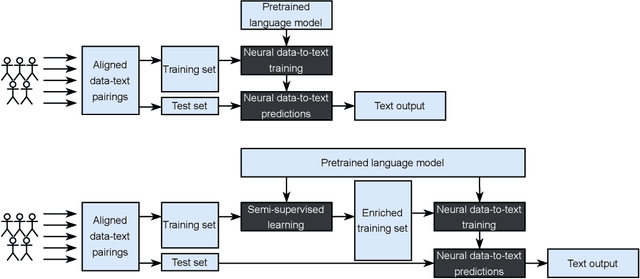
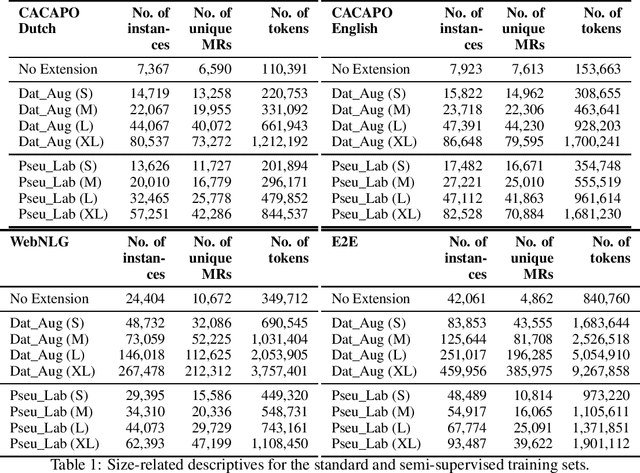
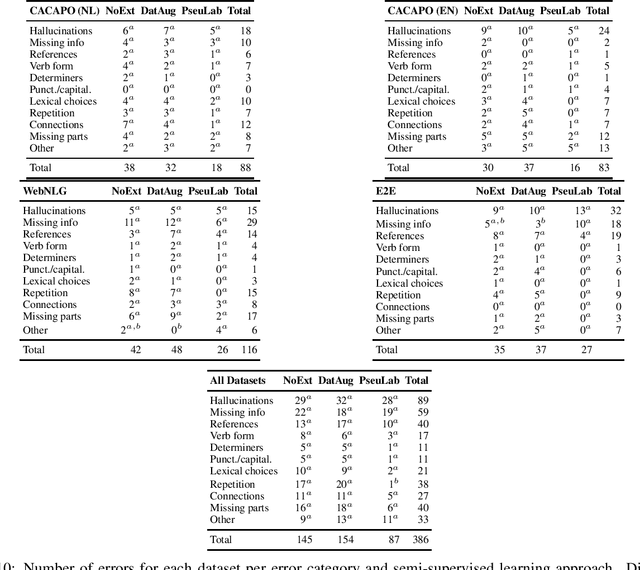
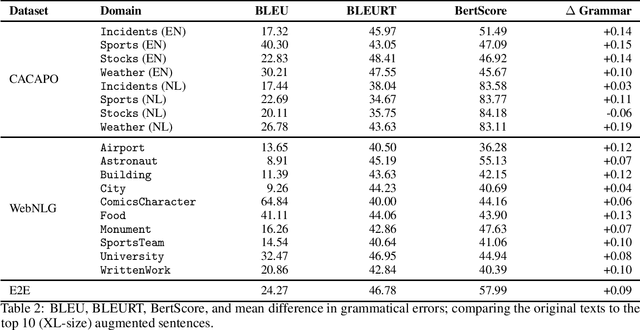
This study discusses the effect of semi-supervised learning in combination with pretrained language models for data-to-text generation. It is not known whether semi-supervised learning is still helpful when a large-scale language model is also supplemented. This study aims to answer this question by comparing a data-to-text system only supplemented with a language model, to two data-to-text systems that are additionally enriched by a data augmentation or a pseudo-labeling semi-supervised learning approach. Results show that semi-supervised learning results in higher scores on diversity metrics. In terms of output quality, extending the training set of a data-to-text system with a language model using the pseudo-labeling approach did increase text quality scores, but the data augmentation approach yielded similar scores to the system without training set extension. These results indicate that semi-supervised learning approaches can bolster output quality and diversity, even when a language model is also present.
Preregistering NLP Research
Mar 23, 2021


Preregistration refers to the practice of specifying what you are going to do, and what you expect to find in your study, before carrying out the study. This practice is increasingly common in medicine and psychology, but is rarely discussed in NLP. This paper discusses preregistration in more detail, explores how NLP researchers could preregister their work, and presents several preregistration questions for different kinds of studies. Finally, we argue in favour of registered reports, which could provide firmer grounds for slow science in NLP research. The goal of this paper is to elicit a discussion in the NLP community, which we hope to synthesise into a general NLP preregistration form in future research.
Neural data-to-text generation: A comparison between pipeline and end-to-end architectures
Aug 23, 2019
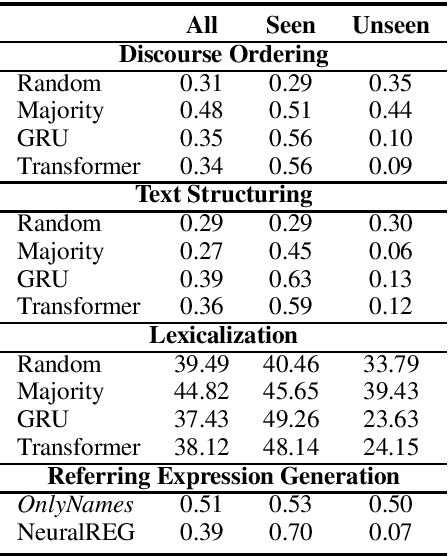
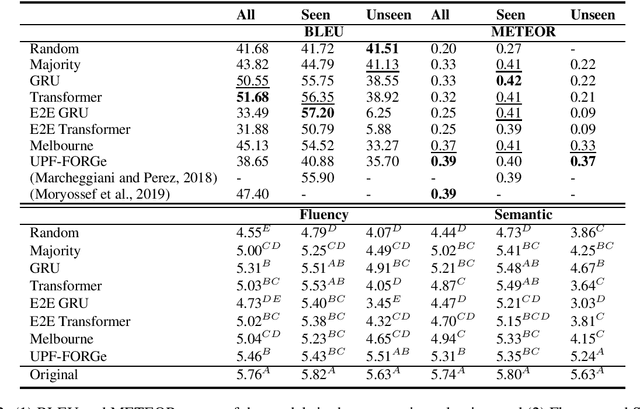

Traditionally, most data-to-text applications have been designed using a modular pipeline architecture, in which non-linguistic input data is converted into natural language through several intermediate transformations. In contrast, recent neural models for data-to-text generation have been proposed as end-to-end approaches, where the non-linguistic input is rendered in natural language with much less explicit intermediate representations in-between. This study introduces a systematic comparison between neural pipeline and end-to-end data-to-text approaches for the generation of text from RDF triples. Both architectures were implemented making use of state-of-the art deep learning methods as the encoder-decoder Gated-Recurrent Units (GRU) and Transformer. Automatic and human evaluations together with a qualitative analysis suggest that having explicit intermediate steps in the generation process results in better texts than the ones generated by end-to-end approaches. Moreover, the pipeline models generalize better to unseen inputs. Data and code are publicly available.
Making effective use of healthcare data using data-to-text technology
Aug 10, 2018
Healthcare organizations are in a continuous effort to improve health outcomes, reduce costs and enhance patient experience of care. Data is essential to measure and help achieving these improvements in healthcare delivery. Consequently, a data influx from various clinical, financial and operational sources is now overtaking healthcare organizations and their patients. The effective use of this data, however, is a major challenge. Clearly, text is an important medium to make data accessible. Financial reports are produced to assess healthcare organizations on some key performance indicators to steer their healthcare delivery. Similarly, at a clinical level, data on patient status is conveyed by means of textual descriptions to facilitate patient review, shift handover and care transitions. Likewise, patients are informed about data on their health status and treatments via text, in the form of reports or via ehealth platforms by their doctors. Unfortunately, such text is the outcome of a highly labour-intensive process if it is done by healthcare professionals. It is also prone to incompleteness, subjectivity and hard to scale up to different domains, wider audiences and varying communication purposes. Data-to-text is a recent breakthrough technology in artificial intelligence which automatically generates natural language in the form of text or speech from data. This chapter provides a survey of data-to-text technology, with a focus on how it can be deployed in a healthcare setting. It will (1) give an up-to-date synthesis of data-to-text approaches, (2) give a categorized overview of use cases in healthcare, (3) seek to make a strong case for evaluating and implementing data-to-text in a healthcare setting, and (4) highlight recent research challenges.
NeuralREG: An end-to-end approach to referring expression generation
May 21, 2018
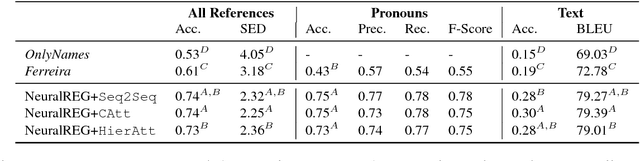

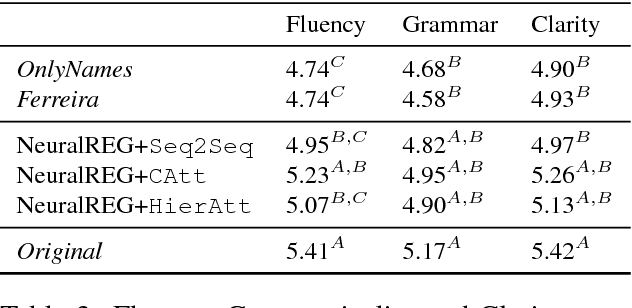
Traditionally, Referring Expression Generation (REG) models first decide on the form and then on the content of references to discourse entities in text, typically relying on features such as salience and grammatical function. In this paper, we present a new approach (NeuralREG), relying on deep neural networks, which makes decisions about form and content in one go without explicit feature extraction. Using a delexicalized version of the WebNLG corpus, we show that the neural model substantially improves over two strong baselines. Data and models are publicly available.
Survey of the State of the Art in Natural Language Generation: Core tasks, applications and evaluation
Jan 29, 2018
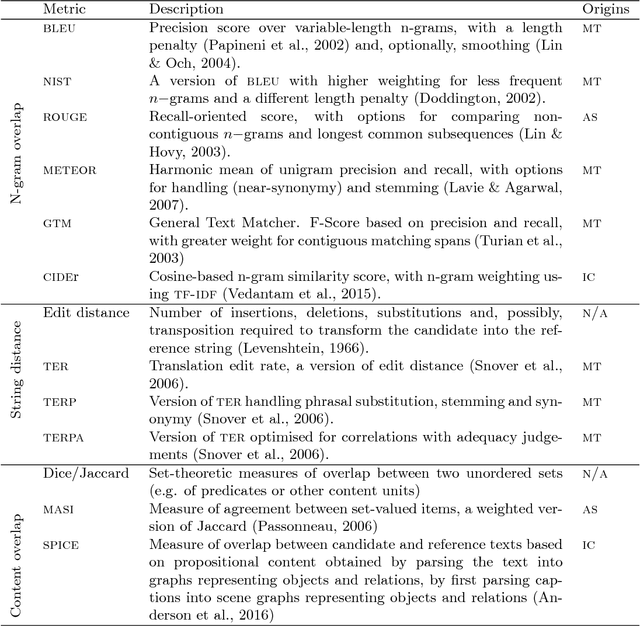


This paper surveys the current state of the art in Natural Language Generation (NLG), defined as the task of generating text or speech from non-linguistic input. A survey of NLG is timely in view of the changes that the field has undergone over the past decade or so, especially in relation to new (usually data-driven) methods, as well as new applications of NLG technology. This survey therefore aims to (a) give an up-to-date synthesis of research on the core tasks in NLG and the architectures adopted in which such tasks are organised; (b) highlight a number of relatively recent research topics that have arisen partly as a result of growing synergies between NLG and other areas of artificial intelligence; (c) draw attention to the challenges in NLG evaluation, relating them to similar challenges faced in other areas of Natural Language Processing, with an emphasis on different evaluation methods and the relationships between them.
* Published in Journal of AI Research (JAIR), volume 61, pp 75-170. 118 pages, 8 figures, 1 table