 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMissing Information, Unresponsive Authors, Experimental Flaws: The Impossibility of Assessing the Reproducibility of Previous Human Evaluations in NLP
May 02, 2023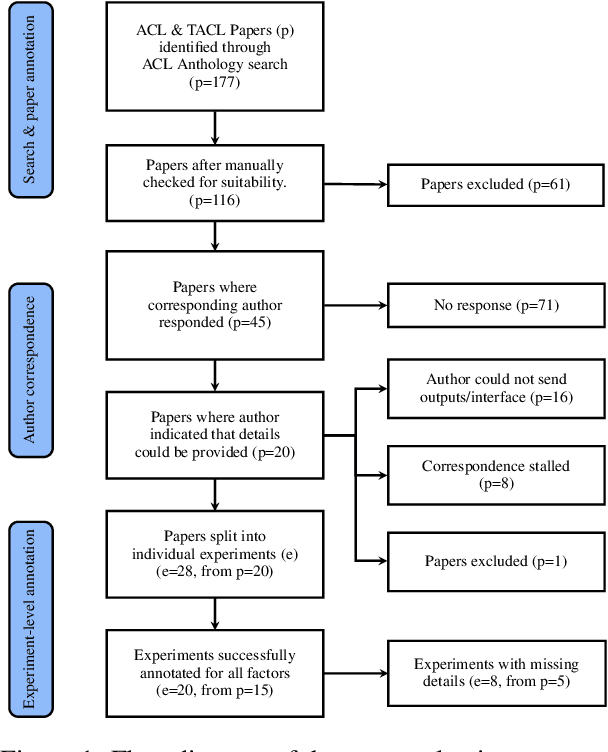


We report our efforts in identifying a set of previous human evaluations in NLP that would be suitable for a coordinated study examining what makes human evaluations in NLP more/less reproducible. We present our results and findings, which include that just 13\% of papers had (i) sufficiently low barriers to reproduction, and (ii) enough obtainable information, to be considered for reproduction, and that all but one of the experiments we selected for reproduction was discovered to have flaws that made the meaningfulness of conducting a reproduction questionable. As a result, we had to change our coordinated study design from a reproduce approach to a standardise-then-reproduce-twice approach. Our overall (negative) finding that the great majority of human evaluations in NLP is not repeatable and/or not reproducible and/or too flawed to justify reproduction, paints a dire picture, but presents an opportunity for a rethink about how to design and report human evaluations in NLP.
Neural Data-to-Text Generation Based on Small Datasets: Comparing the Added Value of Two Semi-Supervised Learning Approaches on Top of a Large Language Model
Jul 14, 2022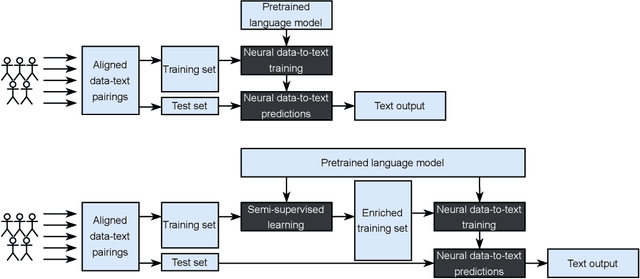
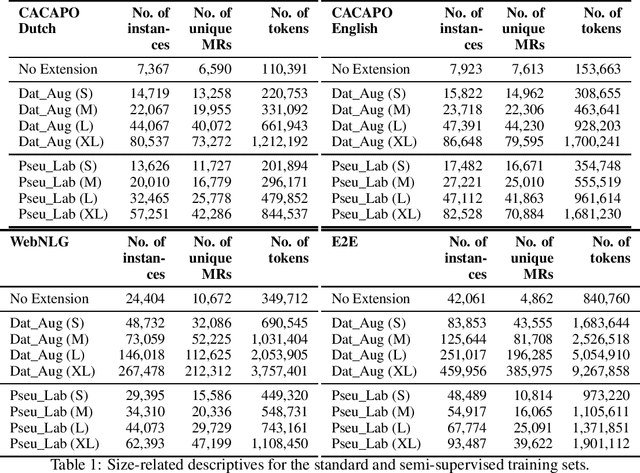
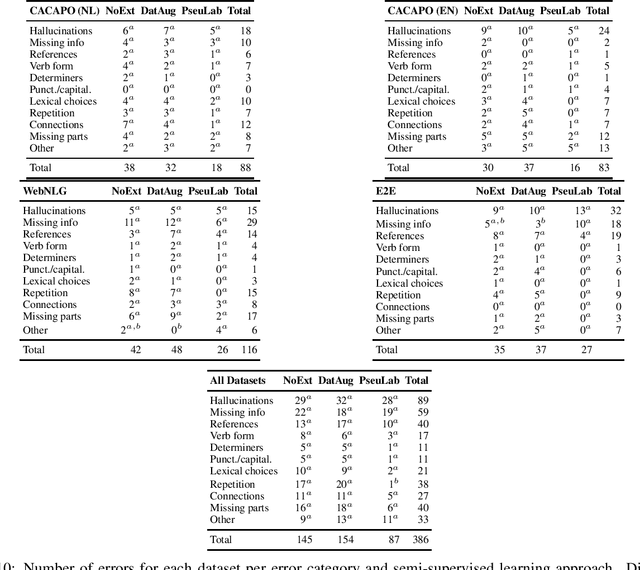
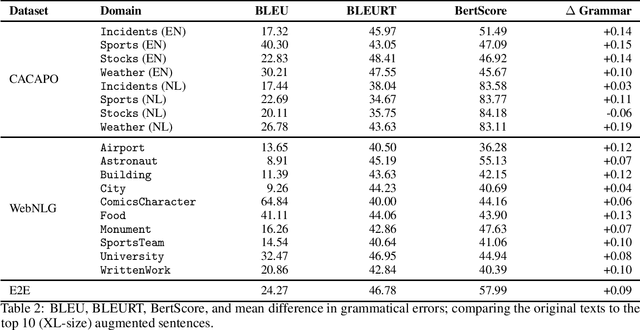
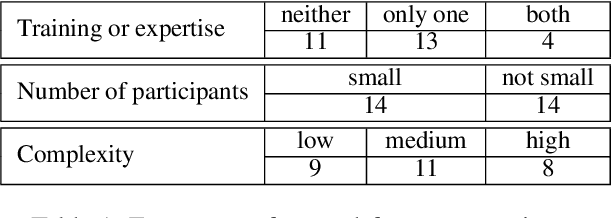
This study discusses the effect of semi-supervised learning in combination with pretrained language models for data-to-text generation. It is not known whether semi-supervised learning is still helpful when a large-scale language model is also supplemented. This study aims to answer this question by comparing a data-to-text system only supplemented with a language model, to two data-to-text systems that are additionally enriched by a data augmentation or a pseudo-labeling semi-supervised learning approach. Results show that semi-supervised learning results in higher scores on diversity metrics. In terms of output quality, extending the training set of a data-to-text system with a language model using the pseudo-labeling approach did increase text quality scores, but the data augmentation approach yielded similar scores to the system without training set extension. These results indicate that semi-supervised learning approaches can bolster output quality and diversity, even when a language model is also present.
Preregistering NLP Research
Mar 23, 2021


Preregistration refers to the practice of specifying what you are going to do, and what you expect to find in your study, before carrying out the study. This practice is increasingly common in medicine and psychology, but is rarely discussed in NLP. This paper discusses preregistration in more detail, explores how NLP researchers could preregister their work, and presents several preregistration questions for different kinds of studies. Finally, we argue in favour of registered reports, which could provide firmer grounds for slow science in NLP research. The goal of this paper is to elicit a discussion in the NLP community, which we hope to synthesise into a general NLP preregistration form in future research.
Neural data-to-text generation: A comparison between pipeline and end-to-end architectures
Aug 23, 2019
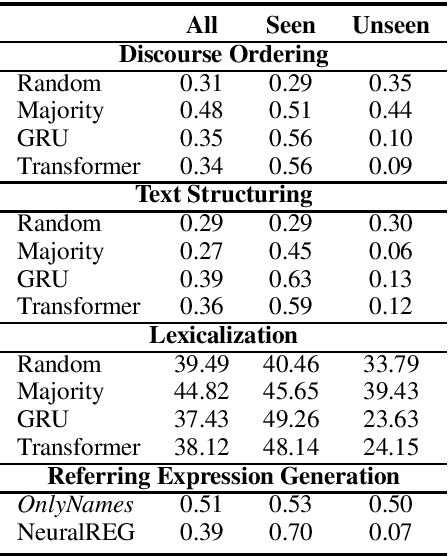
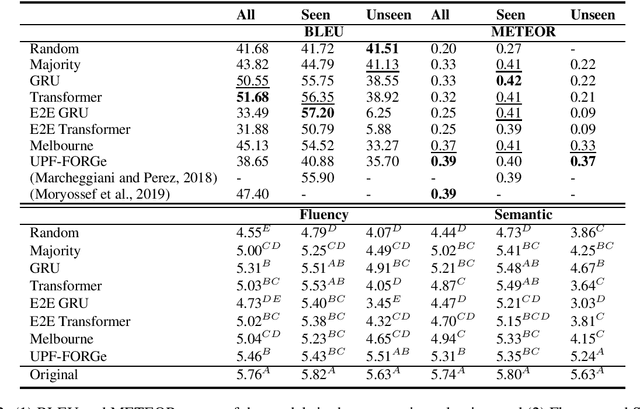

Traditionally, most data-to-text applications have been designed using a modular pipeline architecture, in which non-linguistic input data is converted into natural language through several intermediate transformations. In contrast, recent neural models for data-to-text generation have been proposed as end-to-end approaches, where the non-linguistic input is rendered in natural language with much less explicit intermediate representations in-between. This study introduces a systematic comparison between neural pipeline and end-to-end data-to-text approaches for the generation of text from RDF triples. Both architectures were implemented making use of state-of-the art deep learning methods as the encoder-decoder Gated-Recurrent Units (GRU) and Transformer. Automatic and human evaluations together with a qualitative analysis suggest that having explicit intermediate steps in the generation process results in better texts than the ones generated by end-to-end approaches. Moreover, the pipeline models generalize better to unseen inputs. Data and code are publicly available.