 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgelatrend: A Framework for Clustering Longitudinal Data
Feb 22, 2024Clustering of longitudinal data is used to explore common trends among subjects over time for a numeric measurement of interest. Various R packages have been introduced throughout the years for identifying clusters of longitudinal patterns, summarizing the variability in trajectories between subject in terms of one or more trends. We introduce the R package "latrend" as a framework for the unified application of methods for longitudinal clustering, enabling comparisons between methods with minimal coding. The package also serves as an interface to commonly used packages for clustering longitudinal data, including "dtwclust", "flexmix", "kml", "lcmm", "mclust", "mixAK", and "mixtools". This enables researchers to easily compare different approaches, implementations, and method specifications. Furthermore, researchers can build upon the standard tools provided by the framework to quickly implement new cluster methods, enabling rapid prototyping. We demonstrate the functionality and application of the latrend package on a synthetic dataset based on the therapy adherence patterns of patients with sleep apnea.
Clustering of longitudinal data: A tutorial on a variety of approaches
Nov 10, 2021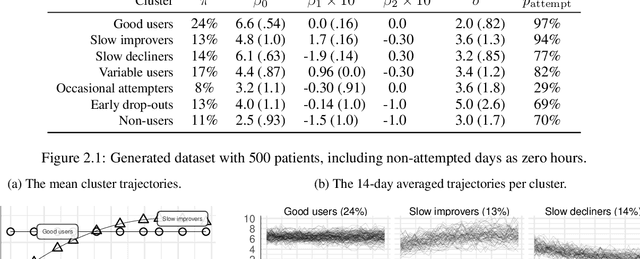
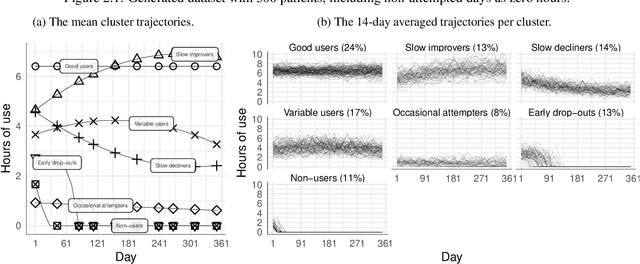
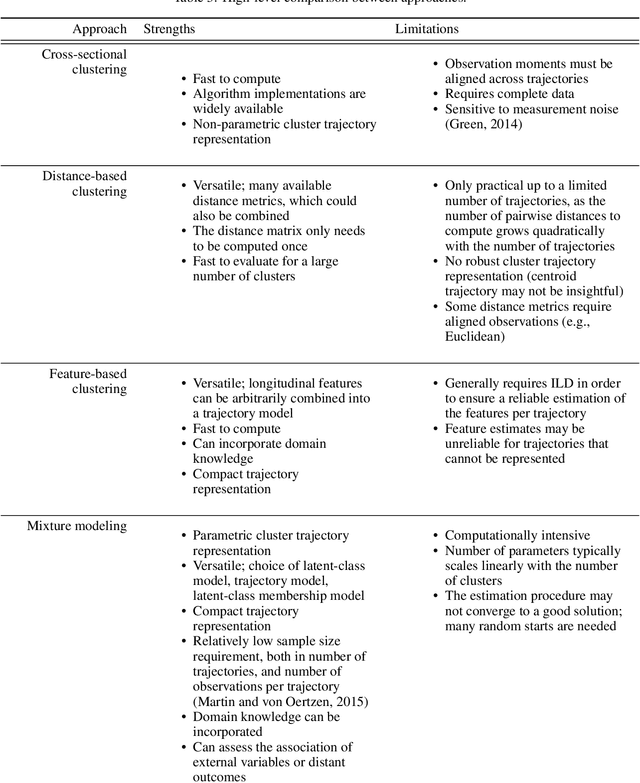
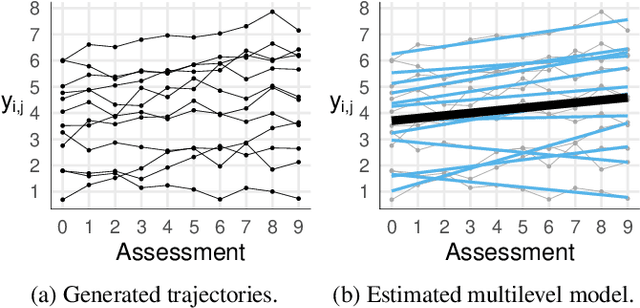
During the past two decades, methods for identifying groups with different trends in longitudinal data have become of increasing interest across many areas of research. To support researchers, we summarize the guidance from the literature regarding longitudinal clustering. Moreover, we present a selection of methods for longitudinal clustering, including group-based trajectory modeling (GBTM), growth mixture modeling (GMM), and longitudinal k-means (KML). The methods are introduced at a basic level, and strengths, limitations, and model extensions are listed. Following the recent developments in data collection, attention is given to the applicability of these methods to intensive longitudinal data (ILD). We demonstrate the application of the methods on a synthetic dataset using packages available in R.
Service Selection using Predictive Models and Monte-Carlo Tree Search
Feb 12, 2020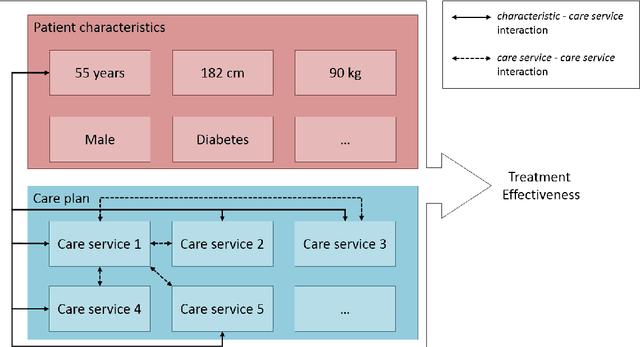

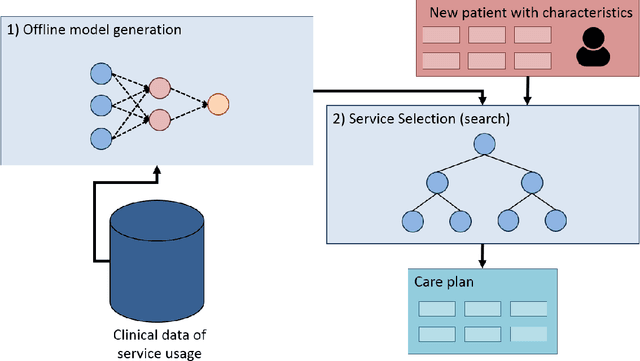

This article proposes a method for automated service selection to improve treatment efficacy and reduce re-hospitalization costs. A predictive model is developed using the National Home and Hospice Care Survey (NHHCS) dataset to quantify the effect of care services on the risk of re-hospitalization. By taking the patient's characteristics and other selected services into account, the model is able to indicate the overall effectiveness of a combination of services for a specific NHHCS patient. The developed model is incorporated in Monte-Carlo Tree Search (MCTS) to determine optimal combinations of services that minimize the risk of emergency re-hospitalization. MCTS serves as a risk minimization algorithm in this case, using the predictive model for guidance during the search. Using this method on the NHHCS dataset, a significant reduction in risk of re-hospitalization is observed compared to the original selections made by clinicians. An 11.89 percentage points risk reduction is achieved on average. Higher reductions of roughly 40 percentage points on average are observed for NHHCS patients in the highest risk categories. These results seem to indicate that there is enormous potential for improving service selection in the near future.
Making effective use of healthcare data using data-to-text technology
Aug 10, 2018
Healthcare organizations are in a continuous effort to improve health outcomes, reduce costs and enhance patient experience of care. Data is essential to measure and help achieving these improvements in healthcare delivery. Consequently, a data influx from various clinical, financial and operational sources is now overtaking healthcare organizations and their patients. The effective use of this data, however, is a major challenge. Clearly, text is an important medium to make data accessible. Financial reports are produced to assess healthcare organizations on some key performance indicators to steer their healthcare delivery. Similarly, at a clinical level, data on patient status is conveyed by means of textual descriptions to facilitate patient review, shift handover and care transitions. Likewise, patients are informed about data on their health status and treatments via text, in the form of reports or via ehealth platforms by their doctors. Unfortunately, such text is the outcome of a highly labour-intensive process if it is done by healthcare professionals. It is also prone to incompleteness, subjectivity and hard to scale up to different domains, wider audiences and varying communication purposes. Data-to-text is a recent breakthrough technology in artificial intelligence which automatically generates natural language in the form of text or speech from data. This chapter provides a survey of data-to-text technology, with a focus on how it can be deployed in a healthcare setting. It will (1) give an up-to-date synthesis of data-to-text approaches, (2) give a categorized overview of use cases in healthcare, (3) seek to make a strong case for evaluating and implementing data-to-text in a healthcare setting, and (4) highlight recent research challenges.