 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgelatrend: A Framework for Clustering Longitudinal Data
Feb 22, 2024Clustering of longitudinal data is used to explore common trends among subjects over time for a numeric measurement of interest. Various R packages have been introduced throughout the years for identifying clusters of longitudinal patterns, summarizing the variability in trajectories between subject in terms of one or more trends. We introduce the R package "latrend" as a framework for the unified application of methods for longitudinal clustering, enabling comparisons between methods with minimal coding. The package also serves as an interface to commonly used packages for clustering longitudinal data, including "dtwclust", "flexmix", "kml", "lcmm", "mclust", "mixAK", and "mixtools". This enables researchers to easily compare different approaches, implementations, and method specifications. Furthermore, researchers can build upon the standard tools provided by the framework to quickly implement new cluster methods, enabling rapid prototyping. We demonstrate the functionality and application of the latrend package on a synthetic dataset based on the therapy adherence patterns of patients with sleep apnea.
Clustering of longitudinal data: A tutorial on a variety of approaches
Nov 10, 2021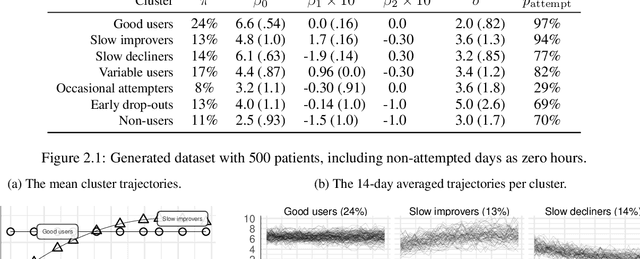
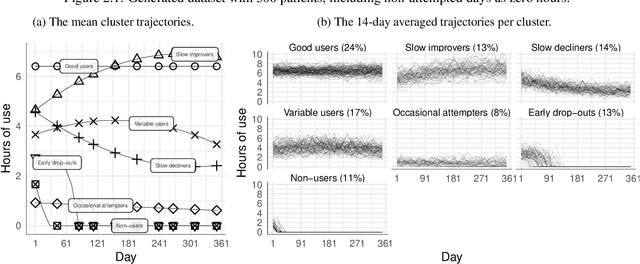
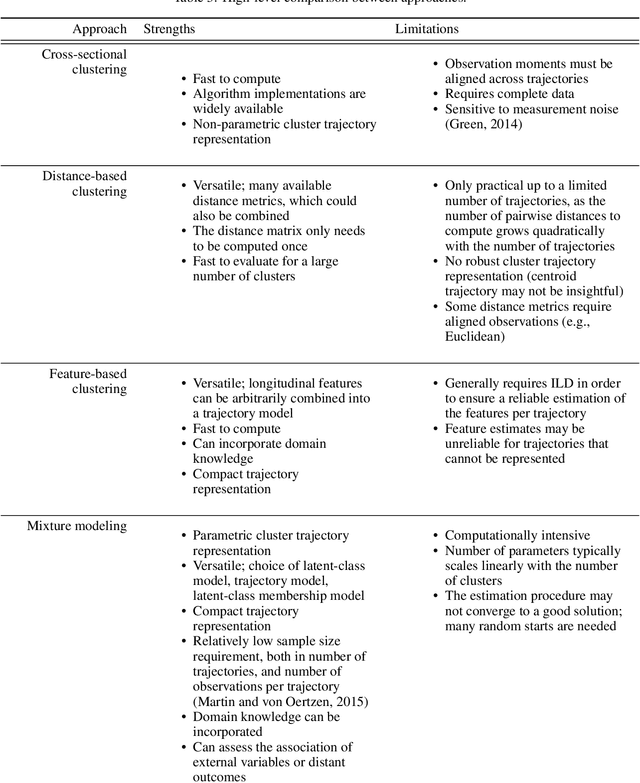
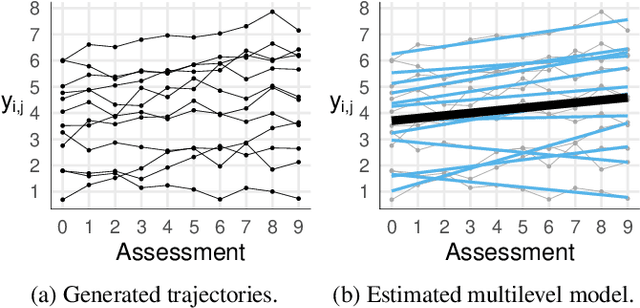
During the past two decades, methods for identifying groups with different trends in longitudinal data have become of increasing interest across many areas of research. To support researchers, we summarize the guidance from the literature regarding longitudinal clustering. Moreover, we present a selection of methods for longitudinal clustering, including group-based trajectory modeling (GBTM), growth mixture modeling (GMM), and longitudinal k-means (KML). The methods are introduced at a basic level, and strengths, limitations, and model extensions are listed. Following the recent developments in data collection, attention is given to the applicability of these methods to intensive longitudinal data (ILD). We demonstrate the application of the methods on a synthetic dataset using packages available in R.