 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward domain-specific machine translation and quality estimation systems
Mar 26, 2026Machine Translation (MT) and Quality Estimation (QE) perform well in general domains but degrade under domain mismatch. This dissertation studies how to adapt MT and QE systems to specialized domains through a set of data-focused contributions. Chapter 2 presents a similarity-based data selection method for MT. Small, targeted in-domain subsets outperform much larger generic datasets and reach strong translation quality at lower computational cost. Chapter 3 introduces a staged QE training pipeline that combines domain adaptation with lightweight data augmentation. The method improves performance across domains, languages, and resource settings, including zero-shot and cross-lingual cases. Chapter 4 studies the role of subword tokenization and vocabulary in fine-tuning. Aligned tokenization-vocabulary setups lead to stable training and better translation quality, while mismatched configurations reduce performance. Chapter 5 proposes a QE-guided in-context learning method for large language models. QE models select examples that improve translation quality without parameter updates and outperform standard retrieval methods. The approach also supports a reference-free setup, reducing reliance on a single reference set. These results show that domain adaptation depends on data selection, representation, and efficient adaptation strategies. The dissertation provides methods for building MT and QE systems that perform reliably in domain-specific settings.
Improving Medical Waste Classification with Hybrid Capsule Networks
Mar 13, 2025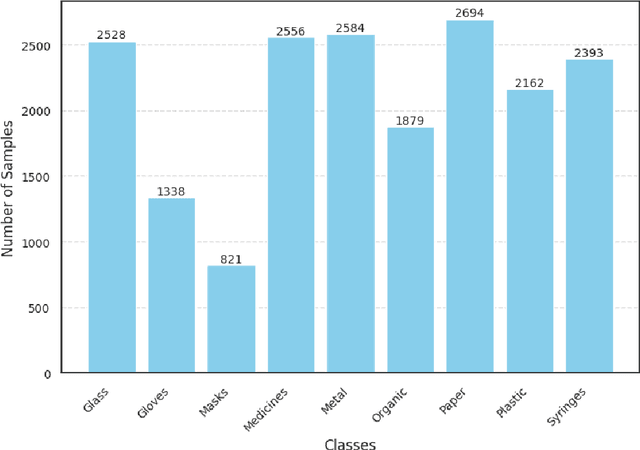
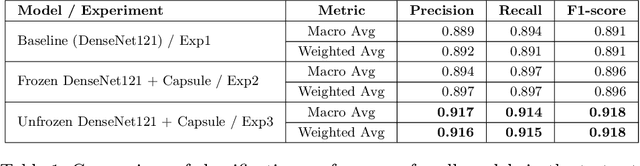
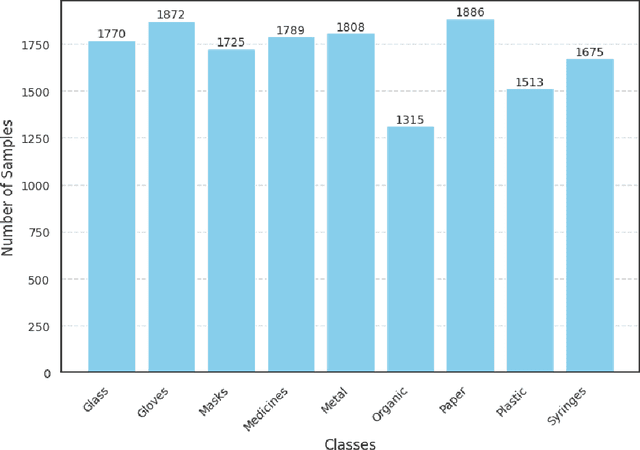
The improper disposal and mismanagement of medical waste pose severe environmental and public health risks, contributing to greenhouse gas emissions and the spread of infectious diseases. Efficient and accurate medical waste classification is crucial for mitigating these risks. We explore the integration of capsule networks with a pretrained DenseNet model to improve medical waste classification. To the best of our knowledge, capsule networks have not yet been applied to this task, making this study the first to assess their effectiveness. A diverse dataset of medical waste images collected from multiple public sources, is used to evaluate three model configurations: (1) a pretrained DenseNet model as a baseline, (2) a pretrained DenseNet with frozen layers combined with a capsule network, and (3) a pretrained DenseNet with unfrozen layers combined with a capsule network. Experimental results demonstrate that incorporating capsule networks improves classification performance, with F1 scores increasing from 0.89 (baseline) to 0.92 (hybrid model with unfrozen layers). This highlights the potential of capsule networks to address the spatial limitations of traditional convolutional models and improve classification robustness. While the capsule-enhanced model demonstrated improved classification performance, direct comparisons with prior studies were challenging due to differences in dataset size and diversity. Previous studies relied on smaller, domain-specific datasets, which inherently yielded higher accuracy. In contrast, our study employs a significantly larger and more diverse dataset, leading to better generalization but introducing additional classification challenges. This highlights the trade-off between dataset complexity and model performance.
Guiding In-Context Learning of LLMs through Quality Estimation for Machine Translation
Jun 12, 2024The quality of output from large language models (LLMs), particularly in machine translation (MT), is closely tied to the quality of in-context examples (ICEs) provided along with the query, i.e., the text to translate. The effectiveness of these ICEs is influenced by various factors, such as the domain of the source text, the order in which the ICEs are presented, the number of these examples, and the prompt templates used. Naturally, selecting the most impactful ICEs depends on understanding how these affect the resulting translation quality, which ultimately relies on translation references or human judgment. This paper presents a novel methodology for in-context learning (ICL) that relies on a search algorithm guided by domain-specific quality estimation (QE). Leveraging the XGLM model, our methodology estimates the resulting translation quality without the need for translation references, selecting effective ICEs for MT to maximize translation quality. Our results demonstrate significant improvements over existing ICL methods and higher translation performance compared to fine-tuning a pre-trained language model (PLM), specifically mBART-50.
Tailoring Domain Adaptation for Machine Translation Quality Estimation
Apr 18, 2023
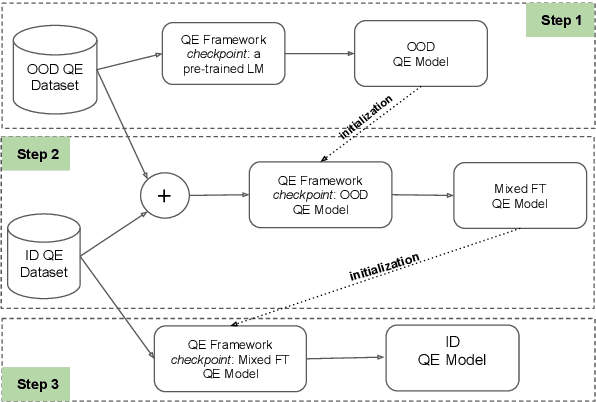


While quality estimation (QE) can play an important role in the translation process, its effectiveness relies on the availability and quality of training data. For QE in particular, high-quality labeled data is often lacking due to the high-cost and effort associated with labeling such data. Aside from the data scarcity challenge, QE models should also be generalizable, i.e., they should be able to handle data from different domains, both generic and specific. To alleviate these two main issues -- data scarcity and domain mismatch -- this paper combines domain adaptation and data augmentation within a robust QE system. Our method is to first train a generic QE model and then fine-tune it on a specific domain while retaining generic knowledge. Our results show a significant improvement for all the language pairs investigated, better cross-lingual inference, and a superior performance in zero-shot learning scenarios as compared to state-of-the-art baselines.
Evaluating the Effectiveness of Pre-trained Language Models in Predicting the Helpfulness of Online Product Reviews
Feb 19, 2023Businesses and customers can gain valuable information from product reviews. The sheer number of reviews often necessitates ranking them based on their potential helpfulness. However, only a few reviews ever receive any helpfulness votes on online marketplaces. Sorting all reviews based on the few existing votes can cause helpful reviews to go unnoticed because of the limited attention span of readers. The problem of review helpfulness prediction is even more important for higher review volumes, and newly written reviews or launched products. In this work we compare the use of RoBERTa and XLM-R language models to predict the helpfulness of online product reviews. The contributions of our work in relation to literature include extensively investigating the efficacy of state-of-the-art language models -- both monolingual and multilingual -- against a robust baseline, taking ranking metrics into account when assessing these approaches, and assessing multilingual models for the first time. We employ the Amazon review dataset for our experiments. According to our study on several product categories, multilingual and monolingual pre-trained language models outperform the baseline that utilizes random forest with handcrafted features as much as 23% in RMSE. Pre-trained language models reduce the need for complex text feature engineering. However, our results suggest that pre-trained multilingual models may not be used for fine-tuning only one language. We assess the performance of language models with and without additional features. Our results show that including additional features like product rating by the reviewer can further help the predictive methods.
Selecting Parallel In-domain Sentences for Neural Machine Translation Using Monolingual Texts
Dec 20, 2021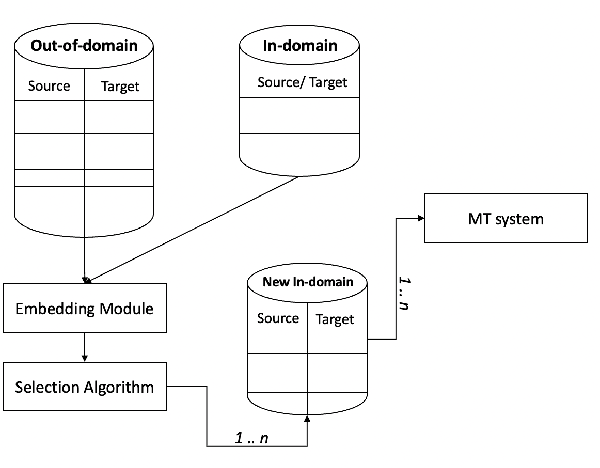

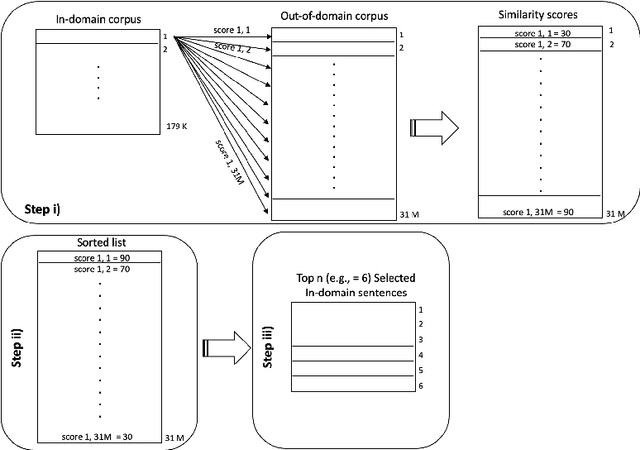

Continuously-growing data volumes lead to larger generic models. Specific use-cases are usually left out, since generic models tend to perform poorly in domain-specific cases. Our work addresses this gap with a method for selecting in-domain data from generic-domain (parallel text) corpora, for the task of machine translation. The proposed method ranks sentences in parallel general-domain data according to their cosine similarity with a monolingual domain-specific data set. We then select the top K sentences with the highest similarity score to train a new machine translation system tuned to the specific in-domain data. Our experimental results show that models trained on this in-domain data outperform models trained on generic or a mixture of generic and domain data. That is, our method selects high-quality domain-specific training instances at low computational cost and data size.