 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuAMR: A Hungarian AMR Parser and Dataset
Feb 27, 2025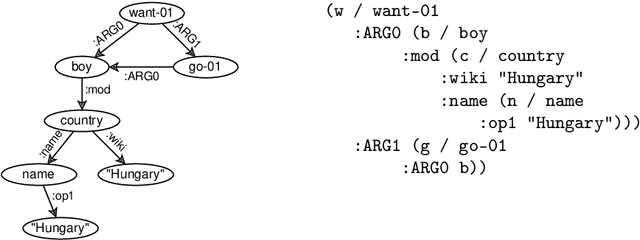
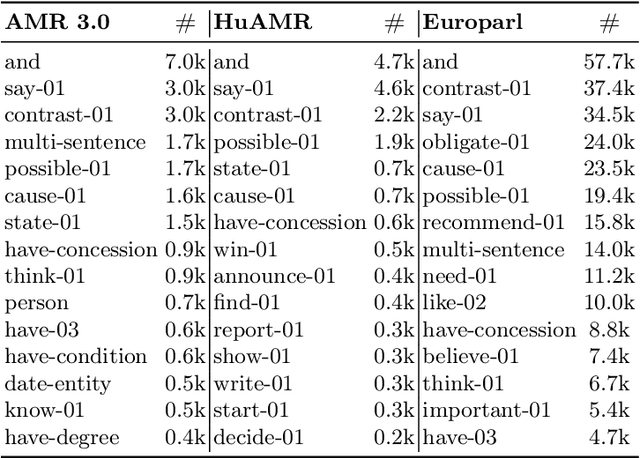
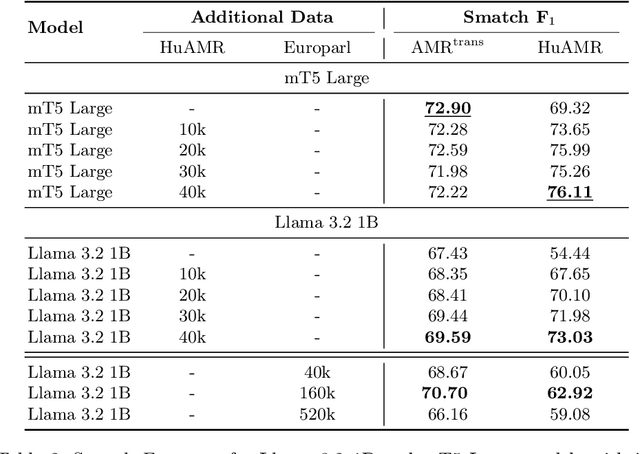
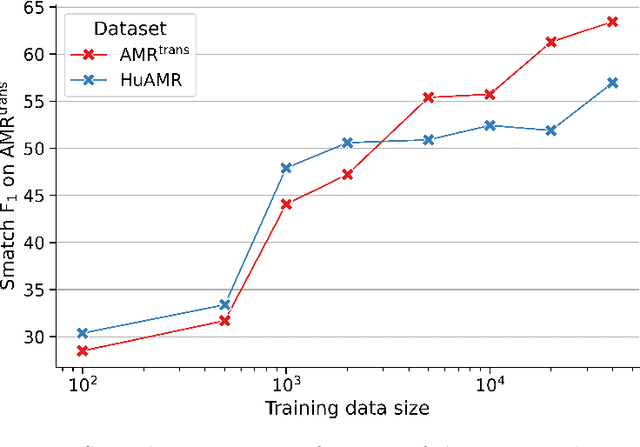
We present HuAMR, the first Abstract Meaning Representation (AMR) dataset and a suite of large language model-based AMR parsers for Hungarian, targeting the scarcity of semantic resources for non-English languages. To create HuAMR, we employed Llama-3.1-70B to automatically generate silver-standard AMR annotations, which we then refined manually to ensure quality. Building on this dataset, we investigate how different model architectures - mT5 Large and Llama-3.2-1B - and fine-tuning strategies affect AMR parsing performance. While incorporating silver-standard AMRs from Llama-3.1-70B into the training data of smaller models does not consistently boost overall scores, our results show that these techniques effectively enhance parsing accuracy on Hungarian news data (the domain of HuAMR). We evaluate our parsers using Smatch scores and confirm the potential of HuAMR and our parsers for advancing semantic parsing research.
All Languages Matter: Evaluating LMMs on Culturally Diverse 100 Languages
Nov 25, 2024



Existing Large Multimodal Models (LMMs) generally focus on only a few regions and languages. As LMMs continue to improve, it is increasingly important to ensure they understand cultural contexts, respect local sensitivities, and support low-resource languages, all while effectively integrating corresponding visual cues. In pursuit of culturally diverse global multimodal models, our proposed All Languages Matter Benchmark (ALM-bench) represents the largest and most comprehensive effort to date for evaluating LMMs across 100 languages. ALM-bench challenges existing models by testing their ability to understand and reason about culturally diverse images paired with text in various languages, including many low-resource languages traditionally underrepresented in LMM research. The benchmark offers a robust and nuanced evaluation framework featuring various question formats, including true/false, multiple choice, and open-ended questions, which are further divided into short and long-answer categories. ALM-bench design ensures a comprehensive assessment of a model's ability to handle varied levels of difficulty in visual and linguistic reasoning. To capture the rich tapestry of global cultures, ALM-bench carefully curates content from 13 distinct cultural aspects, ranging from traditions and rituals to famous personalities and celebrations. Through this, ALM-bench not only provides a rigorous testing ground for state-of-the-art open and closed-source LMMs but also highlights the importance of cultural and linguistic inclusivity, encouraging the development of models that can serve diverse global populations effectively. Our benchmark is publicly available.
Morphosyntactic probing of multilingual BERT models
Jun 09, 2023



We introduce an extensive dataset for multilingual probing of morphological information in language models (247 tasks across 42 languages from 10 families), each consisting of a sentence with a target word and a morphological tag as the desired label, derived from the Universal Dependencies treebanks. We find that pre-trained Transformer models (mBERT and XLM-RoBERTa) learn features that attain strong performance across these tasks. We then apply two methods to locate, for each probing task, where the disambiguating information resides in the input. The first is a new perturbation method that masks various parts of context; the second is the classical method of Shapley values. The most intriguing finding that emerges is a strong tendency for the preceding context to hold more information relevant to the prediction than the following context.
WikiGoldSK: Annotated Dataset, Baselines and Few-Shot Learning Experiments for Slovak Named Entity Recognition
Apr 08, 2023



Named Entity Recognition (NER) is a fundamental NLP tasks with a wide range of practical applications. The performance of state-of-the-art NER methods depends on high quality manually anotated datasets which still do not exist for some languages. In this work we aim to remedy this situation in Slovak by introducing WikiGoldSK, the first sizable human labelled Slovak NER dataset. We benchmark it by evaluating state-of-the-art multilingual Pretrained Language Models and comparing it to the existing silver-standard Slovak NER dataset. We also conduct few-shot experiments and show that training on a sliver-standard dataset yields better results. To enable future work that can be based on Slovak NER, we release the dataset, code, as well as the trained models publicly under permissible licensing terms at https://github.com/NaiveNeuron/WikiGoldSK.