 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphosyntactic probing of multilingual BERT models
Jun 09, 2023



We introduce an extensive dataset for multilingual probing of morphological information in language models (247 tasks across 42 languages from 10 families), each consisting of a sentence with a target word and a morphological tag as the desired label, derived from the Universal Dependencies treebanks. We find that pre-trained Transformer models (mBERT and XLM-RoBERTa) learn features that attain strong performance across these tasks. We then apply two methods to locate, for each probing task, where the disambiguating information resides in the input. The first is a new perturbation method that masks various parts of context; the second is the classical method of Shapley values. The most intriguing finding that emerges is a strong tendency for the preceding context to hold more information relevant to the prediction than the following context.
The Role of Interpretable Patterns in Deep Learning for Morphology
Dec 08, 2020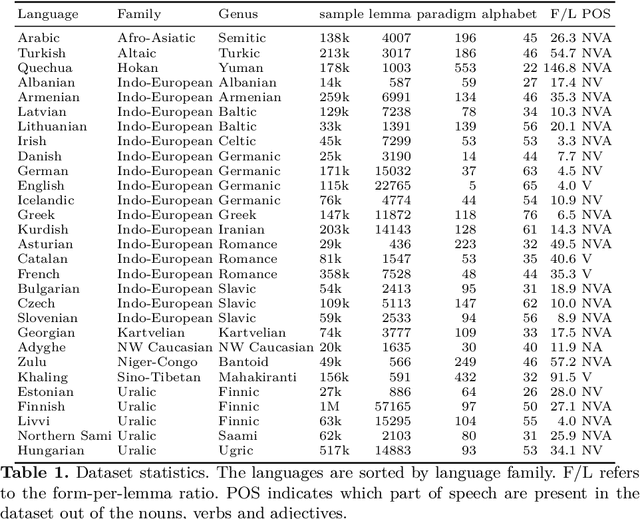
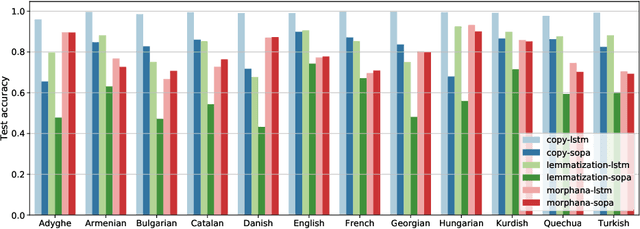
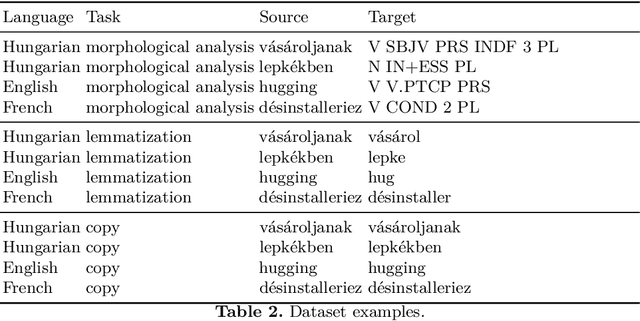

We examine the role of character patterns in three tasks: morphological analysis, lemmatization and copy. We use a modified version of the standard sequence-to-sequence model, where the encoder is a pattern matching network. Each pattern scores all possible N character long subwords (substrings) on the source side, and the highest scoring subword's score is used to initialize the decoder as well as the input to the attention mechanism. This method allows learning which subwords of the input are important for generating the output. By training the models on the same source but different target, we can compare what subwords are important for different tasks and how they relate to each other. We define a similarity metric, a generalized form of the Jaccard similarity, and assign a similarity score to each pair of the three tasks that work on the same source but may differ in target. We examine how these three tasks are related to each other in 12 languages. Our code is publicly available.
* Best paper at the Hungarian NLP conference (MSZNY2020)
Naive probability
May 20, 2019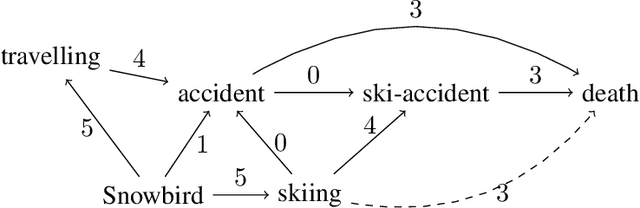

We describe a rational, but low resolution model of probability.