 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuAMR: A Hungarian AMR Parser and Dataset
Feb 27, 2025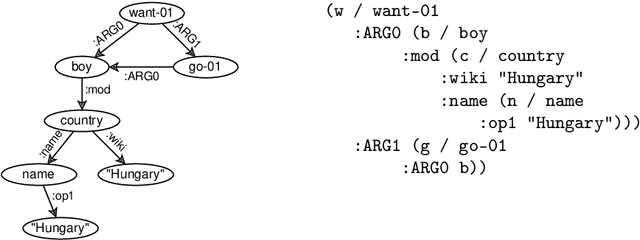
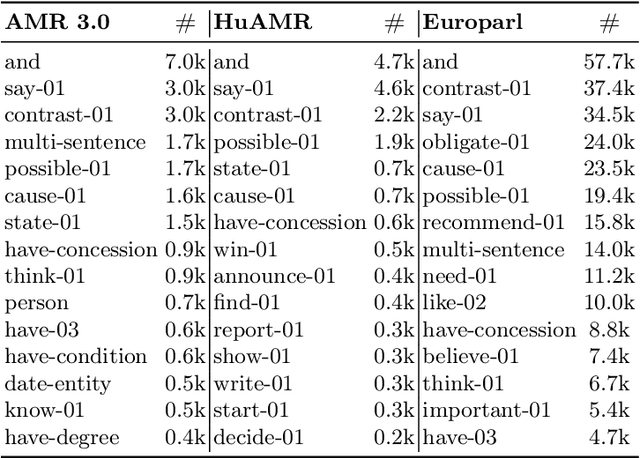
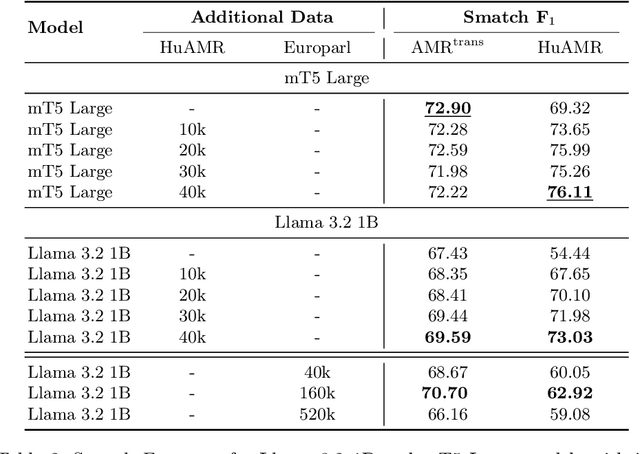
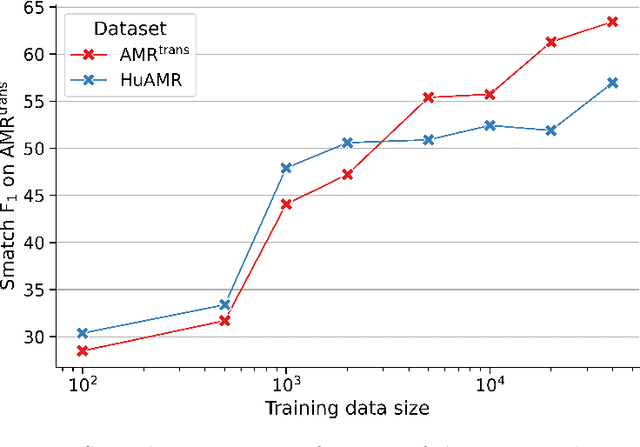
We present HuAMR, the first Abstract Meaning Representation (AMR) dataset and a suite of large language model-based AMR parsers for Hungarian, targeting the scarcity of semantic resources for non-English languages. To create HuAMR, we employed Llama-3.1-70B to automatically generate silver-standard AMR annotations, which we then refined manually to ensure quality. Building on this dataset, we investigate how different model architectures - mT5 Large and Llama-3.2-1B - and fine-tuning strategies affect AMR parsing performance. While incorporating silver-standard AMRs from Llama-3.1-70B into the training data of smaller models does not consistently boost overall scores, our results show that these techniques effectively enhance parsing accuracy on Hungarian news data (the domain of HuAMR). We evaluate our parsers using Smatch scores and confirm the potential of HuAMR and our parsers for advancing semantic parsing research.
From News to Summaries: Building a Hungarian Corpus for Extractive and Abstractive Summarization
Apr 12, 2024Training summarization models requires substantial amounts of training data. However for less resourceful languages like Hungarian, openly available models and datasets are notably scarce. To address this gap our paper introduces HunSum-2 an open-source Hungarian corpus suitable for training abstractive and extractive summarization models. The dataset is assembled from segments of the Common Crawl corpus undergoing thorough cleaning, preprocessing and deduplication. In addition to abstractive summarization we generate sentence-level labels for extractive summarization using sentence similarity. We train baseline models for both extractive and abstractive summarization using the collected dataset. To demonstrate the effectiveness of the trained models, we perform both quantitative and qualitative evaluation. Our dataset, models and code are publicly available, encouraging replication, further research, and real-world applications across various domains.
HunSum-1: an Abstractive Summarization Dataset for Hungarian
Feb 01, 2023



We introduce HunSum-1: a dataset for Hungarian abstractive summarization, consisting of 1.14M news articles. The dataset is built by collecting, cleaning and deduplicating data from 9 major Hungarian news sites through CommonCrawl. Using this dataset, we build abstractive summarizer models based on huBERT and mT5. We demonstrate the value of the created dataset by performing a quantitative and qualitative analysis on the models' results. The HunSum-1 dataset, all models used in our experiments and our code are available open source.