 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGender Dynamics and Homophily in a Social Network of LLM Agents
Feb 02, 2026Generative artificial intelligence and large language models (LLMs) are increasingly deployed in interactive settings, yet we know little about how their identity performance develops when they interact within large-scale networks. We address this by examining Chirper.ai, a social media platform similar to X but composed entirely of autonomous AI chatbots. Our dataset comprises over 70,000 agents, approximately 140 million posts, and the evolving followership network over one year. Based on agents' text production, we assign weekly gender scores to each agent. Results suggest that each agent's gender performance is fluid rather than fixed. Despite this fluidity, the network displays strong gender-based homophily, as agents consistently follow others performing gender similarly. Finally, we investigate whether these homophilic connections arise from social selection, in which agents choose to follow similar accounts, or from social influence, in which agents become more similar to their followees over time. Consistent with human social networks, we find evidence that both mechanisms shape the structure and evolution of interactions among LLMs. Our findings suggest that, even in the absence of bodies, cultural entraining of gender performance leads to gender-based sorting. This has important implications for LLM applications in synthetic hybrid populations, social simulations, and decision support.
Normative Equivalence in Human-AI Cooperation: Behaviour, Not Identity, Drives Cooperation in Mixed-Agent Groups
Jan 29, 2026The introduction of artificial intelligence (AI) agents into human group settings raises essential questions about how these novel participants influence cooperative social norms. While previous studies on human-AI cooperation have primarily focused on dyadic interactions, little is known about how integrating AI agents affects the emergence and maintenance of cooperative norms in small groups. This study addresses this gap through an online experiment using a repeated four-player Public Goods Game (PGG). Each group consisted of three human participants and one bot, which was framed either as human or AI and followed one of three predefined decision strategies: unconditional cooperation, conditional cooperation, or free-riding. In our sample of 236 participants, we found that reciprocal group dynamics and behavioural inertia primarily drove cooperation. These normative mechanisms operated identically across conditions, resulting in cooperation levels that did not differ significantly between human and AI labels. Furthermore, we found no evidence of differences in norm persistence in a follow-up Prisoner's Dilemma, or in participants' normative perceptions. Participants' behaviour followed the same normative logic across human and AI conditions, indicating that cooperation depended on group behaviour rather than partner identity. This supports a pattern of normative equivalence, in which the mechanisms that sustain cooperation function similarly in mixed human-AI and all human groups. These findings suggest that cooperative norms are flexible enough to extend to artificial agents, blurring the boundary between humans and AI in collective decision-making.
How Similar Are Grokipedia and Wikipedia? A Multi-Dimensional Textual and Structural Comparison
Nov 03, 2025
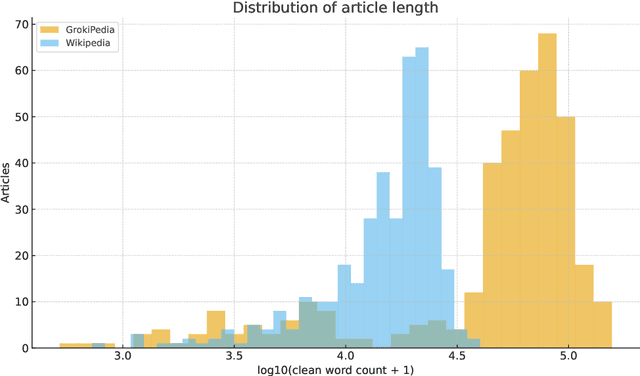


The launch of Grokipedia, an AI-generated encyclopedia developed by Elon Musk's xAI, was presented as a response to perceived ideological and structural biases in Wikipedia, aiming to produce "truthful" entries via the large language model Grok. Yet whether an AI-driven alternative can escape the biases and limitations of human-edited platforms remains unclear. This study undertakes a large-scale computational comparison of 1,800 matched article pairs between Grokipedia and Wikipedia, drawn from the 2,000 most-edited Wikipedia pages. Using metrics across lexical richness, readability, structural organization, reference density, and semantic similarity, we assess how closely the two platforms align in form and substance. The results show that while Grokipedia exhibits strong semantic and stylistic alignment with Wikipedia, it typically produces longer but less lexically diverse articles, with fewer references per word and greater structural variability. These findings suggest that AI-generated encyclopedic content currently mirrors Wikipedia's informational scope but diverges in editorial norms, favoring narrative expansion over citation-based verification. The implications highlight new tensions around transparency, provenance, and the governance of knowledge in an era of automated text generation.
AI's assigned gender affects human-AI cooperation
Dec 06, 2024Cooperation between humans and machines is increasingly vital as artificial intelligence (AI) becomes more integrated into daily life. Research indicates that people are often less willing to cooperate with AI agents than with humans, more readily exploiting AI for personal gain. While prior studies have shown that giving AI agents human-like features influences people's cooperation with them, the impact of AI's assigned gender remains underexplored. This study investigates how human cooperation varies based on gender labels assigned to AI agents with which they interact. In the Prisoner's Dilemma game, 402 participants interacted with partners labelled as AI (bot) or humans. The partners were also labelled male, female, non-binary, or gender-neutral. Results revealed that participants tended to exploit female-labelled and distrust male-labelled AI agents more than their human counterparts, reflecting gender biases similar to those in human-human interactions. These findings highlight the significance of gender biases in human-AI interactions that must be considered in future policy, design of interactive AI systems, and regulation of their use.
AI-enhanced Collective Intelligence: The State of the Art and Prospects
Mar 19, 2024The current societal challenges exceed the capacity of human individual or collective effort alone. As AI evolves, its role within human collectives is poised to vary from an assistive tool to a participatory member. Humans and AI possess complementary capabilities that, when synergized, can achieve a level of collective intelligence that surpasses the collective capabilities of either humans or AI in isolation. However, the interactions in human-AI systems are inherently complex, involving intricate processes and interdependencies. This review incorporates perspectives from network science to conceptualize a multilayer representation of human-AI collective intelligence, comprising a cognition layer, a physical layer, and an information layer. Within this multilayer network, humans and AI agents exhibit varying characteristics; humans differ in diversity from surface-level to deep-level attributes, while AI agents range in degrees of functionality and anthropomorphism. The interplay among these agents shapes the overall structure and dynamics of the system. We explore how agents' diversity and interactions influence the system's collective intelligence. Furthermore, we present an analysis of real-world instances of AI-enhanced collective intelligence. We conclude by addressing the potential challenges in AI-enhanced collective intelligence and offer perspectives on future developments in this field.
The Kaleidoscope of Privacy: Differences across French, German, UK, and US GDPR Media Discourse
Mar 31, 2021
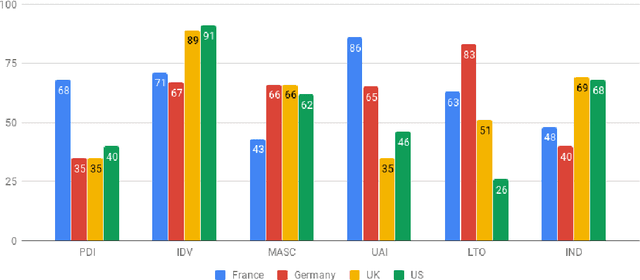
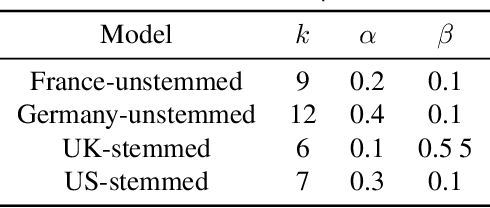
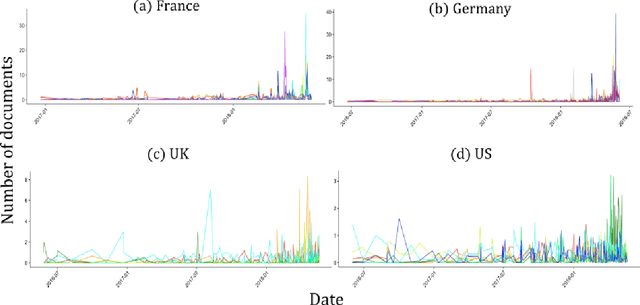
Conceptions of privacy differ by culture. In the Internet age, digital tools continuously challenge the way users, technologists, and governments define, value, and protect privacy. National and supranational entities attempt to regulate privacy and protect data managed online. The European Union passed the General Data Protection Regulation (GDPR), which took effect on 25 May 2018. The research presented here draws on two years of media reporting on GDPR from French, German, UK, and US sources. We use the unsupervised machine learning method of topic modelling to compare the thematic structure of the news articles across time and geographic regions. Our work emphasises the relevance of regional differences regarding valuations of privacy and potential obstacles to the implementation of unilateral data protection regulation such as GDPR. We find that the topics and trends over time in GDPR media coverage of the four countries reflect the differences found across their traditional privacy cultures.
Detecting weak and strong Islamophobic hate speech on social media
Dec 12, 2018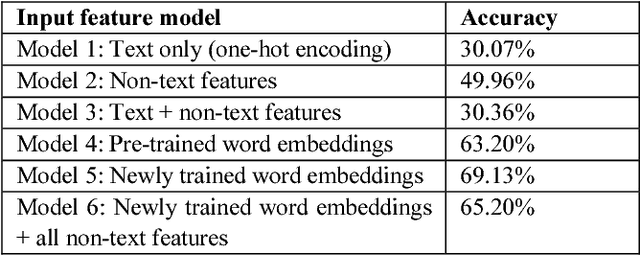

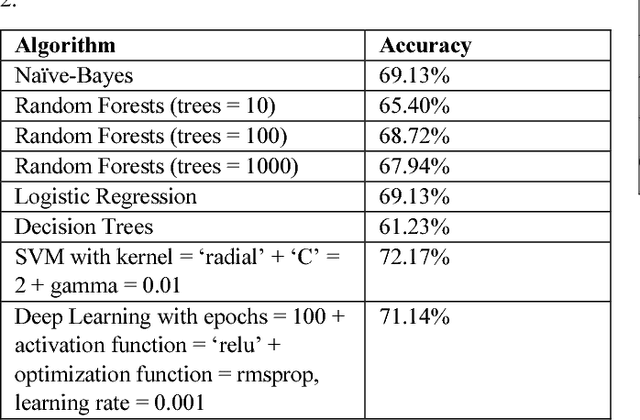
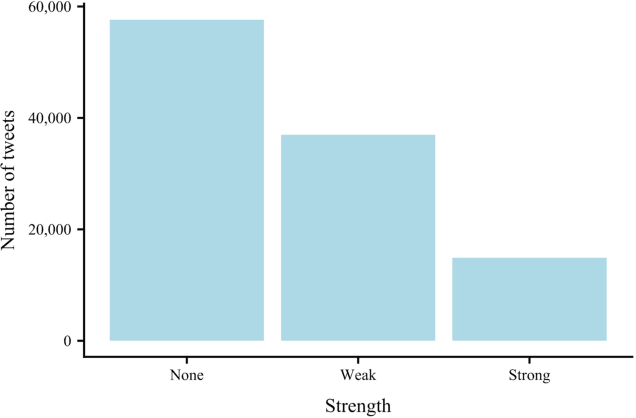
Islamophobic hate speech on social media inflicts considerable harm on both targeted individuals and wider society, and also risks reputational damage for the host platforms. Accordingly, there is a pressing need for robust tools to detect and classify Islamophobic hate speech at scale. Previous research has largely approached the detection of Islamophobic hate speech on social media as a binary task. However, the varied nature of Islamophobia means that this is often inappropriate for both theoretically-informed social science and effectively monitoring social media. Drawing on in-depth conceptual work we build a multi-class classifier which distinguishes between non-Islamophobic, weak Islamophobic and strong Islamophobic content. Accuracy is 77.6% and balanced accuracy is 83%. We apply the classifier to a dataset of 109,488 tweets produced by far right Twitter accounts during 2017. Whilst most tweets are not Islamophobic, weak Islamophobia is considerably more prevalent (36,963 tweets) than strong (14,895 tweets). Our main input feature is a gloVe word embeddings model trained on a newly collected corpus of 140 million tweets. It outperforms a generic word embeddings model by 5.9 percentage points, demonstrating the importan4ce of context. Unexpectedly, we also find that a one-against-one multi class SVM outperforms a deep learning algorithm.
Emo, Love, and God: Making Sense of Urban Dictionary, a Crowd-Sourced Online Dictionary
Apr 05, 2018
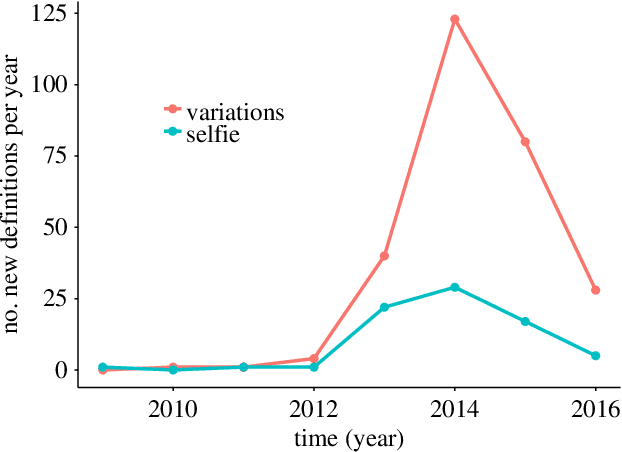

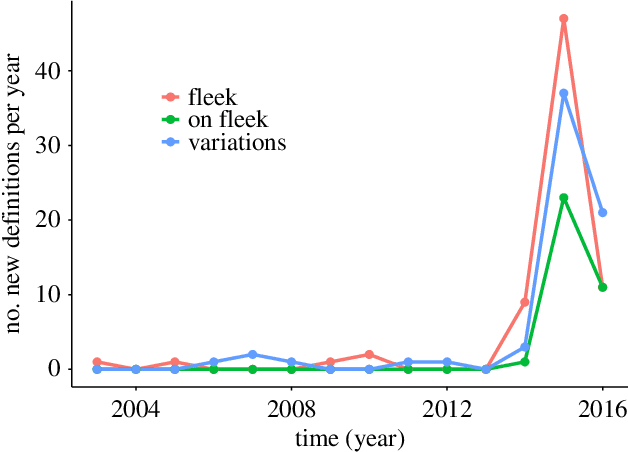
The Internet facilitates large-scale collaborative projects and the emergence of Web 2.0 platforms, where producers and consumers of content unify, has drastically changed the information market. On the one hand, the promise of the "wisdom of the crowd" has inspired successful projects such as Wikipedia, which has become the primary source of crowd-based information in many languages. On the other hand, the decentralized and often un-monitored environment of such projects may make them susceptible to low quality content. In this work, we focus on Urban Dictionary, a crowd-sourced online dictionary. We combine computational methods with qualitative annotation and shed light on the overall features of Urban Dictionary in terms of growth, coverage and types of content. We measure a high presence of opinion-focused entries, as opposed to the meaning-focused entries that we expect from traditional dictionaries. Furthermore, Urban Dictionary covers many informal, unfamiliar words as well as proper nouns. Urban Dictionary also contains offensive content, but highly offensive content tends to receive lower scores through the dictionary's voting system. The low threshold to include new material in Urban Dictionary enables quick recording of new words and new meanings, but the resulting heterogeneous content can pose challenges in using Urban Dictionary as a source to study language innovation.
The most controversial topics in Wikipedia: A multilingual and geographical analysis
Jul 08, 2013
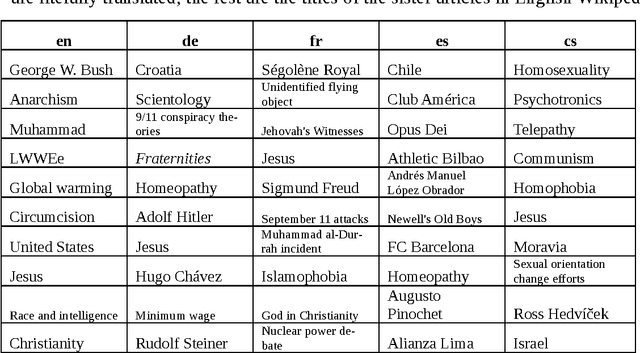
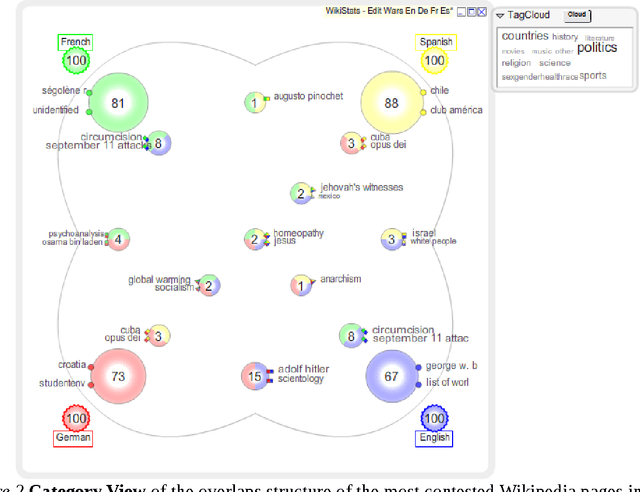
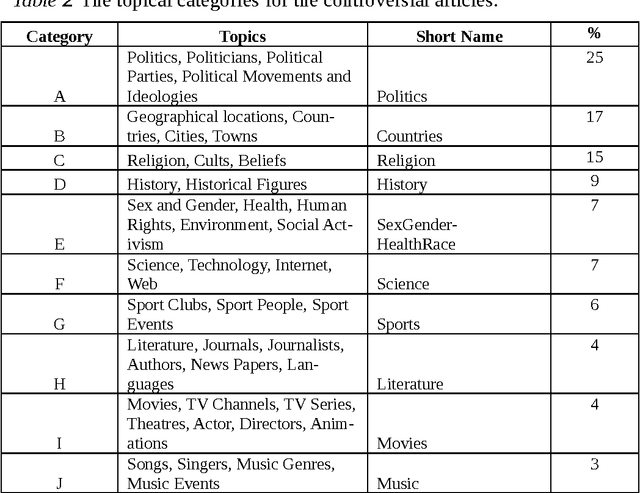
We present, visualize and analyse the similarities and differences between the controversial topics related to "edit wars" identified in 10 different language versions of Wikipedia. After a brief review of the related work we describe the methods developed to locate, measure, and categorize the controversial topics in the different languages. Visualizations of the degree of overlap between the top 100 lists of most controversial articles in different languages and the content related to geographical locations will be presented. We discuss what the presented analysis and visualizations can tell us about the multicultural aspects of Wikipedia and practices of peer-production. Our results indicate that Wikipedia is more than just an encyclopaedia; it is also a window into convergent and divergent social-spatial priorities, interests and preferences.
A practical approach to language complexity: a Wikipedia case study
Aug 18, 2012



In this paper we present statistical analysis of English texts from Wikipedia. We try to address the issue of language complexity empirically by comparing the simple English Wikipedia (Simple) to comparable samples of the main English Wikipedia (Main). Simple is supposed to use a more simplified language with a limited vocabulary, and editors are explicitly requested to follow this guideline, yet in practice the vocabulary richness of both samples are at the same level. Detailed analysis of longer units (n-grams of words and part of speech tags) shows that the language of Simple is less complex than that of Main primarily due to the use of shorter sentences, as opposed to drastically simplified syntax or vocabulary. Comparing the two language varieties by the Gunning readability index supports this conclusion. We also report on the topical dependence of language complexity, e.g. that the language is more advanced in conceptual articles compared to person-based (biographical) and object-based articles. Finally, we investigate the relation between conflict and language complexity by analyzing the content of the talk pages associated to controversial and peacefully developing articles, concluding that controversy has the effect of reducing language complexity.
* 2 new figures, 1 new section, and 2 new supporting texts