 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI and the Future of Work in Africa White Paper
Nov 15, 2024
This white paper is the output of a multidisciplinary workshop in Nairobi (Nov 2023). Led by a cross-organisational team including Microsoft Research, NEPAD, Lelapa AI, and University of Oxford. The workshop brought together diverse thought-leaders from various sectors and backgrounds to discuss the implications of Generative AI for the future of work in Africa. Discussions centred around four key themes: Macroeconomic Impacts; Jobs, Skills and Labour Markets; Workers' Perspectives and Africa-Centris AI Platforms. The white paper provides an overview of the current state and trends of generative AI and its applications in different domains, as well as the challenges and risks associated with its adoption and regulation. It represents a diverse set of perspectives to create a set of insights and recommendations which aim to encourage debate and collaborative action towards creating a dignified future of work for everyone across Africa.
Neuromorphologicaly-preserving Volumetric data encoding using VQ-VAE
Feb 13, 2020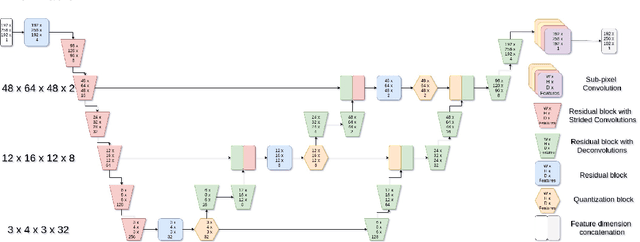
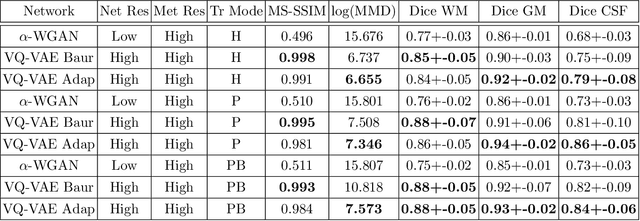
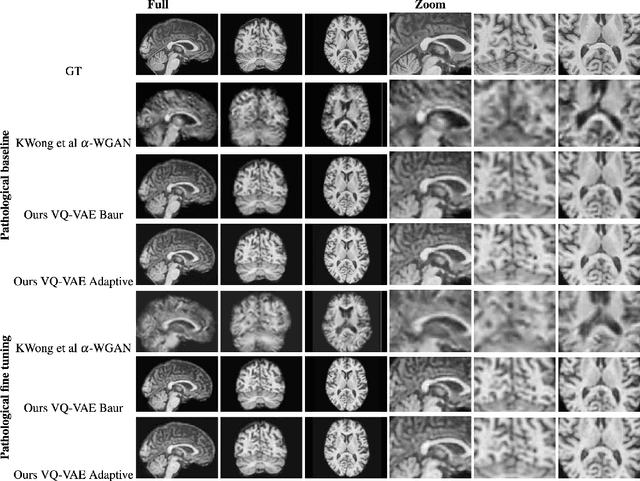
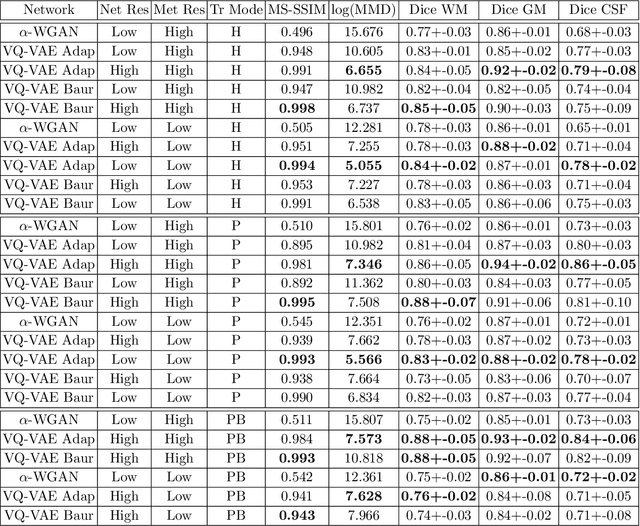
The increasing efficiency and compactness of deep learning architectures, together with hardware improvements, have enabled the complex and high-dimensional modelling of medical volumetric data at higher resolutions. Recently, Vector-Quantised Variational Autoencoders (VQ-VAE) have been proposed as an efficient generative unsupervised learning approach that can encode images to a small percentage of their initial size, while preserving their decoded fidelity. Here, we show a VQ-VAE inspired network can efficiently encode a full-resolution 3D brain volume, compressing the data to $0.825\%$ of the original size while maintaining image fidelity, and significantly outperforming the previous state-of-the-art. We then demonstrate that VQ-VAE decoded images preserve the morphological characteristics of the original data through voxel-based morphology and segmentation experiments. Lastly, we show that such models can be pre-trained and then fine-tuned on different datasets without the introduction of bias.
The most controversial topics in Wikipedia: A multilingual and geographical analysis
Jul 08, 2013
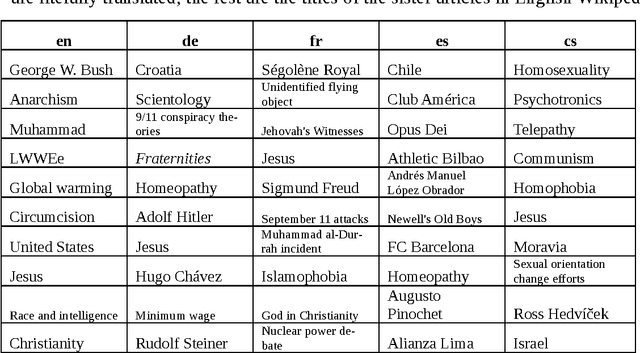
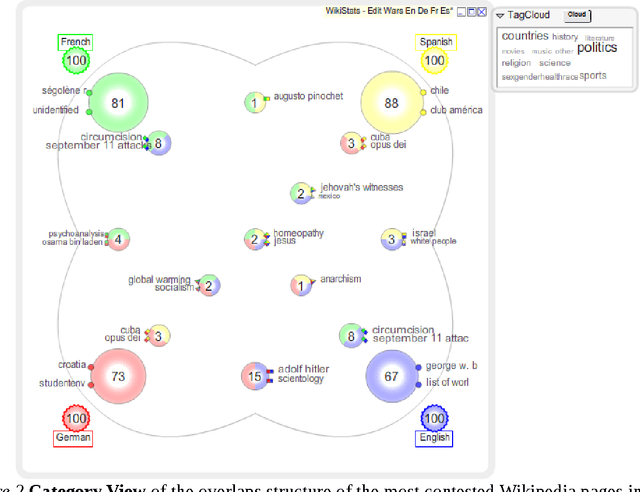
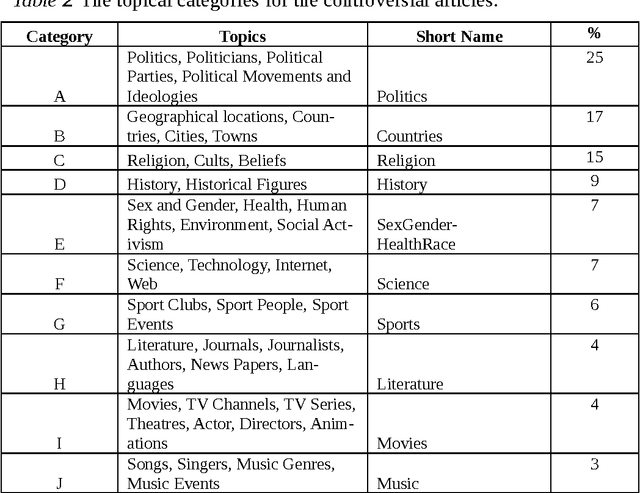
We present, visualize and analyse the similarities and differences between the controversial topics related to "edit wars" identified in 10 different language versions of Wikipedia. After a brief review of the related work we describe the methods developed to locate, measure, and categorize the controversial topics in the different languages. Visualizations of the degree of overlap between the top 100 lists of most controversial articles in different languages and the content related to geographical locations will be presented. We discuss what the presented analysis and visualizations can tell us about the multicultural aspects of Wikipedia and practices of peer-production. Our results indicate that Wikipedia is more than just an encyclopaedia; it is also a window into convergent and divergent social-spatial priorities, interests and preferences.