 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuromorphologicaly-preserving Volumetric data encoding using VQ-VAE
Paper and Code
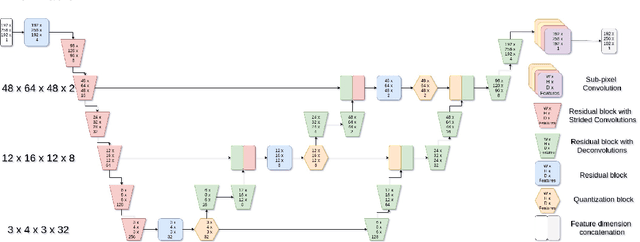
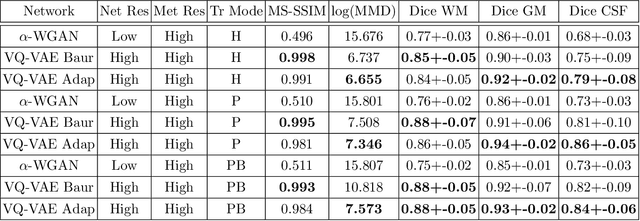
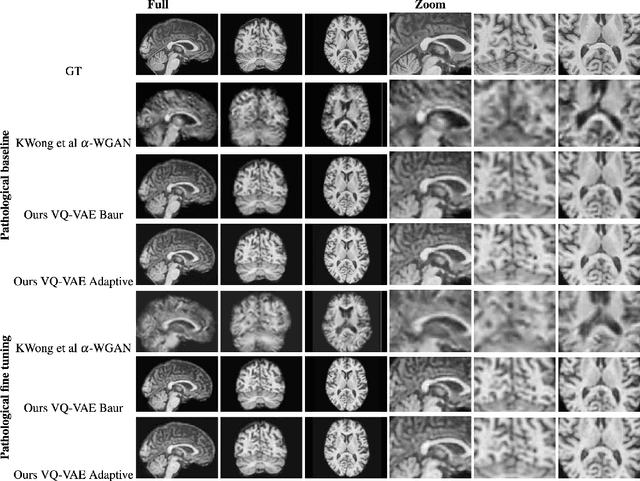
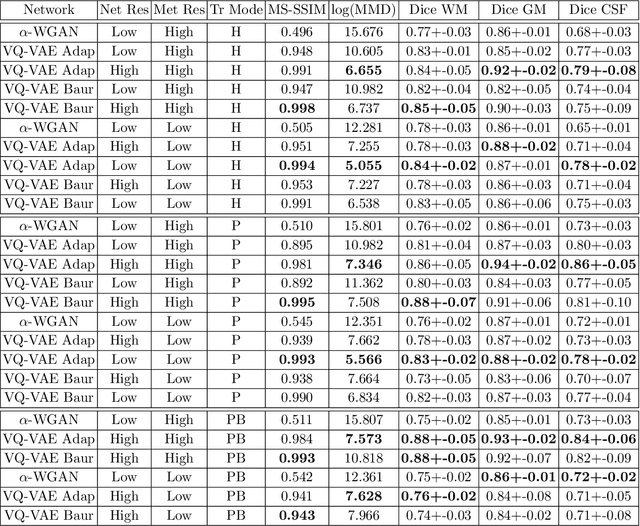
The increasing efficiency and compactness of deep learning architectures, together with hardware improvements, have enabled the complex and high-dimensional modelling of medical volumetric data at higher resolutions. Recently, Vector-Quantised Variational Autoencoders (VQ-VAE) have been proposed as an efficient generative unsupervised learning approach that can encode images to a small percentage of their initial size, while preserving their decoded fidelity. Here, we show a VQ-VAE inspired network can efficiently encode a full-resolution 3D brain volume, compressing the data to $0.825\%$ of the original size while maintaining image fidelity, and significantly outperforming the previous state-of-the-art. We then demonstrate that VQ-VAE decoded images preserve the morphological characteristics of the original data through voxel-based morphology and segmentation experiments. Lastly, we show that such models can be pre-trained and then fine-tuned on different datasets without the introduction of bias.