 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible visual prompts for in-context learning in computer vision
Dec 11, 2023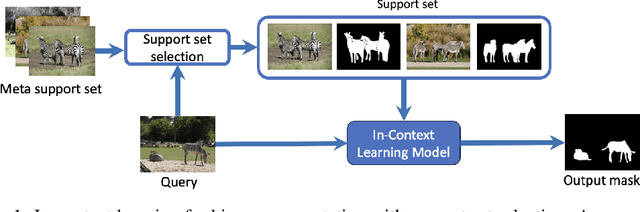
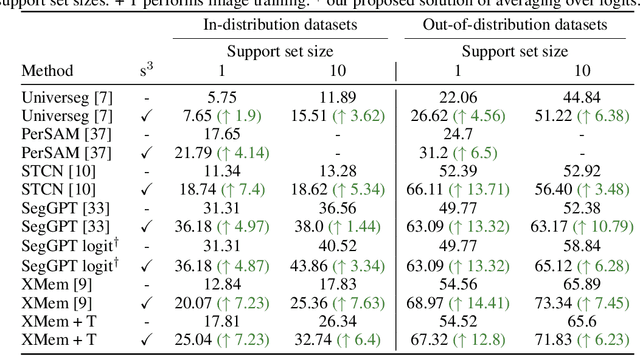

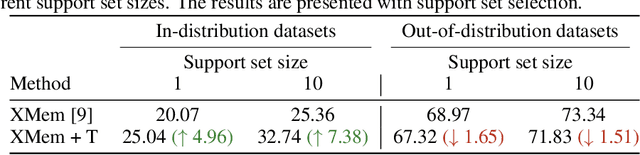
In this work, we address in-context learning (ICL) for the task of image segmentation, introducing a novel approach that adapts a modern Video Object Segmentation (VOS) technique for visual in-context learning. This adaptation is inspired by the VOS method's ability to efficiently and flexibly learn objects from a few examples. Through evaluations across a range of support set sizes and on diverse segmentation datasets, our method consistently surpasses existing techniques. Notably, it excels with data containing classes not encountered during training. Additionally, we propose a technique for support set selection, which involves choosing the most relevant images to include in this set. By employing support set selection, the performance increases for all tested methods without the need for additional training or prompt tuning. The code can be found at https://github.com/v7labs/XMem_ICL/.
Augmentation based unsupervised domain adaptation
Feb 23, 2022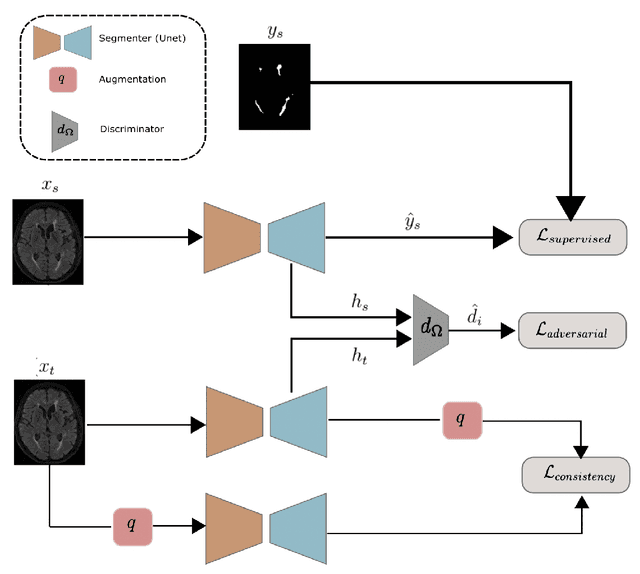

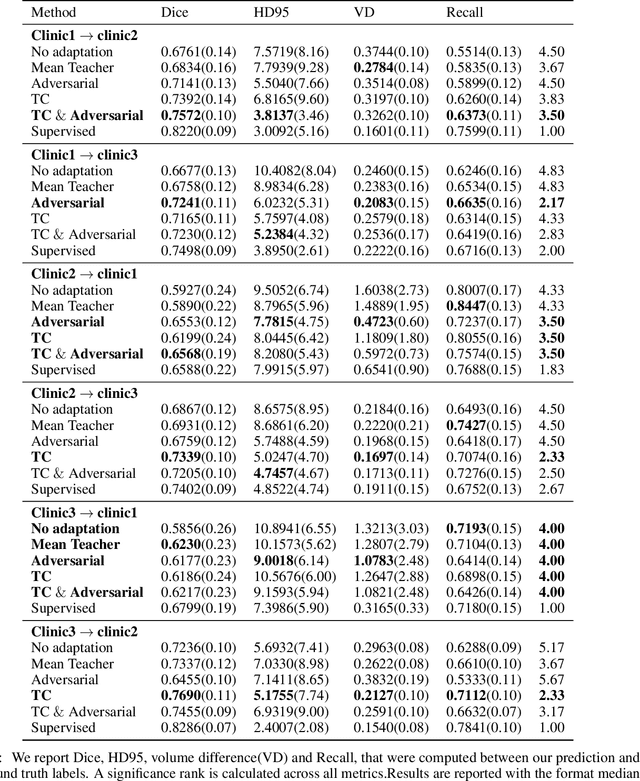
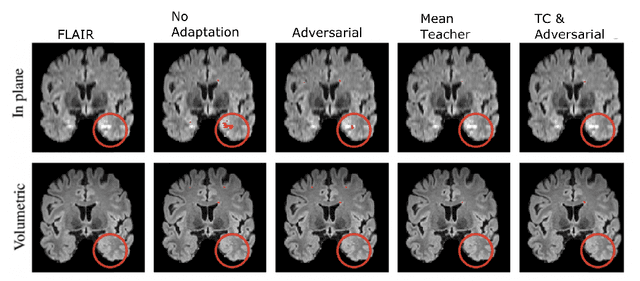
The insertion of deep learning in medical image analysis had lead to the development of state-of-the art strategies in several applications such a disease classification, as well as abnormality detection and segmentation. However, even the most advanced methods require a huge and diverse amount of data to generalize. Because in realistic clinical scenarios, data acquisition and annotation is expensive, deep learning models trained on small and unrepresentative data tend to outperform when deployed in data that differs from the one used for training (e.g data from different scanners). In this work, we proposed a domain adaptation methodology to alleviate this problem in segmentation models. Our approach takes advantage of the properties of adversarial domain adaptation and consistency training to achieve more robust adaptation. Using two datasets with white matter hyperintensities (WMH) annotations, we demonstrated that the proposed method improves model generalization even in corner cases where individual strategies tend to fail.
Acquisition-invariant brain MRI segmentation with informative uncertainties
Nov 07, 2021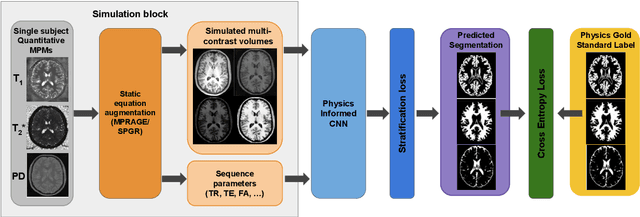
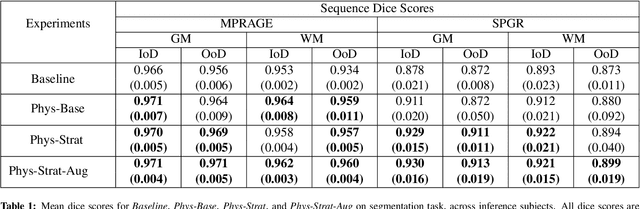
Combining multi-site data can strengthen and uncover trends, but is a task that is marred by the influence of site-specific covariates that can bias the data and therefore any downstream analyses. Post-hoc multi-site correction methods exist but have strong assumptions that often do not hold in real-world scenarios. Algorithms should be designed in a way that can account for site-specific effects, such as those that arise from sequence parameter choices, and in instances where generalisation fails, should be able to identify such a failure by means of explicit uncertainty modelling. This body of work showcases such an algorithm, that can become robust to the physics of acquisition in the context of segmentation tasks, while simultaneously modelling uncertainty. We demonstrate that our method not only generalises to complete holdout datasets, preserving segmentation quality, but does so while also accounting for site-specific sequence choices, which also allows it to perform as a harmonisation tool.
The role of MRI physics in brain segmentation CNNs: achieving acquisition invariance and instructive uncertainties
Nov 04, 2021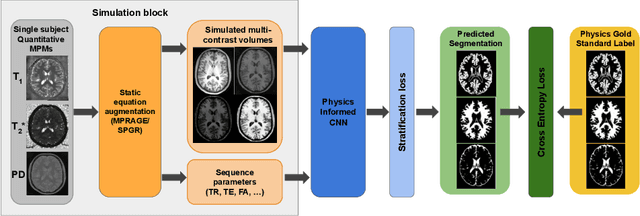
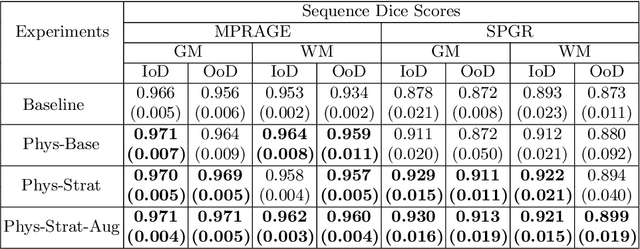
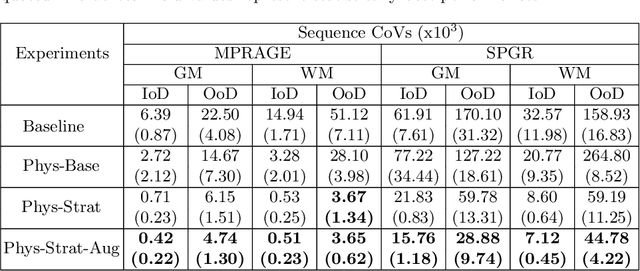
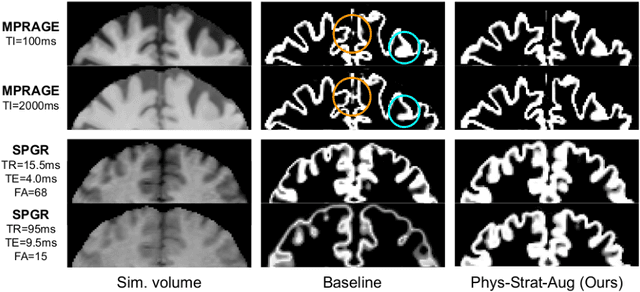
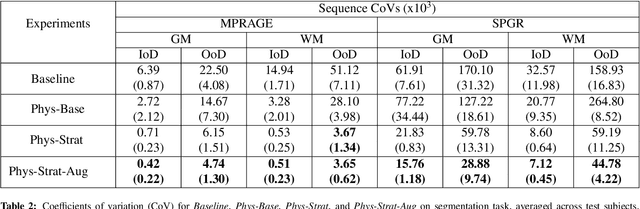
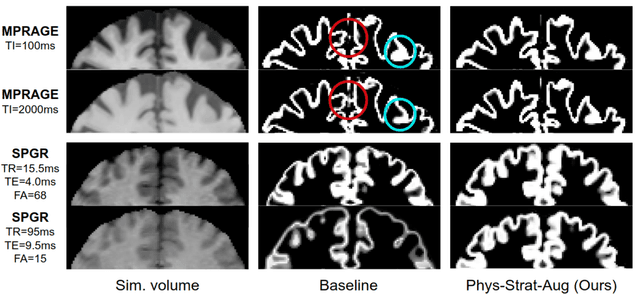
Being able to adequately process and combine data arising from different sites is crucial in neuroimaging, but is difficult, owing to site, sequence and acquisition-parameter dependent biases. It is important therefore to design algorithms that are not only robust to images of differing contrasts, but also be able to generalise well to unseen ones, with a quantifiable measure of uncertainty. In this paper we demonstrate the efficacy of a physics-informed, uncertainty-aware, segmentation network that employs augmentation-time MR simulations and homogeneous batch feature stratification to achieve acquisition invariance. We show that the proposed approach also accurately extrapolates to out-of-distribution sequence samples, providing well calibrated volumetric bounds on these. We demonstrate a significant improvement in terms of coefficients of variation, backed by uncertainty based volumetric validation.
Test-time Unsupervised Domain Adaptation
Oct 05, 2020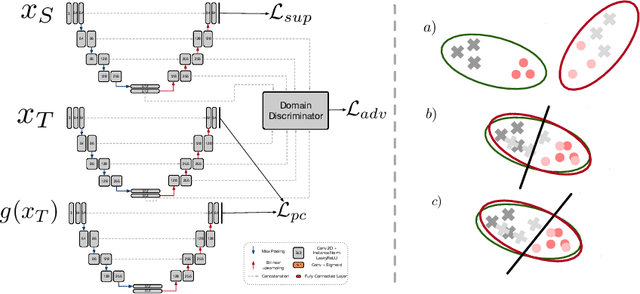
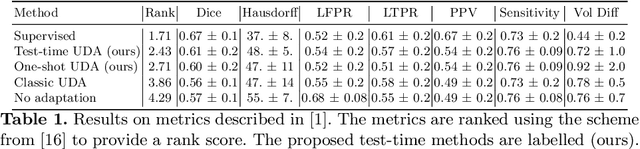
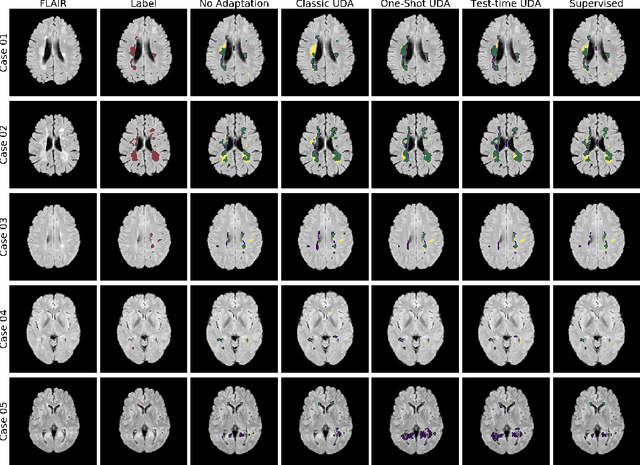
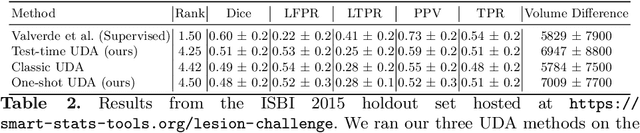
Convolutional neural networks trained on publicly available medical imaging datasets (source domain) rarely generalise to different scanners or acquisition protocols (target domain). This motivates the active field of domain adaptation. While some approaches to the problem require labeled data from the target domain, others adopt an unsupervised approach to domain adaptation (UDA). Evaluating UDA methods consists of measuring the model's ability to generalise to unseen data in the target domain. In this work, we argue that this is not as useful as adapting to the test set directly. We therefore propose an evaluation framework where we perform test-time UDA on each subject separately. We show that models adapted to a specific target subject from the target domain outperform a domain adaptation method which has seen more data of the target domain but not this specific target subject. This result supports the thesis that unsupervised domain adaptation should be used at test-time, even if only using a single target-domain subject
Hierarchical brain parcellation with uncertainty
Sep 16, 2020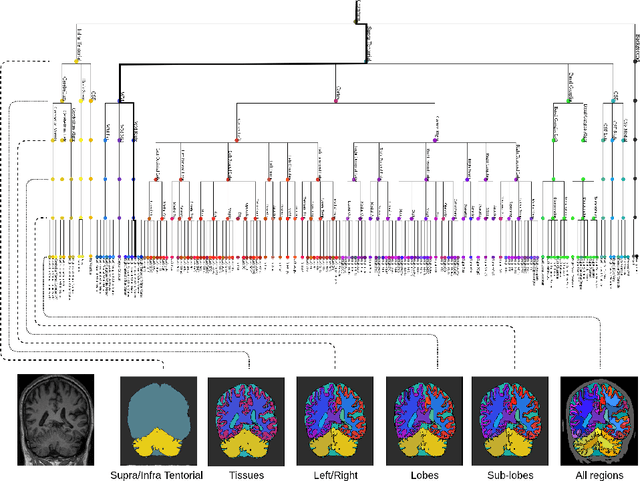
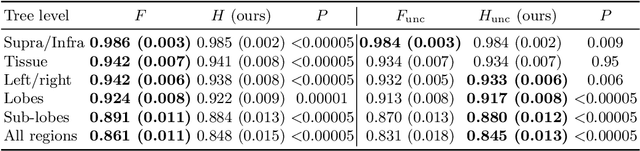
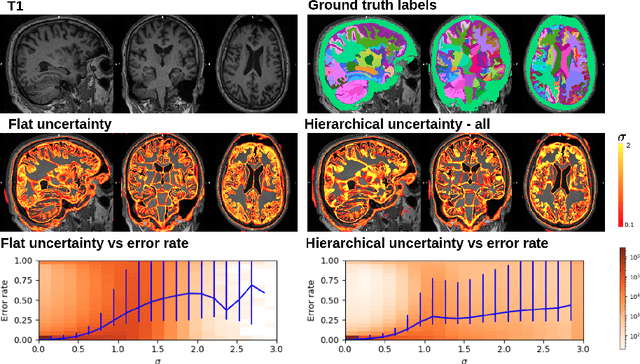
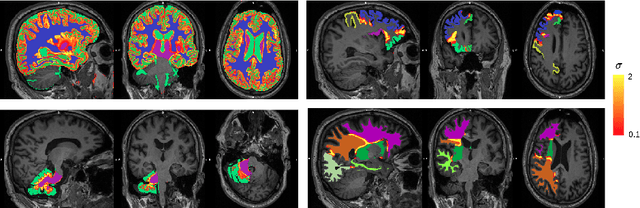
Many atlases used for brain parcellation are hierarchically organised, progressively dividing the brain into smaller sub-regions. However, state-of-the-art parcellation methods tend to ignore this structure and treat labels as if they are `flat'. We introduce a hierarchically-aware brain parcellation method that works by predicting the decisions at each branch in the label tree. We further show how this method can be used to model uncertainty separately for every branch in this label tree. Our method exceeds the performance of flat uncertainty methods, whilst also providing decomposed uncertainty estimates that enable us to obtain self-consistent parcellations and uncertainty maps at any level of the label hierarchy. We demonstrate a simple way these decision-specific uncertainty maps may be used to provided uncertainty-thresholded tissue maps at any level of the label tree.
Automated Labelling using an Attention model for Radiology reports of MRI scans (ALARM)
Feb 16, 2020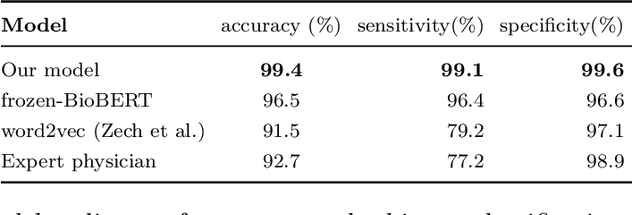


Labelling large datasets for training high-capacity neural networks is a major obstacle to the development of deep learning-based medical imaging applications. Here we present a transformer-based network for magnetic resonance imaging (MRI) radiology report classification which automates this task by assigning image labels on the basis of free-text expert radiology reports. Our model's performance is comparable to that of an expert radiologist, and better than that of an expert physician, demonstrating the feasibility of this approach. We make code available online for researchers to label their own MRI datasets for medical imaging applications.
Neuromorphologicaly-preserving Volumetric data encoding using VQ-VAE
Feb 13, 2020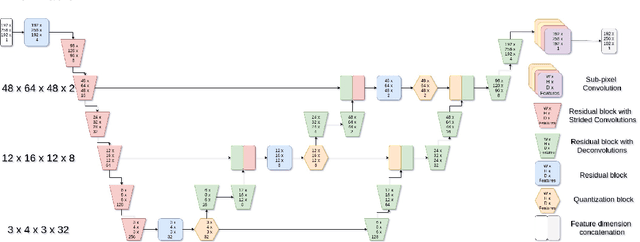
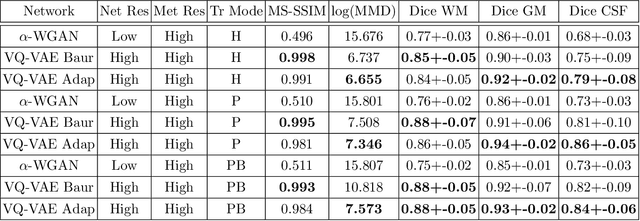
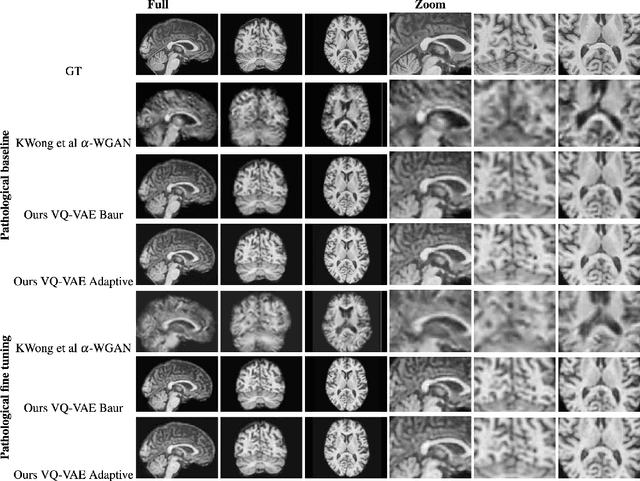
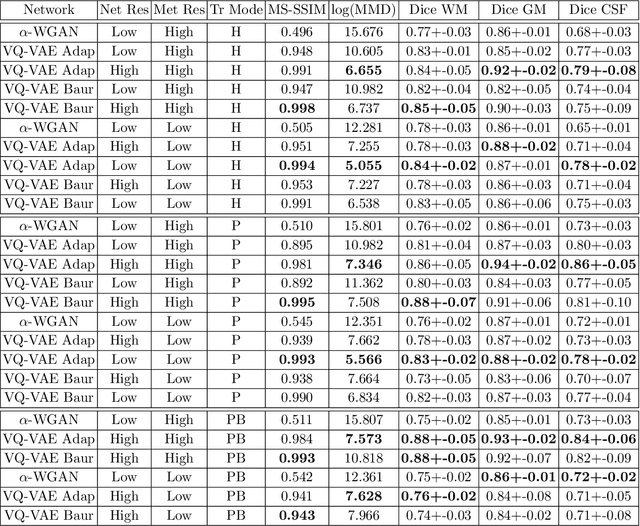
The increasing efficiency and compactness of deep learning architectures, together with hardware improvements, have enabled the complex and high-dimensional modelling of medical volumetric data at higher resolutions. Recently, Vector-Quantised Variational Autoencoders (VQ-VAE) have been proposed as an efficient generative unsupervised learning approach that can encode images to a small percentage of their initial size, while preserving their decoded fidelity. Here, we show a VQ-VAE inspired network can efficiently encode a full-resolution 3D brain volume, compressing the data to $0.825\%$ of the original size while maintaining image fidelity, and significantly outperforming the previous state-of-the-art. We then demonstrate that VQ-VAE decoded images preserve the morphological characteristics of the original data through voxel-based morphology and segmentation experiments. Lastly, we show that such models can be pre-trained and then fine-tuned on different datasets without the introduction of bias.
Multi-Domain Adaptation in Brain MRI through Paired Consistency and Adversarial Learning
Sep 17, 2019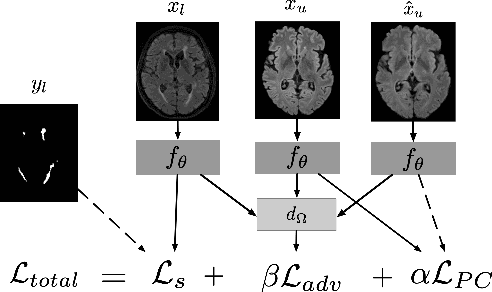
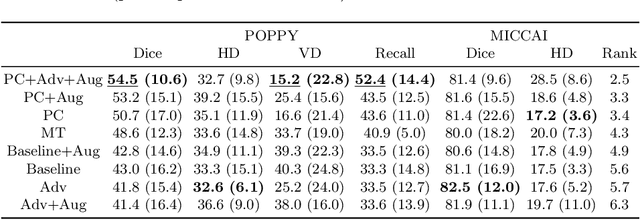
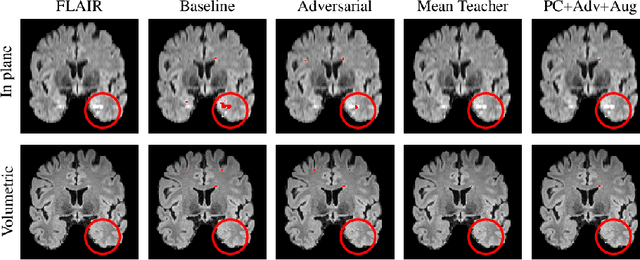
Supervised learning algorithms trained on medical images will often fail to generalize across changes in acquisition parameters. Recent work in domain adaptation addresses this challenge and successfully leverages labeled data in a source domain to perform well on an unlabeled target domain. Inspired by recent work in semi-supervised learning we introduce a novel method to adapt from one source domain to $n$ target domains (as long as there is paired data covering all domains). Our multi-domain adaptation method utilises a consistency loss combined with adversarial learning. We provide results on white matter lesion hyperintensity segmentation from brain MRIs using the MICCAI 2017 challenge data as the source domain and two target domains. The proposed method significantly outperforms other domain adaptation baselines.
Let's agree to disagree: learning highly debatable multirater labelling
Sep 04, 2019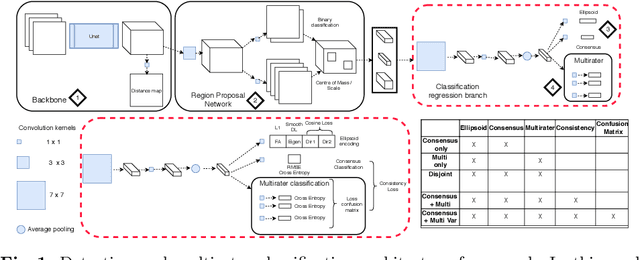
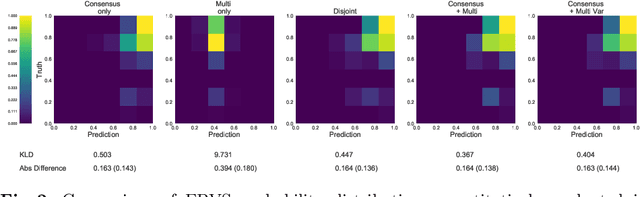
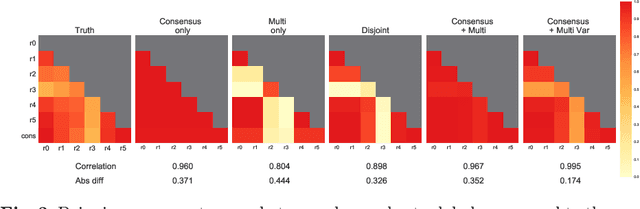
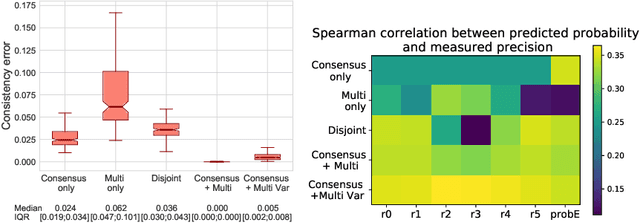
Classification and differentiation of small pathological objects may greatly vary among human raters due to differences in training, expertise and their consistency over time. In a radiological setting, objects commonly have high within-class appearance variability whilst sharing certain characteristics across different classes, making their distinction even more difficult. As an example, markers of cerebral small vessel disease, such as enlarged perivascular spaces (EPVS) and lacunes, can be very varied in their appearance while exhibiting high inter-class similarity, making this task highly challenging for human raters. In this work, we investigate joint models of individual rater behaviour and multirater consensus in a deep learning setting, and apply it to a brain lesion object-detection task. Results show that jointly modelling both individual and consensus estimates leads to significant improvements in performance when compared to directly predicting consensus labels, while also allowing the characterization of human-rater consistency.