 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible visual prompts for in-context learning in computer vision
Paper and Code
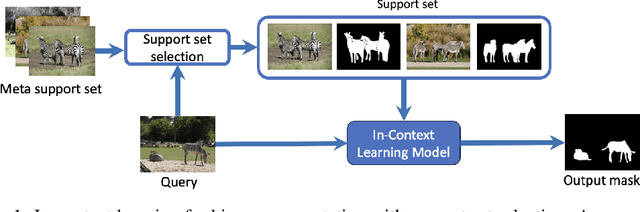
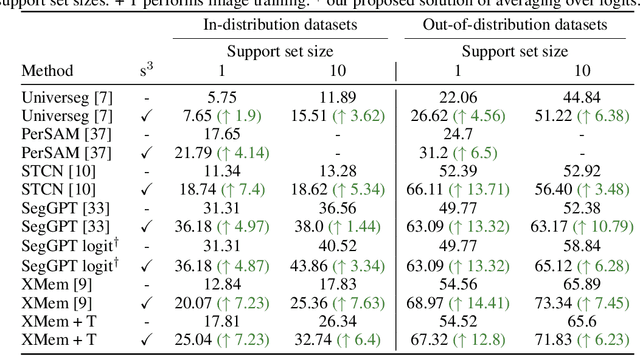

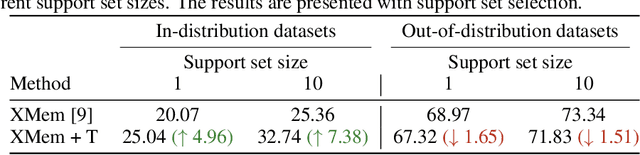
In this work, we address in-context learning (ICL) for the task of image segmentation, introducing a novel approach that adapts a modern Video Object Segmentation (VOS) technique for visual in-context learning. This adaptation is inspired by the VOS method's ability to efficiently and flexibly learn objects from a few examples. Through evaluations across a range of support set sizes and on diverse segmentation datasets, our method consistently surpasses existing techniques. Notably, it excels with data containing classes not encountered during training. Additionally, we propose a technique for support set selection, which involves choosing the most relevant images to include in this set. By employing support set selection, the performance increases for all tested methods without the need for additional training or prompt tuning. The code can be found at https://github.com/v7labs/XMem_ICL/.