 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Compression by Approximate Differential Equivalence
May 31, 2026Neural network compression is commonly achieved by pruning parameters based on local importance scores, e.g., magnitude-based pruning. We propose a complementary approach that compresses models by aggregating neurons with similar functional behavior rather than removing weights independently. Our method encodes a trained network as a polynomial ODE system and applies a lumping method called Approximate Forward Differential Equivalence to identify neurons with approximately matching induced dynamics. A single tolerance parameter, $\varepsilon$, controls the compression level and induces a smooth trade-off between model size and predictive accuracy. We evaluate the method on synthetic datasets derived from nonlinear dynamical systems with known ground-truth behavior and on public regression benchmarks. Across both settings, the proposed approach achieves substantial parameter reduction while preserving accuracy, and consistently compares favorably with magnitude-based pruning and Wanda at similar compression levels. These results suggest that differential equivalence-based aggregation is a principled and effective alternative to conventional weight-centric pruning.
DecHW: Heterogeneous Decentralized Federated Learning Exploiting Second-Order Information
Jan 16, 2026Decentralized Federated Learning (DFL) is a serverless collaborative machine learning paradigm where devices collaborate directly with neighbouring devices to exchange model information for learning a generalized model. However, variations in individual experiences and different levels of device interactions lead to data and model initialization heterogeneities across devices. Such heterogeneities leave variations in local model parameters across devices that leads to slower convergence. This paper tackles the data and model heterogeneity by explicitly addressing the parameter level varying evidential credence across local models. A novel aggregation approach is introduced that captures these parameter variations in local models and performs robust aggregation of neighbourhood local updates. Specifically, consensus weights are generated via approximation of second-order information of local models on their local datasets. These weights are utilized to scale neighbourhood updates before aggregating them into global neighbourhood representation. In extensive experiments with computer vision tasks, the proposed approach shows strong generalizability of local models at reduced communication costs.
EARL: Energy-Aware Optimization of Liquid State Machines for Pervasive AI
Jan 08, 2026Pervasive AI increasingly depends on on-device learning systems that deliver low-latency and energy-efficient computation under strict resource constraints. Liquid State Machines (LSMs) offer a promising approach for low-power temporal processing in pervasive and neuromorphic systems, but their deployment remains challenging due to high hyperparameter sensitivity and the computational cost of traditional optimization methods that ignore energy constraints. This work presents EARL, an energy-aware reinforcement learning framework that integrates Bayesian optimization with an adaptive reinforcement learning based selection policy to jointly optimize accuracy and energy consumption. EARL employs surrogate modeling for global exploration, reinforcement learning for dynamic candidate prioritization, and an early termination mechanism to eliminate redundant evaluations, substantially reducing computational overhead. Experiments on three benchmark datasets demonstrate that EARL achieves 6 to 15 percent higher accuracy, 60 to 80 percent lower energy consumption, and up to an order of magnitude reduction in optimization time compared to leading hyperparameter tuning frameworks. These results highlight the effectiveness of energy-aware adaptive search in improving the efficiency and scalability of LSMs for resource-constrained on-device AI applications.
The Built-In Robustness of Decentralized Federated Averaging to Bad Data
Feb 25, 2025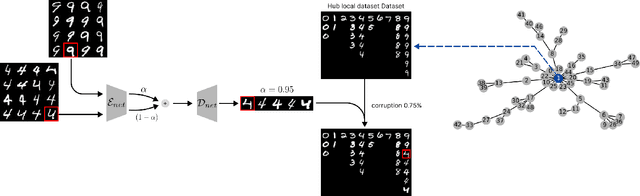
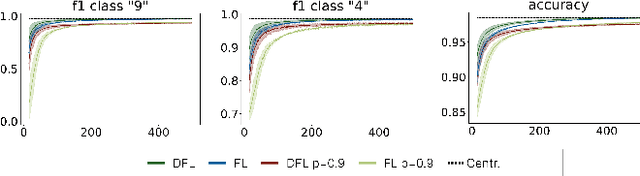

Decentralized federated learning (DFL) enables devices to collaboratively train models over complex network topologies without relying on a central controller. In this setting, local data remains private, but its quality and quantity can vary significantly across nodes. The extent to which a fully decentralized system is vulnerable to poor-quality or corrupted data remains unclear, but several factors could contribute to potential risks. Without a central authority, there can be no unified mechanism to detect or correct errors, and each node operates with a localized view of the data distribution, making it difficult for the node to assess whether its perspective aligns with the true distribution. Moreover, models trained on low-quality data can propagate through the network, amplifying errors. To explore the impact of low-quality data on DFL, we simulate two scenarios with degraded data quality -- one where the corrupted data is evenly distributed in a subset of nodes and one where it is concentrated on a single node -- using a decentralized implementation of FedAvg. Our results reveal that averaging-based decentralized learning is remarkably robust to localized bad data, even when the corrupted data resides in the most influential nodes of the network. Counterintuitively, this robustness is further enhanced when the corrupted data is concentrated on a single node, regardless of its centrality in the communication network topology. This phenomenon is explained by the averaging process, which ensures that no single node -- however central -- can disproportionately influence the overall learning process.
Federated Clustering: An Unsupervised Cluster-Wise Training for Decentralized Data Distributions
Aug 20, 2024



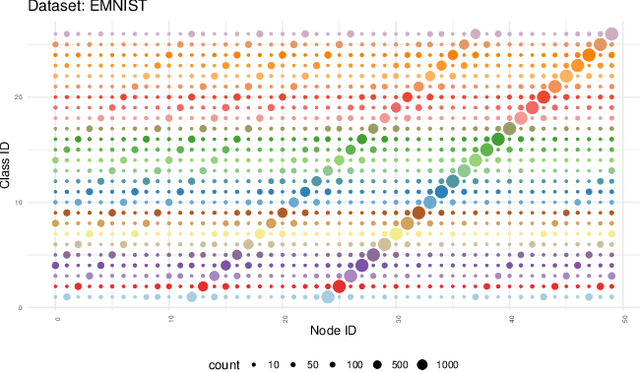
Federated Learning (FL) is a pivotal approach in decentralized machine learning, especially when data privacy is crucial and direct data sharing is impractical. While FL is typically associated with supervised learning, its potential in unsupervised scenarios is underexplored. This paper introduces a novel unsupervised federated learning methodology designed to identify the complete set of categories (global K) across multiple clients within label-free, non-uniform data distributions, a process known as Federated Clustering. Our approach, Federated Cluster-Wise Refinement (FedCRef), involves clients that collaboratively train models on clusters with similar data distributions. Initially, clients with diverse local data distributions (local K) train models on their clusters to generate compressed data representations. These local models are then shared across the network, enabling clients to compare them through reconstruction error analysis, leading to the formation of federated groups.In these groups, clients collaboratively train a shared model representing each data distribution, while continuously refining their local clusters to enhance data association accuracy. This iterative process allows our system to identify all potential data distributions across the network and develop robust representation models for each. To validate our approach, we compare it with traditional centralized methods, establishing a performance baseline and showcasing the advantages of our distributed solution. We also conduct experiments on the EMNIST and KMNIST datasets, demonstrating FedCRef's ability to refine and align cluster models with actual data distributions, significantly improving data representation precision in unsupervised federated settings.
FedQUIT: On-Device Federated Unlearning via a Quasi-Competent Virtual Teacher
Aug 14, 2024



Federated Learning (FL) promises better privacy guarantees for individuals' data when machine learning models are collaboratively trained. When an FL participant exercises its right to be forgotten, i.e., to detach from the FL framework it has participated and to remove its past contributions to the global model, the FL solution should perform all the necessary steps to make it possible without sacrificing the overall performance of the global model, which is not supported in state-of-the-art related solutions nowadays. In this paper, we propose FedQUIT, a novel algorithm that uses knowledge distillation to scrub the contribution of the forgetting data from an FL global model while preserving its generalization ability. FedQUIT directly works on clients' devices and does not require sharing additional information if compared with a regular FL process, nor does it assume the availability of publicly available proxy data. Our solution is efficient, effective, and applicable in both centralized and federated settings. Our experimental results show that, on average, FedQUIT requires less than 2.5% additional communication rounds to recover generalization performances after unlearning, obtaining a sanitized global model whose predictions are comparable to those of a global model that has never seen the data to be forgotten.
Robustness of Decentralised Learning to Nodes and Data Disruption
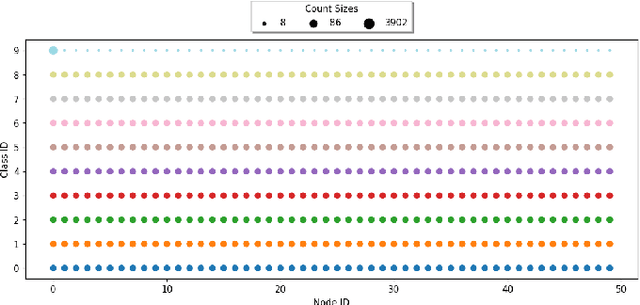
May 03, 2024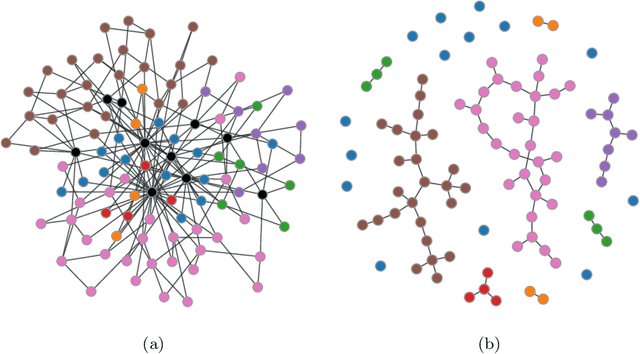


In the vibrant landscape of AI research, decentralised learning is gaining momentum. Decentralised learning allows individual nodes to keep data locally where they are generated and to share knowledge extracted from local data among themselves through an interactive process of collaborative refinement. This paradigm supports scenarios where data cannot leave local nodes due to privacy or sovereignty reasons or real-time constraints imposing proximity of models to locations where inference has to be carried out. The distributed nature of decentralised learning implies significant new research challenges with respect to centralised learning. Among them, in this paper, we focus on robustness issues. Specifically, we study the effect of nodes' disruption on the collective learning process. Assuming a given percentage of "central" nodes disappear from the network, we focus on different cases, characterised by (i) different distributions of data across nodes and (ii) different times when disruption occurs with respect to the start of the collaborative learning task. Through these configurations, we are able to show the non-trivial interplay between the properties of the network connecting nodes, the persistence of knowledge acquired collectively before disruption or lack thereof, and the effect of data availability pre- and post-disruption. Our results show that decentralised learning processes are remarkably robust to network disruption. As long as even minimum amounts of data remain available somewhere in the network, the learning process is able to recover from disruptions and achieve significant classification accuracy. This clearly varies depending on the remaining connectivity after disruption, but we show that even nodes that remain completely isolated can retain significant knowledge acquired before the disruption.
Initialisation and Topology Effects in Decentralised Federated Learning
Mar 23, 2024Fully decentralised federated learning enables collaborative training of individual machine learning models on distributed devices on a network while keeping the training data localised. This approach enhances data privacy and eliminates both the single point of failure and the necessity for central coordination. Our research highlights that the effectiveness of decentralised federated learning is significantly influenced by the network topology of connected devices. A simplified numerical model for studying the early behaviour of these systems leads us to an improved artificial neural network initialisation strategy, which leverages the distribution of eigenvector centralities of the nodes of the underlying network, leading to a radically improved training efficiency. Additionally, our study explores the scaling behaviour and choice of environmental parameters under our proposed initialisation strategy. This work paves the way for more efficient and scalable artificial neural network training in a distributed and uncoordinated environment, offering a deeper understanding of the intertwining roles of network structure and learning dynamics.
Impact of network topology on the performance of Decentralized Federated Learning
Feb 28, 2024



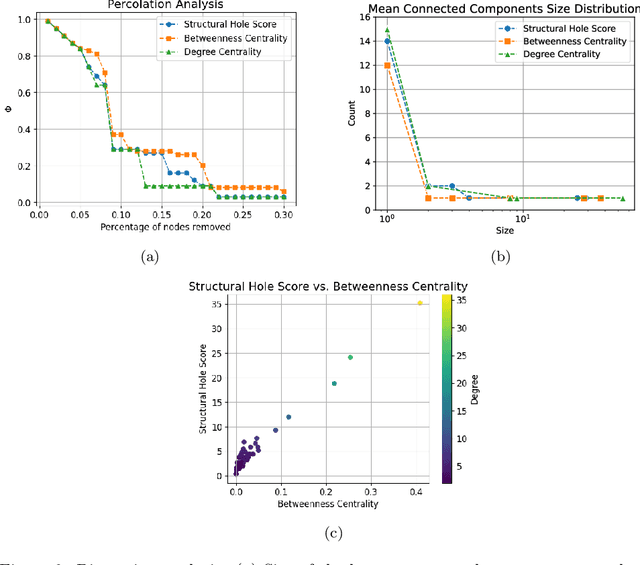
Fully decentralized learning is gaining momentum for training AI models at the Internet's edge, addressing infrastructure challenges and privacy concerns. In a decentralized machine learning system, data is distributed across multiple nodes, with each node training a local model based on its respective dataset. The local models are then shared and combined to form a global model capable of making accurate predictions on new data. Our exploration focuses on how different types of network structures influence the spreading of knowledge - the process by which nodes incorporate insights gained from learning patterns in data available on other nodes across the network. Specifically, this study investigates the intricate interplay between network structure and learning performance using three network topologies and six data distribution methods. These methods consider different vertex properties, including degree centrality, betweenness centrality, and clustering coefficient, along with whether nodes exhibit high or low values of these metrics. Our findings underscore the significance of global centrality metrics (degree, betweenness) in correlating with learning performance, while local clustering proves less predictive. We highlight the challenges in transferring knowledge from peripheral to central nodes, attributed to a dilution effect during model aggregation. Additionally, we observe that central nodes exert a pull effect, facilitating the spread of knowledge. In examining degree distribution, hubs in Barabasi-Albert networks positively impact learning for central nodes but exacerbate dilution when knowledge originates from peripheral nodes. Finally, we demonstrate the formidable challenge of knowledge circulation outside of segregated communities.
Coordination-free Decentralised Federated Learning on Complex Networks: Overcoming Heterogeneity
Dec 07, 2023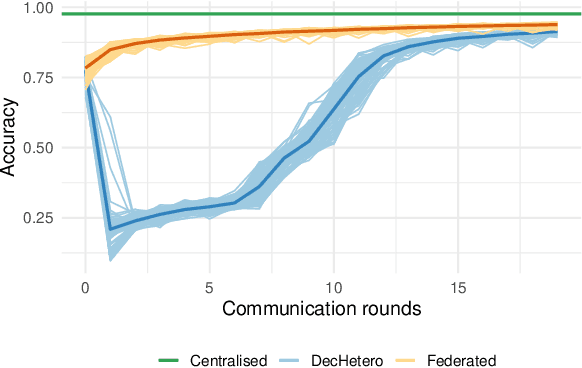
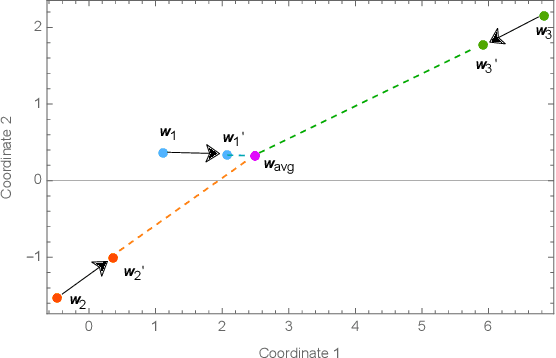
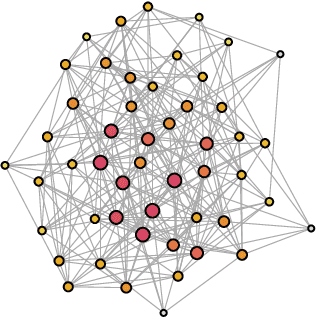
Federated Learning (FL) is a well-known framework for successfully performing a learning task in an edge computing scenario where the devices involved have limited resources and incomplete data representation. The basic assumption of FL is that the devices communicate directly or indirectly with a parameter server that centrally coordinates the whole process, overcoming several challenges associated with it. However, in highly pervasive edge scenarios, the presence of a central controller that oversees the process cannot always be guaranteed, and the interactions (i.e., the connectivity graph) between devices might not be predetermined, resulting in a complex network structure. Moreover, the heterogeneity of data and devices further complicates the learning process. This poses new challenges from a learning standpoint that we address by proposing a communication-efficient Decentralised Federated Learning (DFL) algorithm able to cope with them. Our solution allows devices communicating only with their direct neighbours to train an accurate model, overcoming the heterogeneity induced by data and different training histories. Our results show that the resulting local models generalise better than those trained with competing approaches, and do so in a more communication-efficient way.