 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Clustering: An Unsupervised Cluster-Wise Training for Decentralized Data Distributions
Aug 20, 2024



Federated Learning (FL) is a pivotal approach in decentralized machine learning, especially when data privacy is crucial and direct data sharing is impractical. While FL is typically associated with supervised learning, its potential in unsupervised scenarios is underexplored. This paper introduces a novel unsupervised federated learning methodology designed to identify the complete set of categories (global K) across multiple clients within label-free, non-uniform data distributions, a process known as Federated Clustering. Our approach, Federated Cluster-Wise Refinement (FedCRef), involves clients that collaboratively train models on clusters with similar data distributions. Initially, clients with diverse local data distributions (local K) train models on their clusters to generate compressed data representations. These local models are then shared across the network, enabling clients to compare them through reconstruction error analysis, leading to the formation of federated groups.In these groups, clients collaboratively train a shared model representing each data distribution, while continuously refining their local clusters to enhance data association accuracy. This iterative process allows our system to identify all potential data distributions across the network and develop robust representation models for each. To validate our approach, we compare it with traditional centralized methods, establishing a performance baseline and showcasing the advantages of our distributed solution. We also conduct experiments on the EMNIST and KMNIST datasets, demonstrating FedCRef's ability to refine and align cluster models with actual data distributions, significantly improving data representation precision in unsupervised federated settings.
Anomaly Detection through Unsupervised Federated Learning
Sep 09, 2022


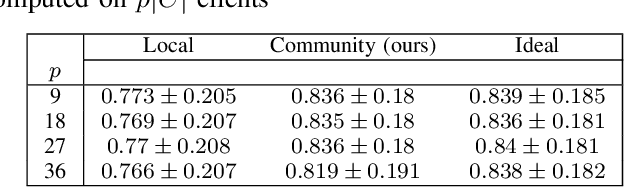
Federated learning (FL) is proving to be one of the most promising paradigms for leveraging distributed resources, enabling a set of clients to collaboratively train a machine learning model while keeping the data decentralized. The explosive growth of interest in the topic has led to rapid advancements in several core aspects like communication efficiency, handling non-IID data, privacy, and security capabilities. However, the majority of FL works only deal with supervised tasks, assuming that clients' training sets are labeled. To leverage the enormous unlabeled data on distributed edge devices, in this paper, we aim to extend the FL paradigm to unsupervised tasks by addressing the problem of anomaly detection in decentralized settings. In particular, we propose a novel method in which, through a preprocessing phase, clients are grouped into communities, each having similar majority (i.e., inlier) patterns. Subsequently, each community of clients trains the same anomaly detection model (i.e., autoencoders) in a federated fashion. The resulting model is then shared and used to detect anomalies within the clients of the same community that joined the corresponding federated process. Experiments show that our method is robust, and it can detect communities consistent with the ideal partitioning in which groups of clients having the same inlier patterns are known. Furthermore, the performance is significantly better than those in which clients train models exclusively on local data and comparable with federated models of ideal communities' partition.