 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Value of Big Data for Credit Scoring: Enhancing Financial Inclusion using Mobile Phone Data and Social Network Analytics
Feb 23, 2020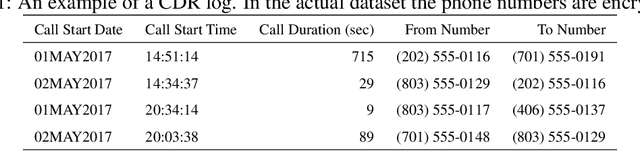
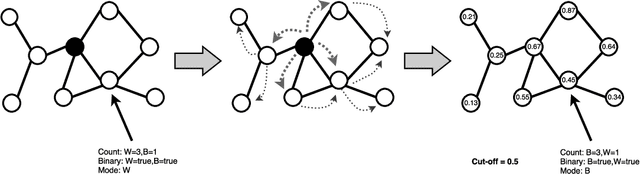

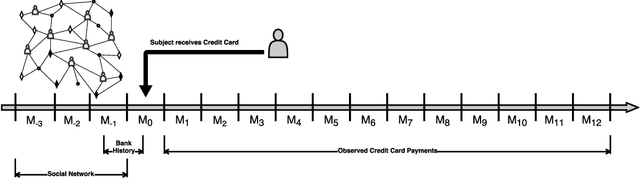
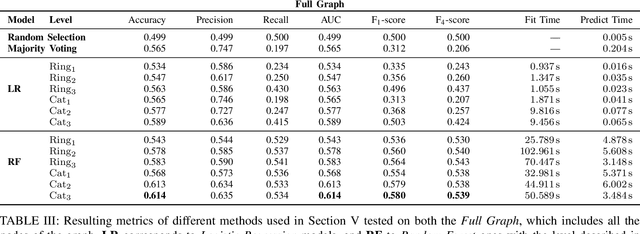
Credit scoring is without a doubt one of the oldest applications of analytics. In recent years, a multitude of sophisticated classification techniques have been developed to improve the statistical performance of credit scoring models. Instead of focusing on the techniques themselves, this paper leverages alternative data sources to enhance both statistical and economic model performance. The study demonstrates how including call networks, in the context of positive credit information, as a new Big Data source has added value in terms of profit by applying a profit measure and profit-based feature selection. A unique combination of datasets, including call-detail records, credit and debit account information of customers is used to create scorecards for credit card applicants. Call-detail records are used to build call networks and advanced social network analytics techniques are applied to propagate influence from prior defaulters throughout the network to produce influence scores. The results show that combining call-detail records with traditional data in credit scoring models significantly increases their performance when measured in AUC. In terms of profit, the best model is the one built with only calling behavior features. In addition, the calling behavior features are the most predictive in other models, both in terms of statistical and economic performance. The results have an impact in terms of ethical use of call-detail records, regulatory implications, financial inclusion, as well as data sharing and privacy.
Brief survey of Mobility Analyses based on Mobile Phone Datasets
Dec 03, 2018
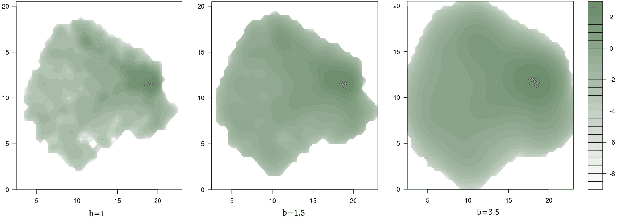
This is a brief survey of the research performed by Grandata Labs in collaboration with numerous academic groups around the world on the topic of human mobility. A driving theme in these projects is to use and improve Data Science techniques to understand mobility, as it can be observed through the lens of mobile phone datasets. We describe applications of mobility analyses for urban planning, prediction of data traffic usage, building delay tolerant networks, generating epidemiologic risk maps and measuring the predictability of human mobility.
Comparison of Feature Extraction Methods and Predictors for Income Inference
Nov 13, 2018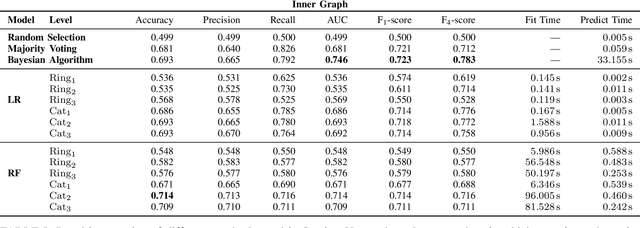

Patterns of mobile phone communications, coupled with the information of the social network graph and financial behavior, allow us to make inferences of users' socio-economic attributes such as their income level. We present here several methods to extract features from mobile phone usage (calls and messages), and compare different combinations of supervised machine learning techniques and sets of features used as input for the inference of users' income. Our experimental results show that the Bayesian method based on the communication graph outperforms standard machine learning algorithms using node-based features.
A Bayesian Approach to Income Inference in a Communication Network
Nov 10, 2018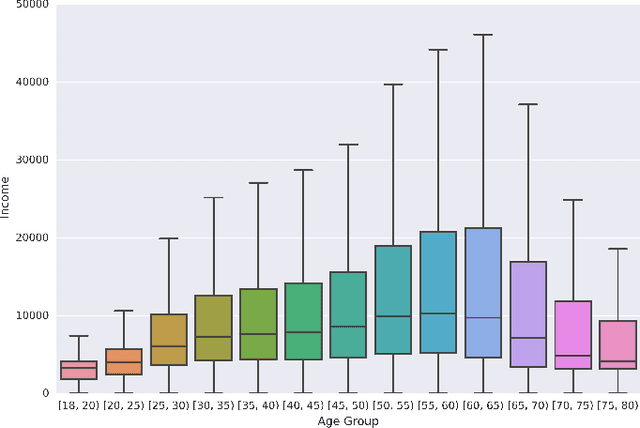
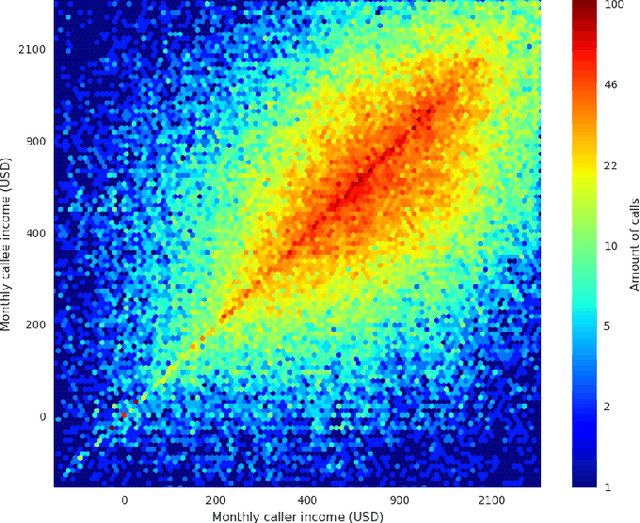
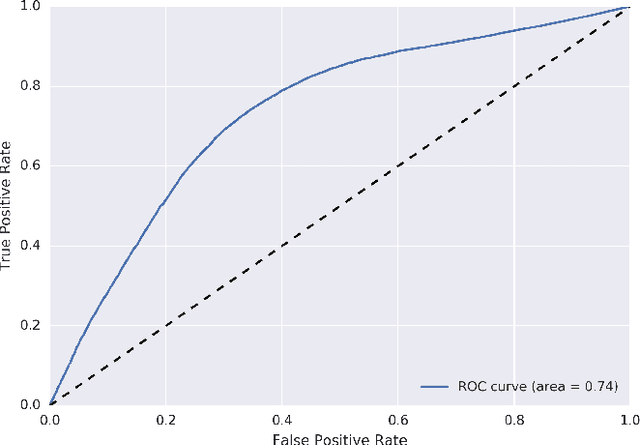
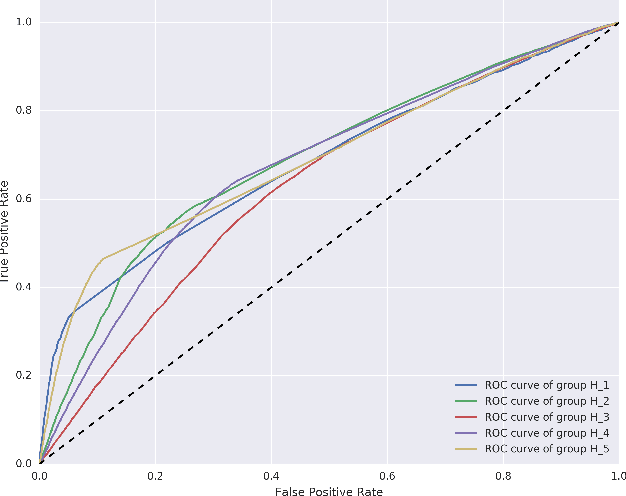
The explosion of mobile phone communications in the last years occurs at a moment where data processing power increases exponentially. Thanks to those two changes in a global scale, the road has been opened to use mobile phone communications to generate inferences and characterizations of mobile phone users. In this work, we use the communication network, enriched by a set of users' attributes, to gain a better understanding of the demographic features of a population. Namely, we use call detail records and banking information to infer the income of each person in the graph.
Uncovering the Spread of Chagas Disease in Argentina and Mexico
Aug 09, 2018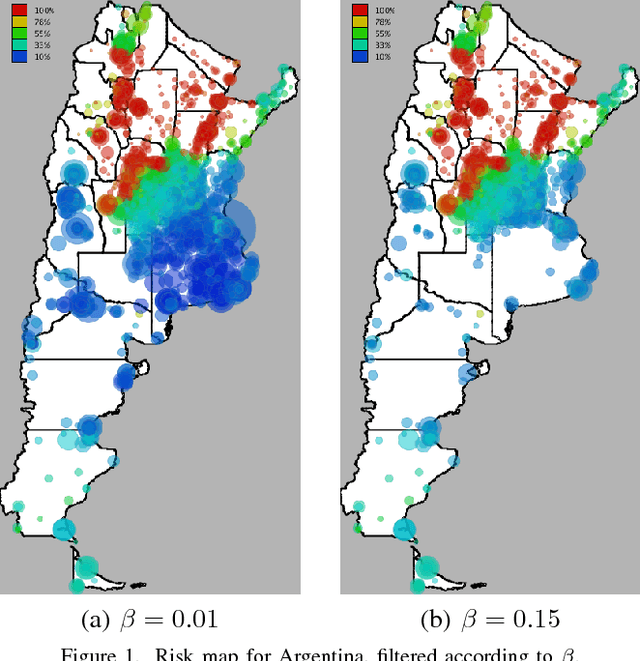
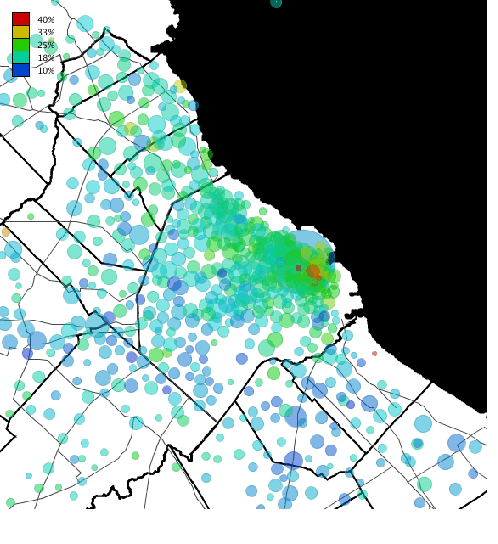
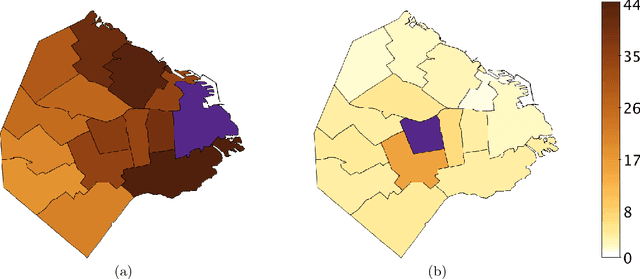
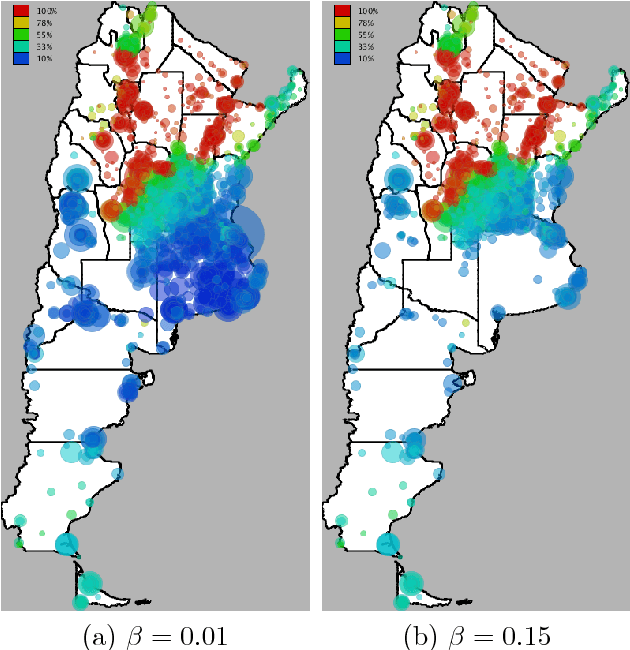
Chagas disease is a neglected disease, and information about its geographical spread is very scarse. We analyze here mobility and calling patterns in order to identify potential risk zones for the disease, by using public health information and mobile phone records. Geolocalized call records are rich in social and mobility information, which can be used to infer whether an individual has lived in an endemic area. We present two case studies in Latin American countries. Our objective is to generate risk maps which can be used by public health campaign managers to prioritize detection campaigns and target specific areas. Finally, we analyze the value of mobile phone data to infer long-term migrations, which play a crucial role in the geographical spread of Chagas disease.
Inference of Users Demographic Attributes based on Homophily in Communication Networks
Aug 01, 2018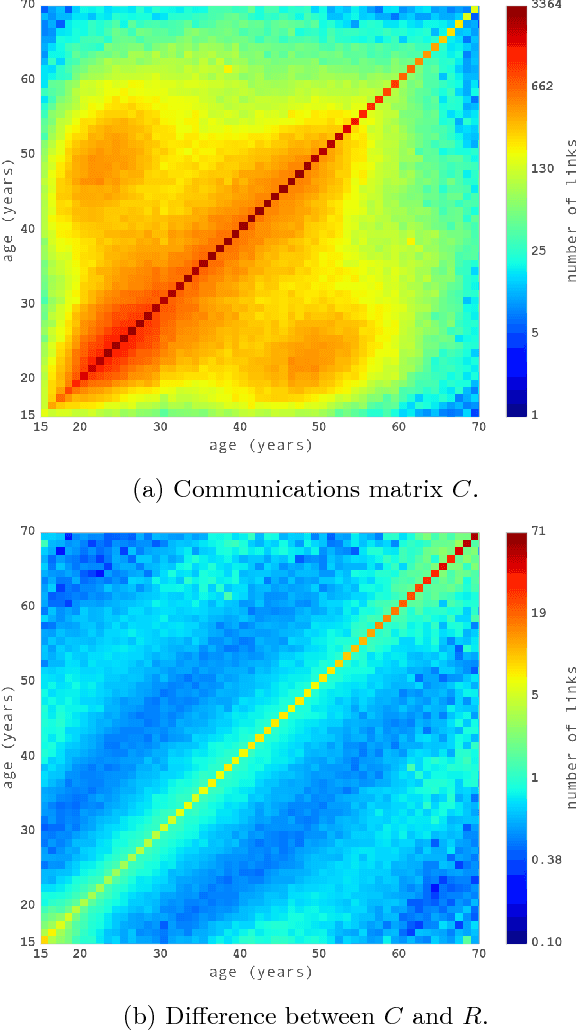
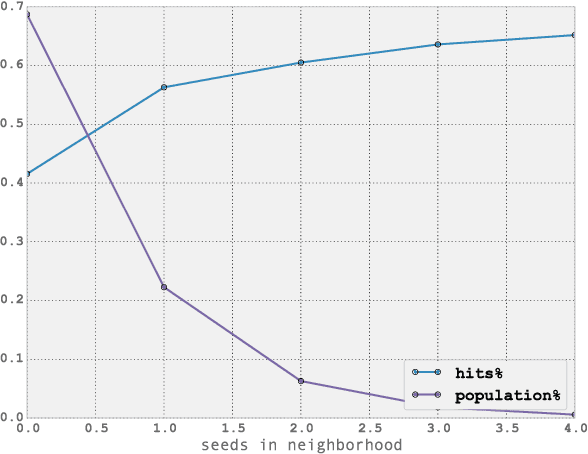
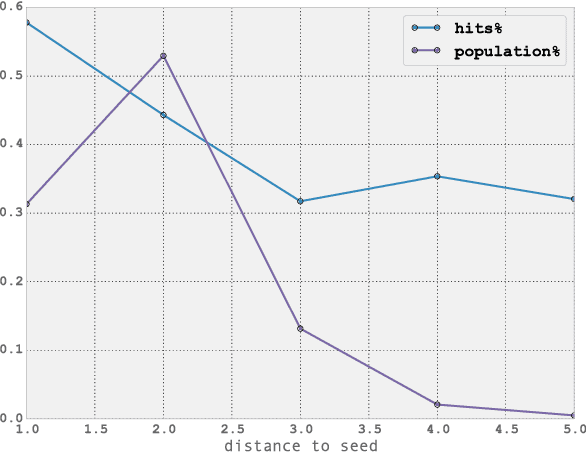
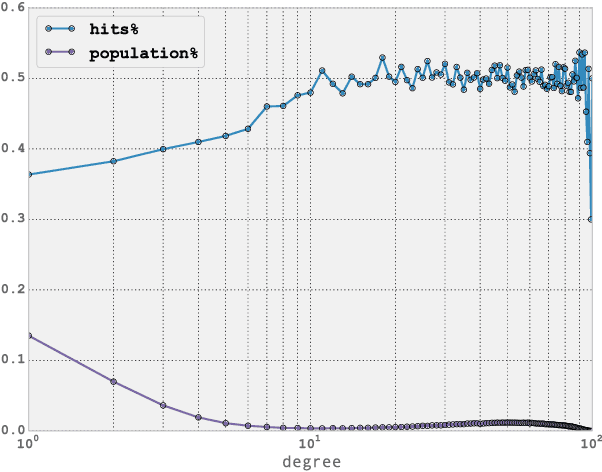
Over the past decade, mobile phones have become prevalent in all parts of the world, across all demographic backgrounds. Mobile phones are used by men and women across a wide age range in both developed and developing countries. Consequently, they have become one of the most important mechanisms for social interaction within a population, making them an increasingly important source of information to understand human demographics and human behaviour. In this work we combine two sources of information: communication logs from a major mobile operator in a Latin American country, and information on the demographics of a subset of the users population. This allows us to perform an observational study of mobile phone usage, differentiated by age groups categories. This study is interesting in its own right, since it provides knowledge on the structure and demographics of the mobile phone market in the studied country. We then tackle the problem of inferring the age group for all users in the network. We present here an exclusively graph-based inference method relying solely on the topological structure of the mobile network, together with a topological analysis of the performance of the algorithm. The equations for our algorithm can be described as a diffusion process with two added properties: (i) memory of its initial state, and (ii) the information is propagated as a probability vector for each node attribute (instead of the value of the attribute itself). Our algorithm can successfully infer different age groups within the network population given known values for a subset of nodes (seed nodes). Most interestingly, we show that by carefully analysing the topological relationships between correctly predicted nodes and the seed nodes, we can characterize particular subsets of nodes for which our inference method has significantly higher accuracy.
Prepaid or Postpaid? That is the question. Novel Methods of Subscription Type Prediction in Mobile Phone Services
Jun 30, 2017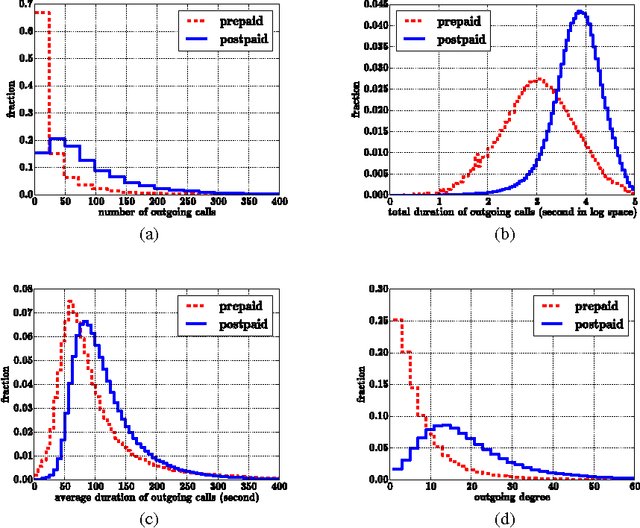


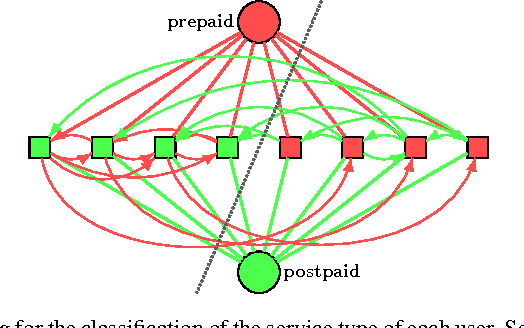
In this paper we investigate the behavioural differences between mobile phone customers with prepaid and postpaid subscriptions. Our study reveals that (a) postpaid customers are more active in terms of service usage and (b) there are strong structural correlations in the mobile phone call network as connections between customers of the same subscription type are much more frequent than those between customers of different subscription types. Based on these observations we provide methods to detect the subscription type of customers by using information about their personal call statistics, and also their egocentric networks simultaneously. The key of our first approach is to cast this classification problem as a problem of graph labelling, which can be solved by max-flow min-cut algorithms. Our experiments show that, by using both user attributes and relationships, the proposed graph labelling approach is able to achieve a classification accuracy of $\sim 87\%$, which outperforms by $\sim 7\%$ supervised learning methods using only user attributes. In our second problem we aim to infer the subscription type of customers of external operators. We propose via approximate methods to solve this problem by using node attributes, and a two-ways indirect inference method based on observed homophilic structural correlations. Our results have straightforward applications in behavioural prediction and personal marketing.
POMDPs Make Better Hackers: Accounting for Uncertainty in Penetration Testing
Jul 31, 2013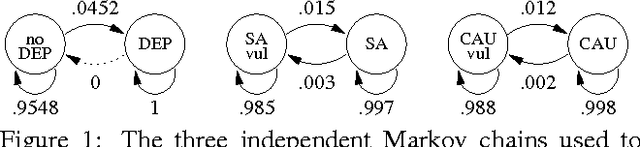
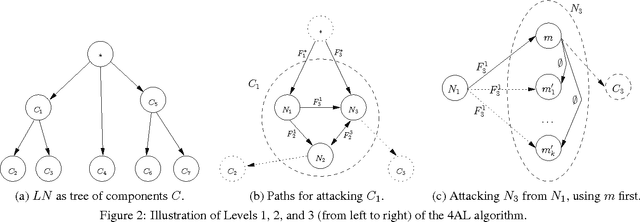

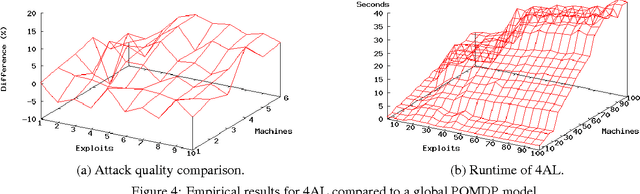
Penetration Testing is a methodology for assessing network security, by generating and executing possible hacking attacks. Doing so automatically allows for regular and systematic testing. A key question is how to generate the attacks. This is naturally formulated as planning under uncertainty, i.e., under incomplete knowledge about the network configuration. Previous work uses classical planning, and requires costly pre-processes reducing this uncertainty by extensive application of scanning methods. By contrast, we herein model the attack planning problem in terms of partially observable Markov decision processes (POMDP). This allows to reason about the knowledge available, and to intelligently employ scanning actions as part of the attack. As one would expect, this accurate solution does not scale. We devise a method that relies on POMDPs to find good attacks on individual machines, which are then composed into an attack on the network as a whole. This decomposition exploits network structure to the extent possible, making targeted approximations (only) where needed. Evaluating this method on a suitably adapted industrial test suite, we demonstrate its effectiveness in both runtime and solution quality.
* Twenty-Sixth Conference on Artificial Intelligence (AAAI-12), Toronto, Canada
Les POMDP font de meilleurs hackers: Tenir compte de l'incertitude dans les tests de penetration
Jul 30, 2013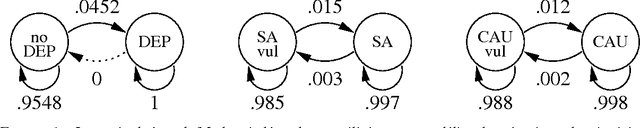



Penetration Testing is a methodology for assessing network security, by generating and executing possible hacking attacks. Doing so automatically allows for regular and systematic testing. A key question is how to generate the attacks. This is naturally formulated as planning under uncertainty, i.e., under incomplete knowledge about the network configuration. Previous work uses classical planning, and requires costly pre-processes reducing this uncertainty by extensive application of scanning methods. By contrast, we herein model the attack planning problem in terms of partially observable Markov decision processes (POMDP). This allows to reason about the knowledge available, and to intelligently employ scanning actions as part of the attack. As one would expect, this accurate solution does not scale. We devise a method that relies on POMDPs to find good attacks on individual machines, which are then composed into an attack on the network as a whole. This decomposition exploits network structure to the extent possible, making targeted approximations (only) where needed. Evaluating this method on a suitably adapted industrial test suite, we demonstrate its effectiveness in both runtime and solution quality.
Automated Attack Planning
Jul 30, 2013


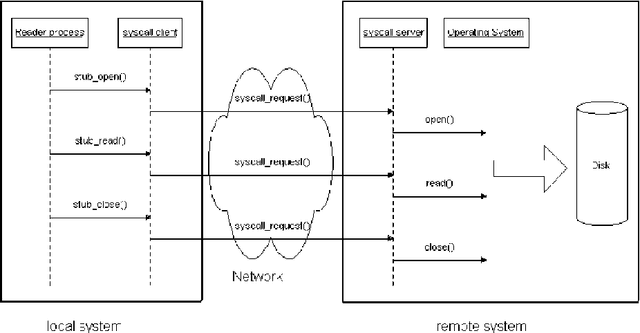
Penetration Testing is a methodology for assessing network security, by generating and executing possible attacks. Doing so automatically allows for regular and systematic testing. A key question then is how to automatically generate the attacks. A natural way to address this issue is as an attack planning problem. In this thesis, we are concerned with the specific context of regular automated pentesting, and use the term "attack planning" in that sense. The following three research directions are investigated. First, we introduce a conceptual model of computer network attacks, based on an analysis of the penetration testing practices. We study how this attack model can be represented in the PDDL language. Then we describe an implementation that integrates a classical planner with a penetration testing tool. This allows us to automatically generate attack paths for real world pentesting scenarios, and to validate these attacks by executing them. Secondly, we present efficient probabilistic planning algorithms, specifically designed for this problem, that achieve industrial-scale runtime performance (able to solve scenarios with several hundred hosts and exploits). These algorithms take into account the probability of success of the actions and their expected cost (for example in terms of execution time, or network traffic generated). Finally, we take a different direction: instead of trying to improve the efficiency of the solutions developed, we focus on improving the model of the attacker. We model the attack planning problem in terms of partially observable Markov decision processes (POMDP). This grounds penetration testing in a well-researched formalism. POMDPs allow the modelling of information gathering as an integral part of the problem, thus providing for the first time a means to intelligently mix scanning actions with actual exploits.