 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Average Approximation for Black-Box VI
Apr 13, 2023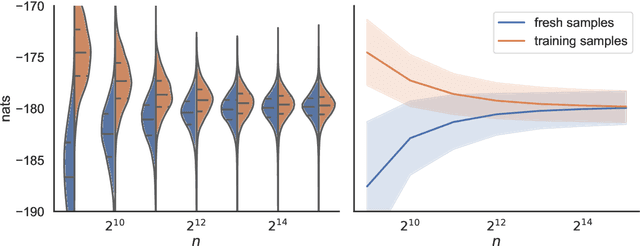

We present a novel approach for black-box VI that bypasses the difficulties of stochastic gradient ascent, including the task of selecting step-sizes. Our approach involves using a sequence of sample average approximation (SAA) problems. SAA approximates the solution of stochastic optimization problems by transforming them into deterministic ones. We use quasi-Newton methods and line search to solve each deterministic optimization problem and present a heuristic policy to automate hyperparameter selection. Our experiments show that our method simplifies the VI problem and achieves faster performance than existing methods.
U-Statistics for Importance-Weighted Variational Inference
Feb 27, 2023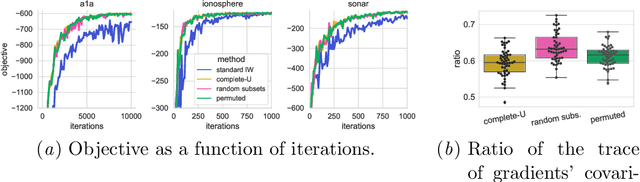
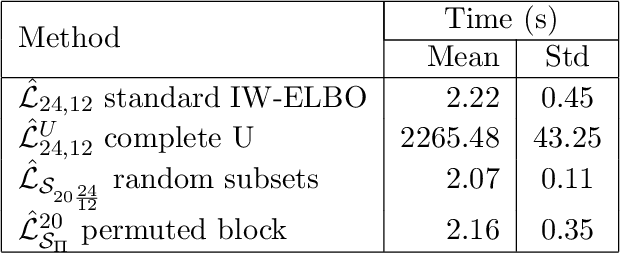
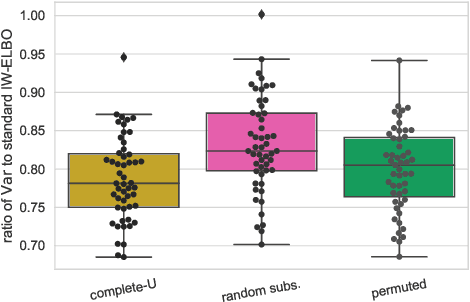
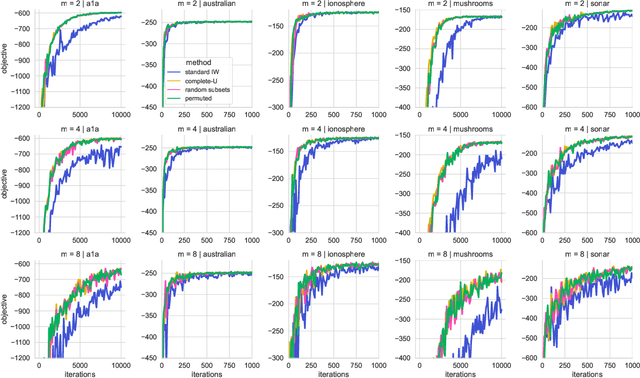
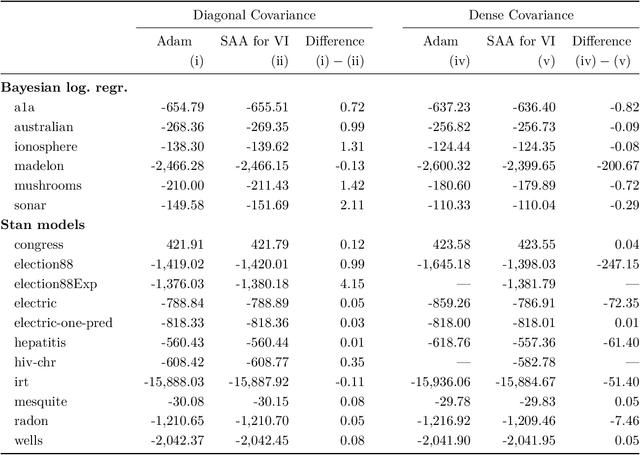
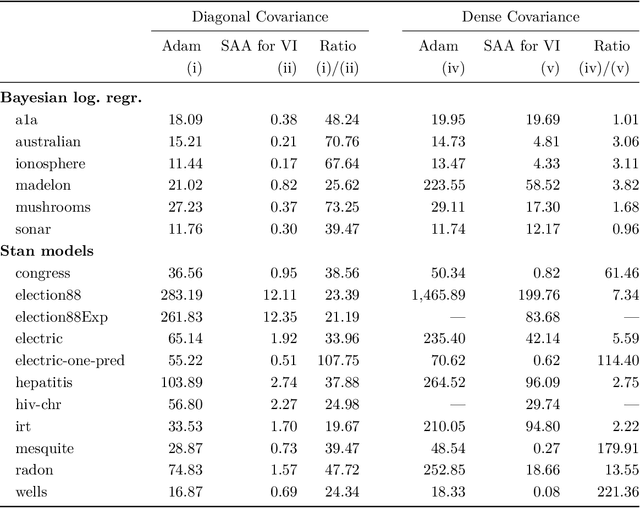
We propose the use of U-statistics to reduce variance for gradient estimation in importance-weighted variational inference. The key observation is that, given a base gradient estimator that requires $m > 1$ samples and a total of $n > m$ samples to be used for estimation, lower variance is achieved by averaging the base estimator on overlapping batches of size $m$ than disjoint batches, as currently done. We use classical U-statistic theory to analyze the variance reduction, and propose novel approximations with theoretical guarantees to ensure computational efficiency. We find empirically that U-statistic variance reduction can lead to modest to significant improvements in inference performance on a range of models, with little computational cost.
Automatically Marginalized MCMC in Probabilistic Programming
Feb 01, 2023



Hamiltonian Monte Carlo (HMC) is a powerful algorithm to sample latent variables from Bayesian models. The advent of probabilistic programming languages (PPLs) frees users from writing inference algorithms and lets users focus on modeling. However, many models are difficult for HMC to solve directly, which often require tricks like model reparameterization. We are motivated by the fact that many of those models could be simplified by marginalization. We propose to use automatic marginalization as part of the sampling process using HMC in a graphical model extracted from a PPL, which substantially improves sampling from real-world hierarchical models.
The Random Conditional Distribution for Higher-Order Probabilistic Inference
Mar 25, 2019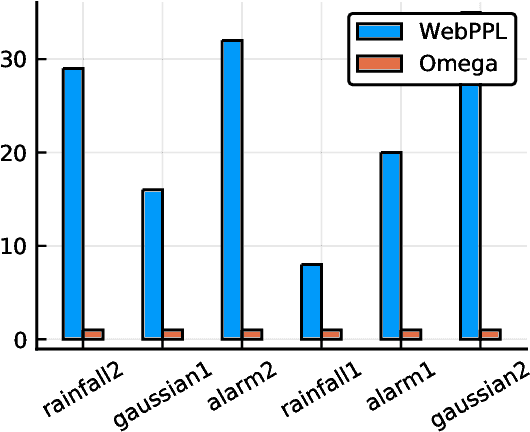


The need to condition distributional properties such as expectation, variance, and entropy arises in algorithmic fairness, model simplification, robustness and many other areas. At face value however, distributional properties are not random variables, and hence conditioning them is a semantic error and type error in probabilistic programming languages. On the other hand, distributional properties are contingent on other variables in the model, change in value when we observe more information, and hence in a precise sense are random variables too. In order to capture the uncertain over distributional properties, we introduce a probability construct -- the random conditional distribution -- and incorporate it into a probabilistic programming language Omega. A random conditional distribution is a higher-order random variable whose realizations are themselves conditional random variables. In Omega we extend distributional properties of random variables to random conditional distributions, such that for example while the expectation a real valued random variable is a real value, the expectation of a random conditional distribution is a distribution over expectations. As a consequence, it requires minimal syntax to encode inference problems over distributional properties, which so far have evaded treatment within probabilistic programming systems and probabilistic modeling in general. We demonstrate our approach case studies in algorithmic fairness and robustness.
Soft Constraints for Inference with Declarative Knowledge
Jan 16, 2019
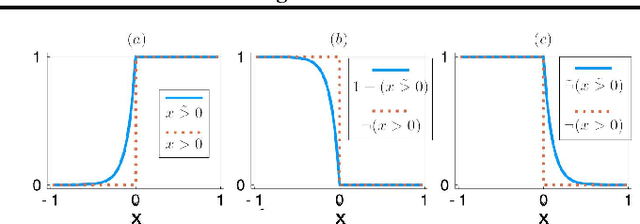
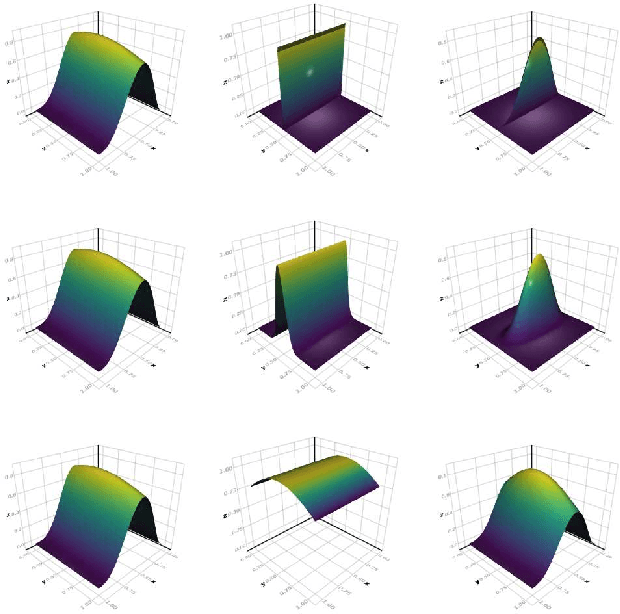
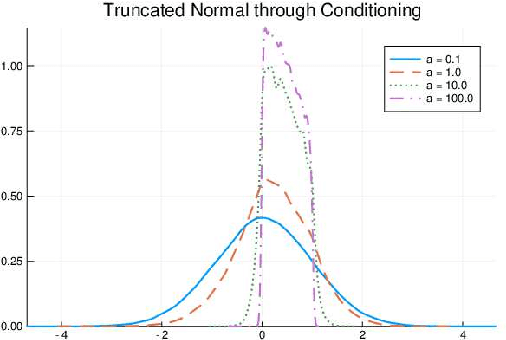
We develop a likelihood free inference procedure for conditioning a probabilistic model on a predicate. A predicate is a Boolean valued function which expresses a yes/no question about a domain. Our contribution, which we call predicate exchange, constructs a softened predicate which takes value in the unit interval [0, 1] as opposed to a simply true or false. Intuitively, 1 corresponds to true, and a high value (such as 0.999) corresponds to "nearly true" as determined by a distance metric. We define Boolean algebra for soft predicates, such that they can be negated, conjoined and disjoined arbitrarily. A softened predicate can serve as a tractable proxy to a likelihood function for approximate posterior inference. However, to target exact inference, we temper the relaxation by a temperature parameter, and add a accept/reject phase use to replica exchange Markov Chain Mont Carlo, which exchanges states between a sequence of models conditioned on predicates at varying temperatures. We describe a lightweight implementation of predicate exchange that it provides a language independent layer that can be implemented on top of existingn modeling formalisms.
Extending Stan for Deep Probabilistic Programming
Sep 30, 2018
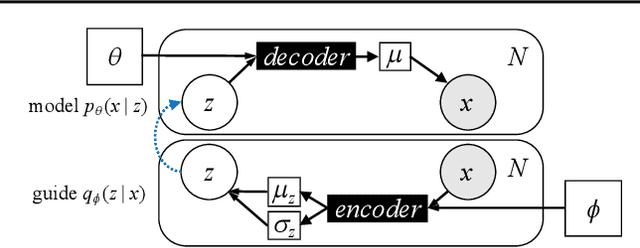

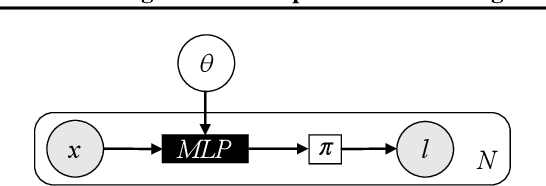
Deep probabilistic programming combines deep neural networks (for automatic hierarchical representation learning) with probabilistic models (for principled handling of uncertainty). Unfortunately, it is difficult to write deep probabilistic models, because existing programming frameworks lack concise, high-level, and clean ways to express them. To ease this task, we extend Stan, a popular high-level probabilistic programming language, to use deep neural networks written in PyTorch. Training deep probabilistic models works best with variational inference, so we also extend Stan for that. We implement these extensions by translating Stan programs to Pyro. Our translation clarifies the relationship between different families of probabilistic programming languages. Overall, our paper is a step towards making deep probabilistic programming easier.
Inference of Users Demographic Attributes based on Homophily in Communication Networks
Aug 01, 2018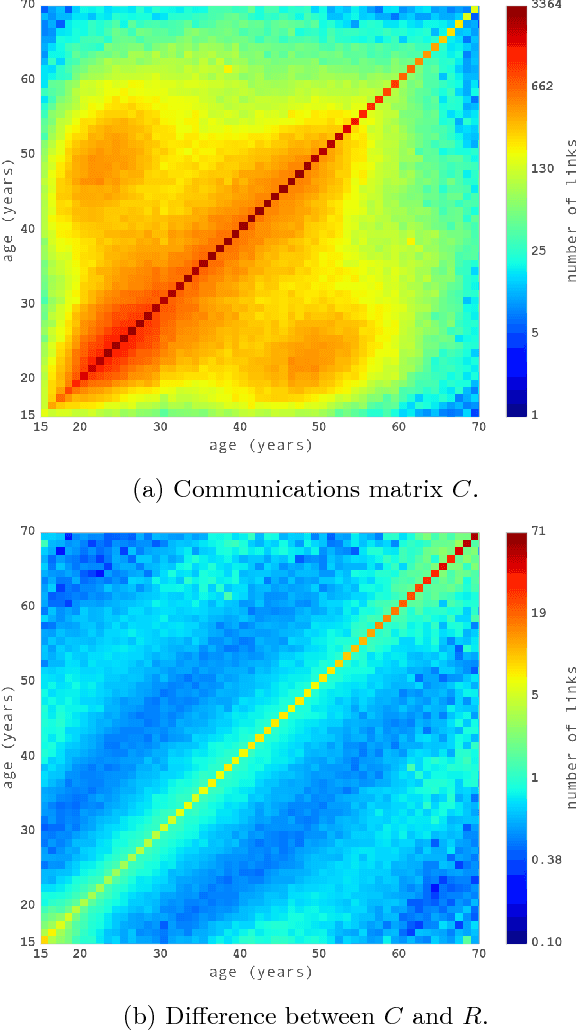
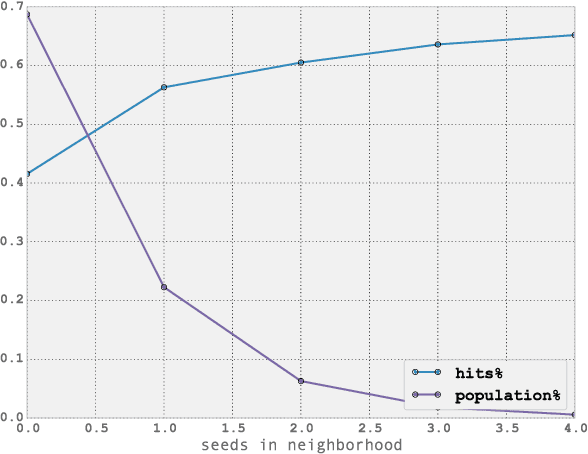
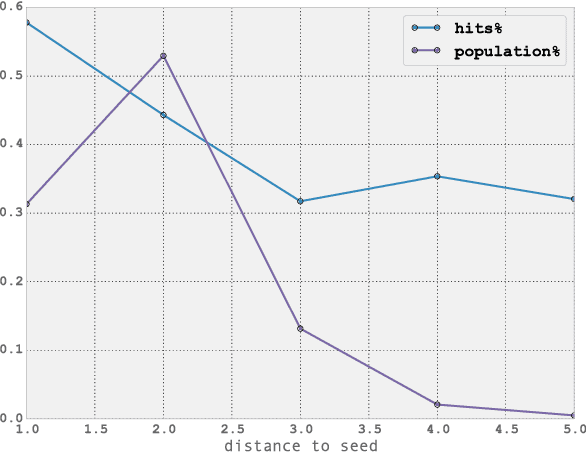
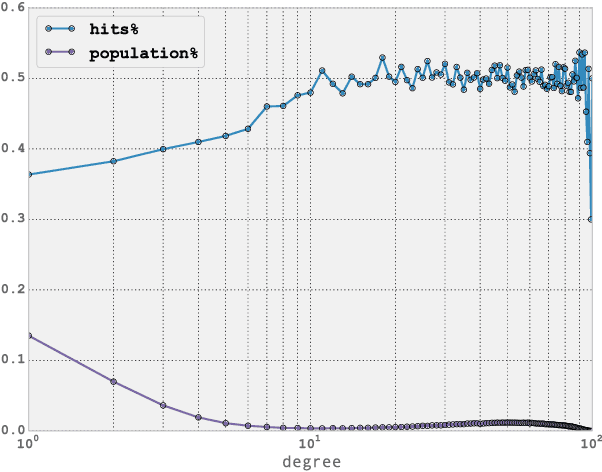
Over the past decade, mobile phones have become prevalent in all parts of the world, across all demographic backgrounds. Mobile phones are used by men and women across a wide age range in both developed and developing countries. Consequently, they have become one of the most important mechanisms for social interaction within a population, making them an increasingly important source of information to understand human demographics and human behaviour. In this work we combine two sources of information: communication logs from a major mobile operator in a Latin American country, and information on the demographics of a subset of the users population. This allows us to perform an observational study of mobile phone usage, differentiated by age groups categories. This study is interesting in its own right, since it provides knowledge on the structure and demographics of the mobile phone market in the studied country. We then tackle the problem of inferring the age group for all users in the network. We present here an exclusively graph-based inference method relying solely on the topological structure of the mobile network, together with a topological analysis of the performance of the algorithm. The equations for our algorithm can be described as a diffusion process with two added properties: (i) memory of its initial state, and (ii) the information is propagated as a probability vector for each node attribute (instead of the value of the attribute itself). Our algorithm can successfully infer different age groups within the network population given known values for a subset of nodes (seed nodes). Most interestingly, we show that by carefully analysing the topological relationships between correctly predicted nodes and the seed nodes, we can characterize particular subsets of nodes for which our inference method has significantly higher accuracy.
Outrepasser les limites des techniques classiques de Prise d'Empreintes grace aux Reseaux de Neurones
Jun 14, 2010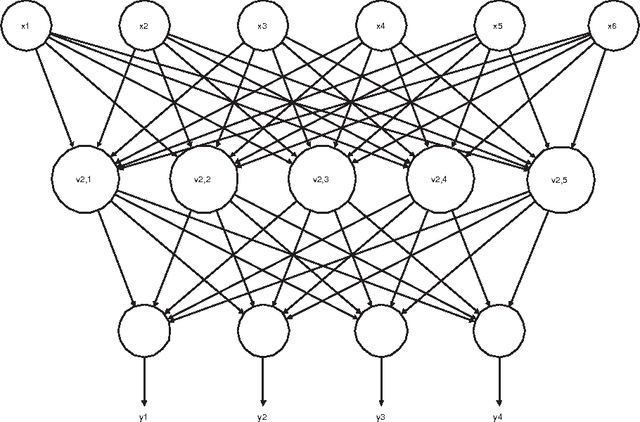
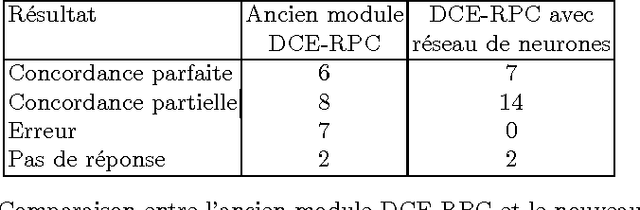
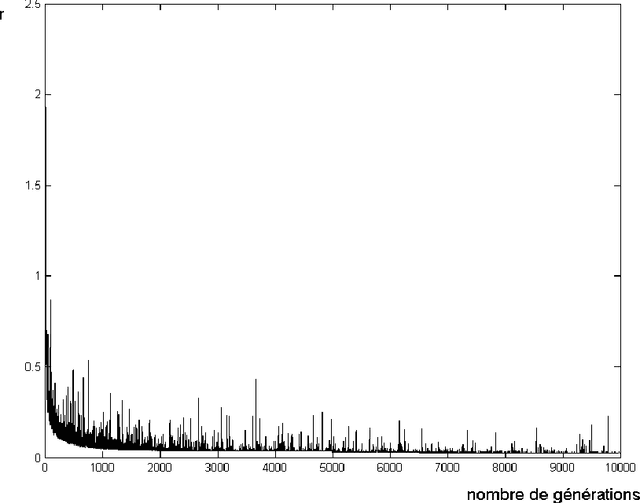

We present an application of Artificial Intelligence techniques to the field of Information Security. The problem of remote Operating System (OS) Detection, also called OS Fingerprinting, is a crucial step of the penetration testing process, since the attacker (hacker or security professional) needs to know the OS of the target host in order to choose the exploits that he will use. OS Detection is accomplished by passively sniffing network packets and actively sending test packets to the target host, to study specific variations in the host responses revealing information about its operating system. The first fingerprinting implementations were based on the analysis of differences between TCP/IP stack implementations. The next generation focused the analysis on application layer data such as the DCE RPC endpoint information. Even though more information was analyzed, some variation of the "best fit" algorithm was still used to interpret this new information. Our new approach involves an analysis of the composition of the information collected during the OS identification process to identify key elements and their relations. To implement this approach, we have developed tools using Neural Networks and techniques from the field of Statistics. These tools have been successfully integrated in a commercial software (Core Impact).
* 16 pages, 3 figures. Symposium sur la S\'ecurit\'e des Technologies de l'Information et des Communications (SSTIC), Rennes, France, May 31-June 2, 2006
Using Neural Networks to improve classical Operating System Fingerprinting techniques
Jun 09, 2010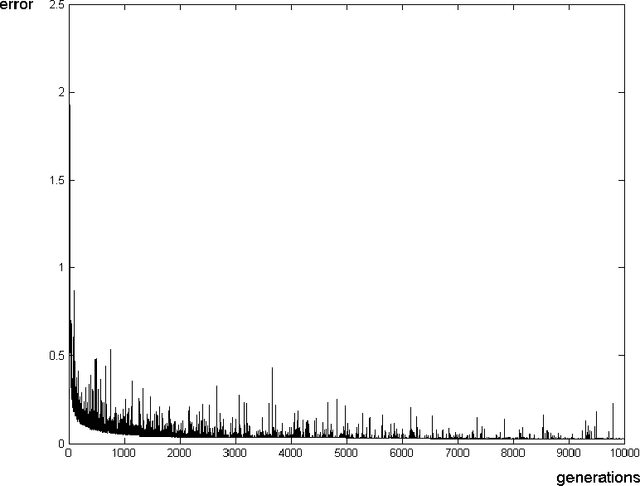
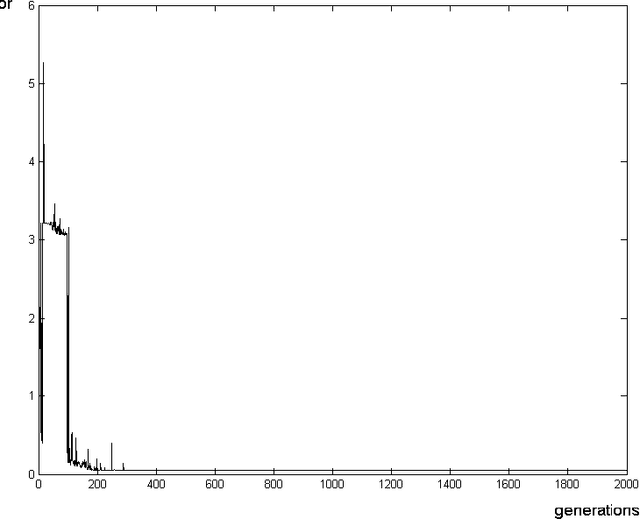
We present remote Operating System detection as an inference problem: given a set of observations (the target host responses to a set of tests), we want to infer the OS type which most probably generated these observations. Classical techniques used to perform this analysis present several limitations. To improve the analysis, we have developed tools using neural networks and Statistics tools. We present two working modules: one which uses DCE-RPC endpoints to distinguish Windows versions, and another which uses Nmap signatures to distinguish different version of Windows, Linux, Solaris, OpenBSD, FreeBSD and NetBSD systems. We explain the details of the topology and inner workings of the neural networks used, and the fine tuning of their parameters. Finally we show positive experimental results.