 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatplayinginthesnow: Impact of Prior Segmentation on a Model of Visually Grounded Speech
Jun 15, 2020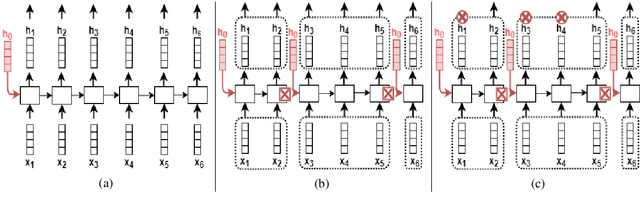

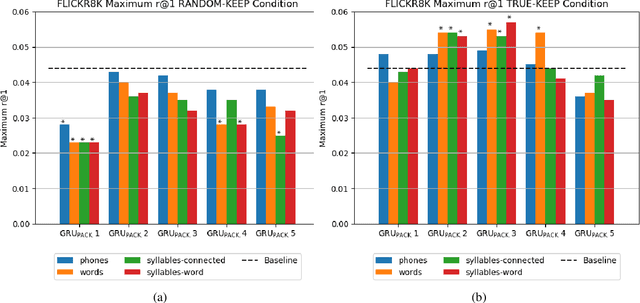
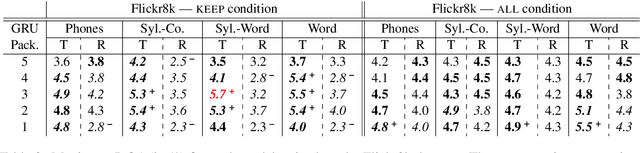
We investigate the effect of introducing phone, syllable, or word boundaries on the performance of a Model of Visually Grounded Speech and compare the results with a model that does not use any boundary information and with a model that uses random boundaries. We introduce a simple way to introduce such information in an RNN-based model and investigate which type of boundary enables a better mapping between an image and its spoken description. We also explore where, that is, at which level of the network's architecture such information should be introduced. We show that using a segmentation that results in syllable-like or word-like segments and that respects word boundaries are the most efficient. Also, we show that a linguistically informed subsampling is more efficient than a random subsampling. Finally, we show that using a hierarchical segmentation, by first using a phone segmentation and recomposing words from the phone units yields better results than either using a phone or word segmentation in isolation.
Word Recognition, Competition, and Activation in a Model of Visually Grounded Speech
Sep 18, 2019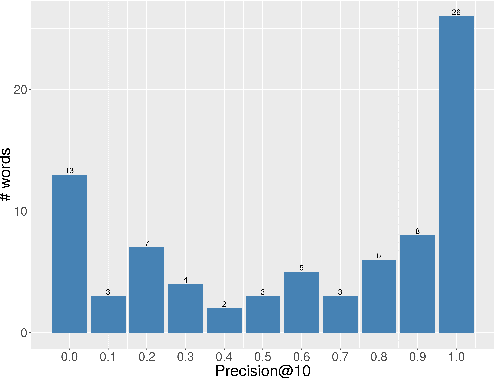
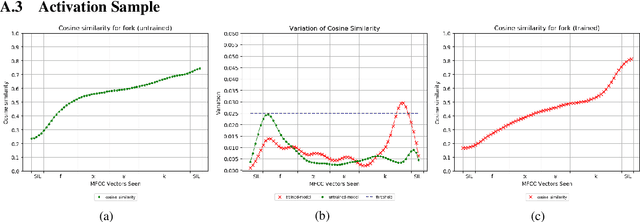
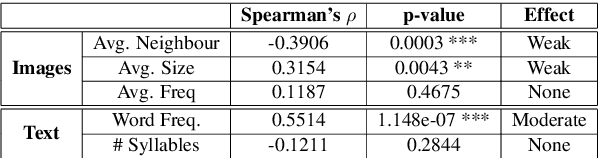
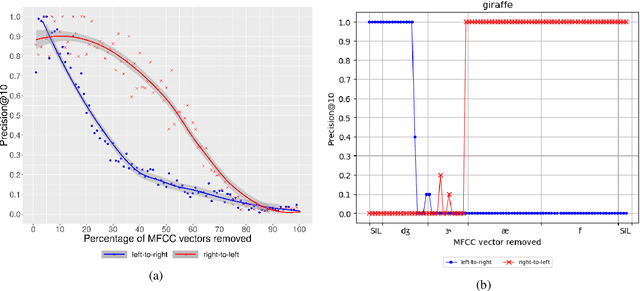
In this paper, we study how word-like units are represented and activated in a recurrent neural model of visually grounded speech. The model used in our experiments is trained to project an image and its spoken description in a common representation space. We show that a recurrent model trained on spoken sentences implicitly segments its input into word-like units and reliably maps them to their correct visual referents. We introduce a methodology originating from linguistics to analyse the representation learned by neural networks -- the gating paradigm -- and show that the correct representation of a word is only activated if the network has access to first phoneme of the target word, suggesting that the network does not rely on a global acoustic pattern. Furthermore, we find out that not all speech frames (MFCC vectors in our case) play an equal role in the final encoded representation of a given word, but that some frames have a crucial effect on it. Finally, we suggest that word representation could be activated through a process of lexical competition.
Models of Visually Grounded Speech Signal Pay Attention To Nouns: a Bilingual Experiment on English and Japanese
Feb 08, 2019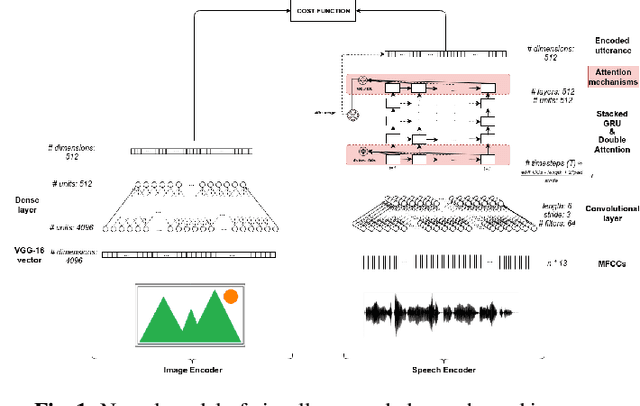



We investigate the behaviour of attention in neural models of visually grounded speech trained on two languages: English and Japanese. Experimental results show that attention focuses on nouns and this behaviour holds true for two very typologically different languages. We also draw parallels between artificial neural attention and human attention and show that neural attention focuses on word endings as it has been theorised for human attention. Finally, we investigate how two visually grounded monolingual models can be used to perform cross-lingual speech-to-speech retrieval. For both languages, the enriched bilingual (speech-image) corpora with part-of-speech tags and forced alignments are distributed to the community for reproducible research.
Socioeconomic Dependencies of Linguistic Patterns in Twitter: A Multivariate Analysis
Apr 03, 2018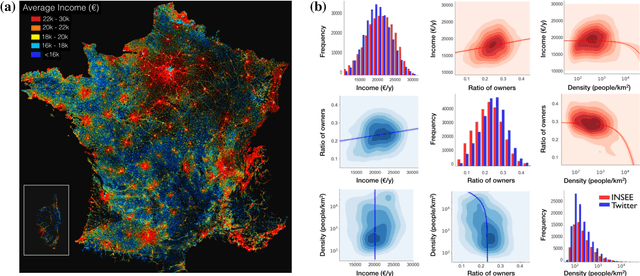
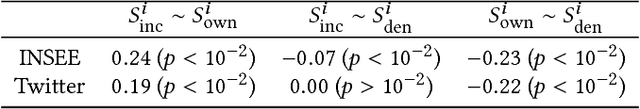
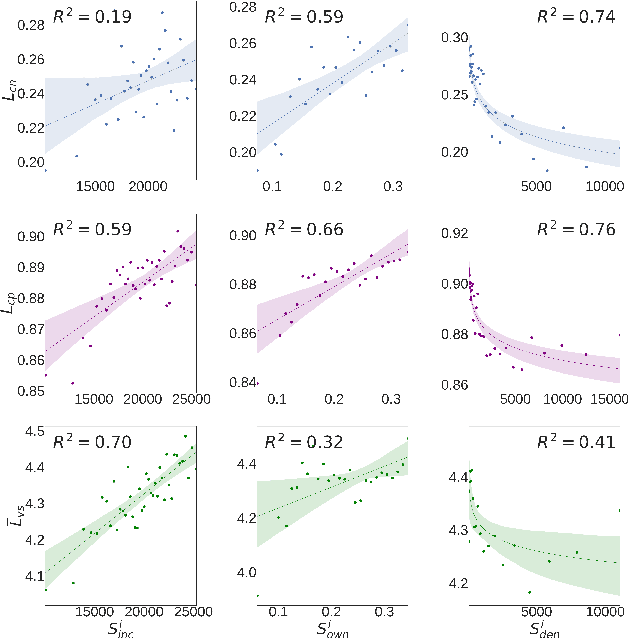
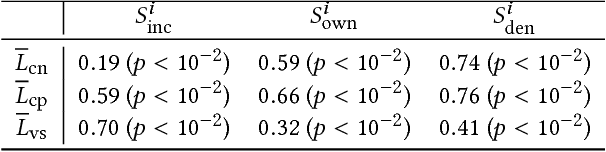
Our usage of language is not solely reliant on cognition but is arguably determined by myriad external factors leading to a global variability of linguistic patterns. This issue, which lies at the core of sociolinguistics and is backed by many small-scale studies on face-to-face communication, is addressed here by constructing a dataset combining the largest French Twitter corpus to date with detailed socioeconomic maps obtained from national census in France. We show how key linguistic variables measured in individual Twitter streams depend on factors like socioeconomic status, location, time, and the social network of individuals. We found that (i) people of higher socioeconomic status, active to a greater degree during the daytime, use a more standard language; (ii) the southern part of the country is more prone to use more standard language than the northern one, while locally the used variety or dialect is determined by the spatial distribution of socioeconomic status; and (iii) individuals connected in the social network are closer linguistically than disconnected ones, even after the effects of status homophily have been removed. Our results inform sociolinguistic theory and may inspire novel learning methods for the inference of socioeconomic status of people from the way they tweet.