 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModels of Visually Grounded Speech Signal Pay Attention To Nouns: a Bilingual Experiment on English and Japanese
Paper and Code
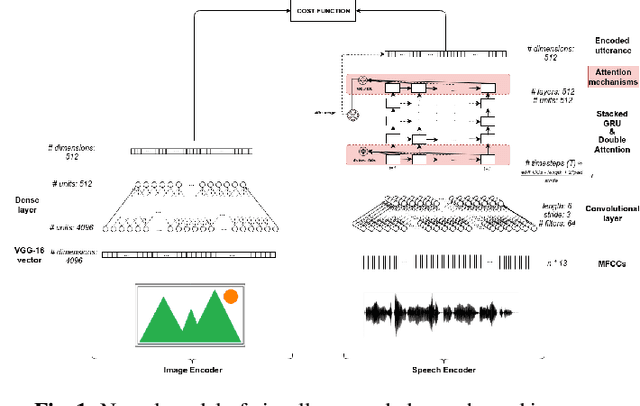



We investigate the behaviour of attention in neural models of visually grounded speech trained on two languages: English and Japanese. Experimental results show that attention focuses on nouns and this behaviour holds true for two very typologically different languages. We also draw parallels between artificial neural attention and human attention and show that neural attention focuses on word endings as it has been theorised for human attention. Finally, we investigate how two visually grounded monolingual models can be used to perform cross-lingual speech-to-speech retrieval. For both languages, the enriched bilingual (speech-image) corpora with part-of-speech tags and forced alignments are distributed to the community for reproducible research.