 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocioeconomic correlations of urban patterns inferred from aerial images: interpreting activation maps of Convolutional Neural Networks
Apr 10, 2020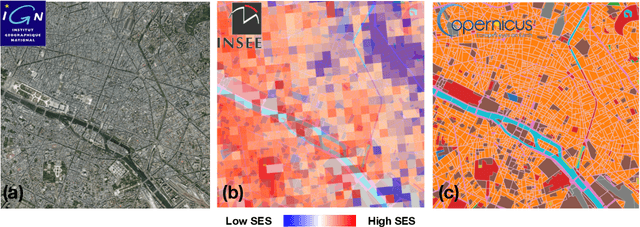
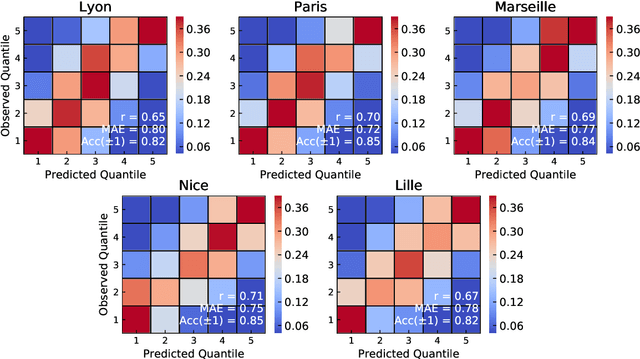
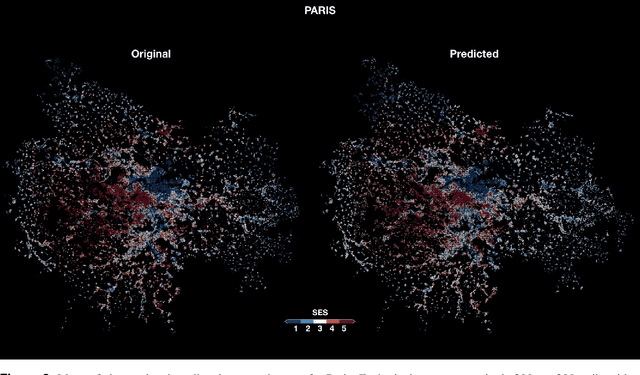

Urbanisation is a great challenge for modern societies, promising better access to economic opportunities while widening socioeconomic inequalities. Accurately tracking how this process unfolds has been challenging for traditional data collection methods, while remote sensing information offers an alternative to gather a more complete view on these societal changes. By feeding a neural network with satellite images one may recover the socioeconomic information associated to that area, however these models lack to explain how visual features contained in a sample, trigger a given prediction. Here we close this gap by predicting socioeconomic status across France from aerial images and interpreting class activation mappings in terms of urban topology. We show that the model disregards the spatial correlations existing between urban class and socioeconomic status to derive its predictions. These results pave the way to build interpretable models, which may help to better track and understand urbanisation and its consequences.
Joint embedding of structure and features via graph convolutional networks
May 23, 2019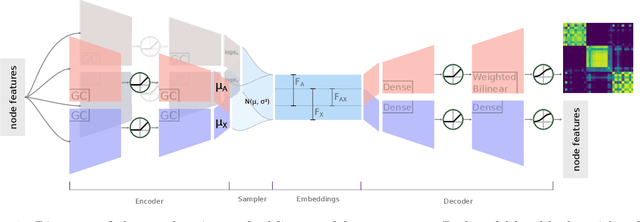
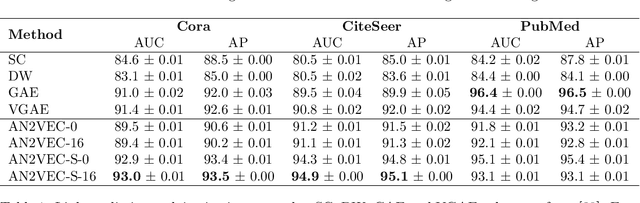
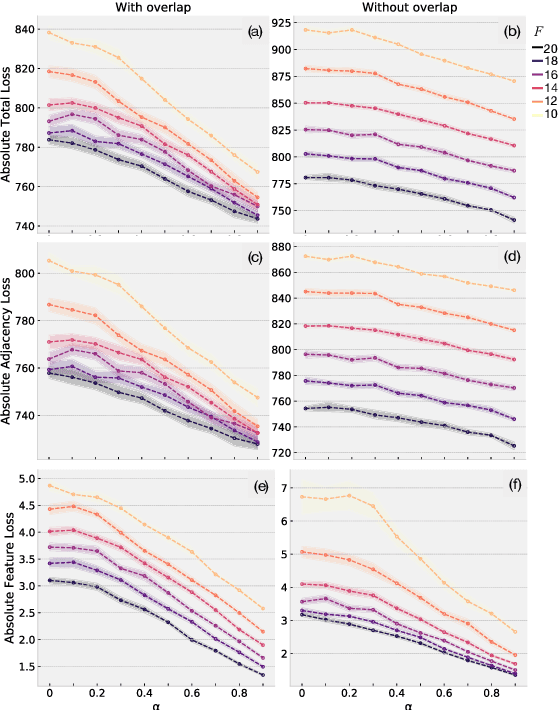
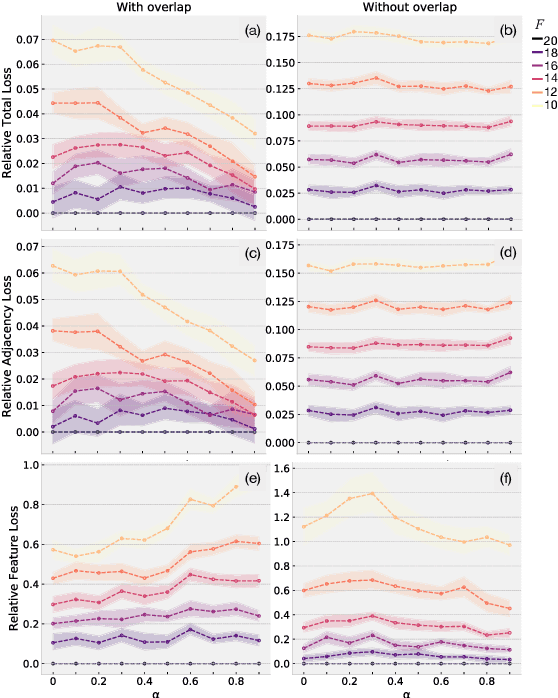
The creation of social ties is largely determined by the entangled effects of people's similarities in terms of individual characters and friends. However, feature and structural characters of people usually appear to be correlated, making it difficult to determine which has greater responsibility in the formation of the emergent network structure. We propose \emph{AN2VEC}, a node embedding method which ultimately aims at disentangling the information shared by the structure of a network and the features of its nodes. Building on the recent developments of Graph Convolutional Networks (GCN), we develop a multitask GCN Variational Autoencoder where different dimensions of the generated embeddings can be dedicated to encoding feature information, network structure, and shared feature-network information. We explore the interaction between these disentangled characters by comparing the embedding reconstruction performance to a baseline case where no shared information is extracted. We use synthetic datasets with different levels of interdependency between feature and network characters and show (i) that shallow embeddings relying on shared information perform better than the corresponding reference with unshared information, (ii) that this performance gap increases with the correlation between network and feature structure, and (iii) that our embedding is able to capture joint information of structure and features. Our method can be relevant for the analysis and prediction of any featured network structure ranging from online social systems to network medicine.
Socioeconomic Dependencies of Linguistic Patterns in Twitter: A Multivariate Analysis
Apr 03, 2018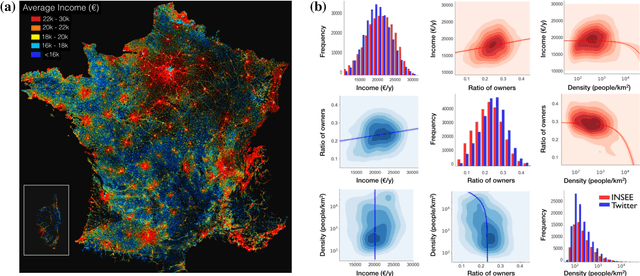
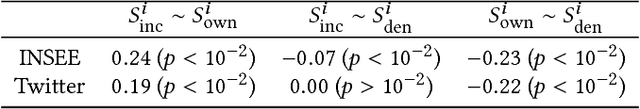
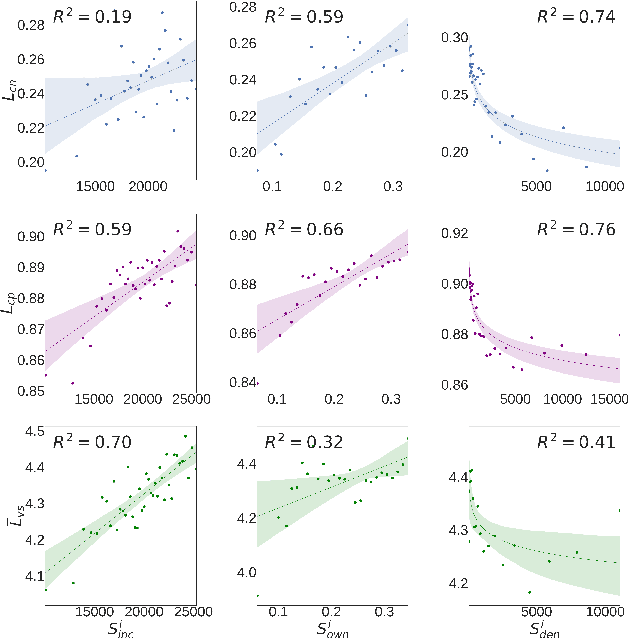
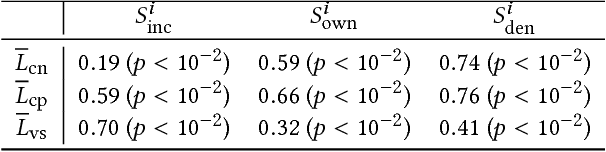
Our usage of language is not solely reliant on cognition but is arguably determined by myriad external factors leading to a global variability of linguistic patterns. This issue, which lies at the core of sociolinguistics and is backed by many small-scale studies on face-to-face communication, is addressed here by constructing a dataset combining the largest French Twitter corpus to date with detailed socioeconomic maps obtained from national census in France. We show how key linguistic variables measured in individual Twitter streams depend on factors like socioeconomic status, location, time, and the social network of individuals. We found that (i) people of higher socioeconomic status, active to a greater degree during the daytime, use a more standard language; (ii) the southern part of the country is more prone to use more standard language than the northern one, while locally the used variety or dialect is determined by the spatial distribution of socioeconomic status; and (iii) individuals connected in the social network are closer linguistically than disconnected ones, even after the effects of status homophily have been removed. Our results inform sociolinguistic theory and may inspire novel learning methods for the inference of socioeconomic status of people from the way they tweet.