 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Diffusion-Based Approach for Human De-Occlusion
Aug 18, 2025



Humans can infer the missing parts of an occluded object by leveraging prior knowledge and visible cues. However, enabling deep learning models to accurately predict such occluded regions remains a challenging task. De-occlusion addresses this problem by reconstructing both the mask and RGB appearance. In this work, we focus on human de-occlusion, specifically targeting the recovery of occluded body structures and appearances. Our approach decomposes the task into two stages: mask completion and RGB completion. The first stage leverages a diffusion-based human body prior to provide a comprehensive representation of body structure, combined with occluded joint heatmaps that offer explicit spatial cues about missing regions. The reconstructed amodal mask then serves as a conditioning input for the second stage, guiding the model on which areas require RGB reconstruction. To further enhance RGB generation, we incorporate human-specific textual features derived using a visual question answering (VQA) model and encoded via a CLIP encoder. RGB completion is performed using Stable Diffusion, with decoder fine-tuning applied to mitigate pixel-level degradation in visible regions -- a known limitation of prior diffusion-based de-occlusion methods caused by latent space transformations. Our method effectively reconstructs human appearances even under severe occlusions and consistently outperforms existing methods in both mask and RGB completion. Moreover, the de-occluded images generated by our approach can improve the performance of downstream human-centric tasks, such as 2D pose estimation and 3D human reconstruction. The code will be made publicly available.
PersonaBooth: Personalized Text-to-Motion Generation
Mar 10, 2025This paper introduces Motion Personalization, a new task that generates personalized motions aligned with text descriptions using several basic motions containing Persona. To support this novel task, we introduce a new large-scale motion dataset called PerMo (PersonaMotion), which captures the unique personas of multiple actors. We also propose a multi-modal finetuning method of a pretrained motion diffusion model called PersonaBooth. PersonaBooth addresses two main challenges: i) A significant distribution gap between the persona-focused PerMo dataset and the pretraining datasets, which lack persona-specific data, and ii) the difficulty of capturing a consistent persona from the motions vary in content (action type). To tackle the dataset distribution gap, we introduce a persona token to accept new persona features and perform multi-modal adaptation for both text and visuals during finetuning. To capture a consistent persona, we incorporate a contrastive learning technique to enhance intra-cohesion among samples with the same persona. Furthermore, we introduce a context-aware fusion mechanism to maximize the integration of persona cues from multiple input motions. PersonaBooth outperforms state-of-the-art motion style transfer methods, establishing a new benchmark for motion personalization.
6DoF Head Pose Estimation through Explicit Bidirectional Interaction with Face Geometry
Jul 19, 2024



This study addresses the nuanced challenge of estimating head translations within the context of six-degrees-of-freedom (6DoF) head pose estimation, placing emphasis on this aspect over the more commonly studied head rotations. Identifying a gap in existing methodologies, we recognized the underutilized potential synergy between facial geometry and head translation. To bridge this gap, we propose a novel approach called the head Translation, Rotation, and face Geometry network (TRG), which stands out for its explicit bidirectional interaction structure. This structure has been carefully designed to leverage the complementary relationship between face geometry and head translation, marking a significant advancement in the field of head pose estimation. Our contributions also include the development of a strategy for estimating bounding box correction parameters and a technique for aligning landmarks to image. Both of these innovations demonstrate superior performance in 6DoF head pose estimation tasks. Extensive experiments conducted on ARKitFace and BIWI datasets confirm that the proposed method outperforms current state-of-the-art techniques. Codes are released at https://github.com/asw91666/TRG-Release.
Representation learning of vertex heatmaps for 3D human mesh reconstruction from multi-view images
Jun 29, 2023



This study addresses the problem of 3D human mesh reconstruction from multi-view images. Recently, approaches that directly estimate the skinned multi-person linear model (SMPL)-based human mesh vertices based on volumetric heatmap representation from input images have shown good performance. We show that representation learning of vertex heatmaps using an autoencoder helps improve the performance of such approaches. Vertex heatmap autoencoder (VHA) learns the manifold of plausible human meshes in the form of latent codes using AMASS, which is a large-scale motion capture dataset. Body code predictor (BCP) utilizes the learned body prior from VHA for human mesh reconstruction from multi-view images through latent code-based supervision and transfer of pretrained weights. According to experiments on Human3.6M and LightStage datasets, the proposed method outperforms previous methods and achieves state-of-the-art human mesh reconstruction performance.
Learnable human mesh triangulation for 3D human pose and shape estimation
Aug 24, 2022

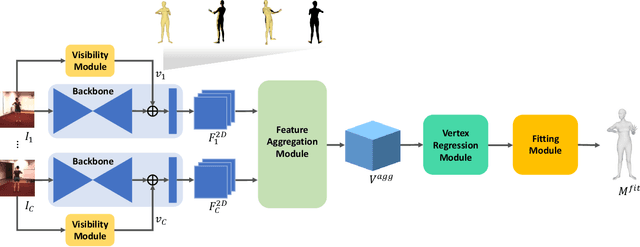

Compared to joint position, the accuracy of joint rotation and shape estimation has received relatively little attention in the skinned multi-person linear model (SMPL)-based human mesh reconstruction from multi-view images. The work in this field is broadly classified into two categories. The first approach performs joint estimation and then produces SMPL parameters by fitting SMPL to resultant joints. The second approach regresses SMPL parameters directly from the input images through a convolutional neural network (CNN)-based model. However, these approaches suffer from the lack of information for resolving the ambiguity of joint rotation and shape reconstruction and the difficulty of network learning. To solve the aforementioned problems, we propose a two-stage method. The proposed method first estimates the coordinates of mesh vertices through a CNN-based model from input images, and acquires SMPL parameters by fitting the SMPL model to the estimated vertices. Estimated mesh vertices provide sufficient information for determining joint rotation and shape, and are easier to learn than SMPL parameters. According to experiments using Human3.6M and MPI-INF-3DHP datasets, the proposed method significantly outperforms the previous works in terms of joint rotation and shape estimation, and achieves competitive performance in terms of joint location estimation.
Camera Motion Agnostic 3D Human Pose Estimation
Dec 01, 2021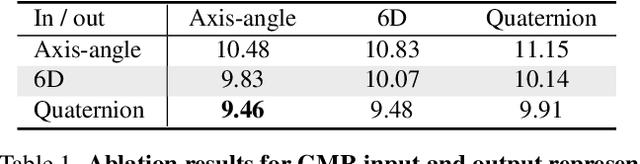

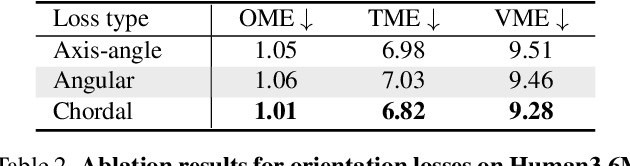
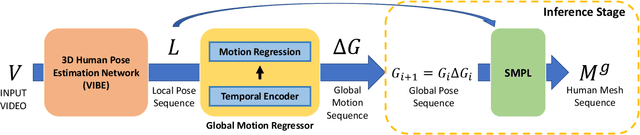
Although the performance of 3D human pose and shape estimation methods has improved significantly in recent years, existing approaches typically generate 3D poses defined in camera or human-centered coordinate system. This makes it difficult to estimate a person's pure pose and motion in world coordinate system for a video captured using a moving camera. To address this issue, this paper presents a camera motion agnostic approach for predicting 3D human pose and mesh defined in the world coordinate system. The core idea of the proposed approach is to estimate the difference between two adjacent global poses (i.e., global motion) that is invariant to selecting the coordinate system, instead of the global pose coupled to the camera motion. To this end, we propose a network based on bidirectional gated recurrent units (GRUs) that predicts the global motion sequence from the local pose sequence consisting of relative rotations of joints called global motion regressor (GMR). We use 3DPW and synthetic datasets, which are constructed in a moving-camera environment, for evaluation. We conduct extensive experiments and prove the effectiveness of the proposed method empirically. Code and datasets are available at https://github.com/seonghyunkim1212/GMR
Beyond Static Features for Temporally Consistent 3D Human Pose and Shape from a Video
Nov 26, 2020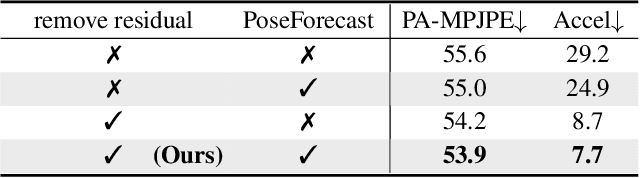



Despite the recent success of single image-based 3D human pose and shape estimation methods, recovering temporally consistent and smooth 3D human motion from a video is still challenging. Several video-based methods have been proposed; however, they fail to resolve the single image-based methods' temporal inconsistency issue due to a strong dependency on a static feature of the current frame. In this regard, we present a temporally consistent mesh recovery system (TCMR). It effectively focuses on the past and future frames' temporal information without being dominated by the current static feature. Our TCMR significantly outperforms previous video-based methods in temporal consistency with better per-frame 3D pose and shape accuracy. We will release the codes. Demo video: https://www.youtube.com/watch?v=WB3nTnSQDII&t=7s&ab_channel=%EC%B5%9C%ED%99%8D%EC%84%9D
AbsPoseLifter: Absolute 3D Human Pose Lifting Network from a Single Noisy 2D Human Pose
Oct 26, 2019



This study presents a new network (i.e., AbsPoseLifter) that lifts a 2D human pose to an absolute 3D pose in a camera coordinate system. The proposed network estimates the absolute 3D location of a target subject and also outputs a considerably improved 3D relative pose estimation compared with those of existing pose lifting methods. We also propose using our AbsPoseLifter with a 2D pose estimator in a cascade fashion to estimate 3D human pose from a single RGB image. In this case, we empirically prove that using realistic 2D poses synthesized with the real error distribution of 2D body joints considerably improves the performance of our AbsPoseLifter. The proposed method is applied to public datasets to achieve state-of-the-art 2D-to-3D pose lifting and 3D human pose estimation.
Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image
Aug 17, 2019



Although significant improvement has been achieved recently in 3D human pose estimation, most of the previous methods only treat a single-person case. In this work, we firstly propose a fully learning-based, camera distance-aware top-down approach for 3D multi-person pose estimation from a single RGB image. The pipeline of the proposed system consists of human detection, absolute 3D human root localization, and root-relative 3D single-person pose estimation modules. Our system achieves comparable results with the state-of-the-art 3D single-person pose estimation models without any groundtruth information and significantly outperforms previous 3D multi-person pose estimation methods on publicly available datasets. The code is available in https://github.com/mks0601/3DMPPE_ROOTNET_RELEASE , https://github.com/mks0601/3DMPPE_POSENET_RELEASE.
Multi-scale Aggregation R-CNN for 2D Multi-person Pose Estimation
May 10, 2019


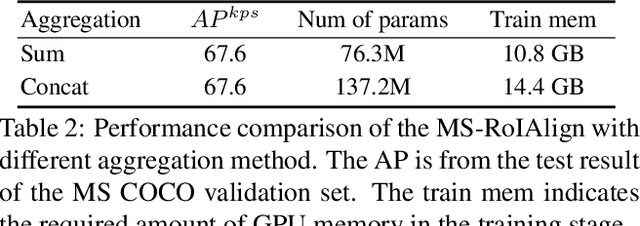
Multi-person pose estimation from a 2D image is challenging because it requires not only keypoint localization but also human detection. In state-of-the-art top-down methods, multi-scale information is a crucial factor for the accurate pose estimation because it contains both of local information around the keypoints and global information of the entire person. Although multi-scale information allows these methods to achieve the state-of-the-art performance, the top-down methods still require a huge amount of computation because they need to use an additional human detector to feed the cropped human image to their pose estimation model. To effectively utilize multi-scale information with the smaller computation, we propose a multi-scale aggregation R-CNN (MSA R-CNN). It consists of multi-scale RoIAlign block (MS-RoIAlign) and multi-scale keypoint head network (MS-KpsNet) which are designed to effectively utilize multi-scale information. Also, in contrast to previous top-down methods, the MSA R-CNN performs human detection and keypoint localization in a single model, which results in reduced computation. The proposed model achieved the best performance among single model-based methods and its results are comparable to those of separated model-based methods with a smaller amount of computation on the publicly available 2D multi-person keypoint localization dataset.