 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6DoF Head Pose Estimation through Explicit Bidirectional Interaction with Face Geometry
Jul 19, 2024



This study addresses the nuanced challenge of estimating head translations within the context of six-degrees-of-freedom (6DoF) head pose estimation, placing emphasis on this aspect over the more commonly studied head rotations. Identifying a gap in existing methodologies, we recognized the underutilized potential synergy between facial geometry and head translation. To bridge this gap, we propose a novel approach called the head Translation, Rotation, and face Geometry network (TRG), which stands out for its explicit bidirectional interaction structure. This structure has been carefully designed to leverage the complementary relationship between face geometry and head translation, marking a significant advancement in the field of head pose estimation. Our contributions also include the development of a strategy for estimating bounding box correction parameters and a technique for aligning landmarks to image. Both of these innovations demonstrate superior performance in 6DoF head pose estimation tasks. Extensive experiments conducted on ARKitFace and BIWI datasets confirm that the proposed method outperforms current state-of-the-art techniques. Codes are released at https://github.com/asw91666/TRG-Release.
Representation learning of vertex heatmaps for 3D human mesh reconstruction from multi-view images
Jun 29, 2023



This study addresses the problem of 3D human mesh reconstruction from multi-view images. Recently, approaches that directly estimate the skinned multi-person linear model (SMPL)-based human mesh vertices based on volumetric heatmap representation from input images have shown good performance. We show that representation learning of vertex heatmaps using an autoencoder helps improve the performance of such approaches. Vertex heatmap autoencoder (VHA) learns the manifold of plausible human meshes in the form of latent codes using AMASS, which is a large-scale motion capture dataset. Body code predictor (BCP) utilizes the learned body prior from VHA for human mesh reconstruction from multi-view images through latent code-based supervision and transfer of pretrained weights. According to experiments on Human3.6M and LightStage datasets, the proposed method outperforms previous methods and achieves state-of-the-art human mesh reconstruction performance.
Learnable human mesh triangulation for 3D human pose and shape estimation
Aug 24, 2022

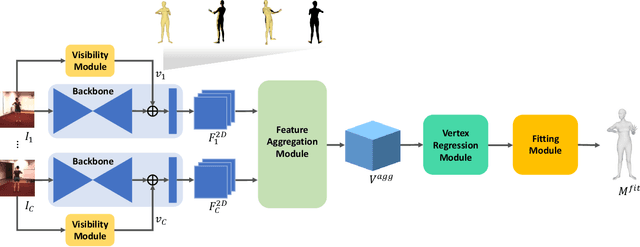

Compared to joint position, the accuracy of joint rotation and shape estimation has received relatively little attention in the skinned multi-person linear model (SMPL)-based human mesh reconstruction from multi-view images. The work in this field is broadly classified into two categories. The first approach performs joint estimation and then produces SMPL parameters by fitting SMPL to resultant joints. The second approach regresses SMPL parameters directly from the input images through a convolutional neural network (CNN)-based model. However, these approaches suffer from the lack of information for resolving the ambiguity of joint rotation and shape reconstruction and the difficulty of network learning. To solve the aforementioned problems, we propose a two-stage method. The proposed method first estimates the coordinates of mesh vertices through a CNN-based model from input images, and acquires SMPL parameters by fitting the SMPL model to the estimated vertices. Estimated mesh vertices provide sufficient information for determining joint rotation and shape, and are easier to learn than SMPL parameters. According to experiments using Human3.6M and MPI-INF-3DHP datasets, the proposed method significantly outperforms the previous works in terms of joint rotation and shape estimation, and achieves competitive performance in terms of joint location estimation.