 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation learning of vertex heatmaps for 3D human mesh reconstruction from multi-view images
Jun 29, 2023



This study addresses the problem of 3D human mesh reconstruction from multi-view images. Recently, approaches that directly estimate the skinned multi-person linear model (SMPL)-based human mesh vertices based on volumetric heatmap representation from input images have shown good performance. We show that representation learning of vertex heatmaps using an autoencoder helps improve the performance of such approaches. Vertex heatmap autoencoder (VHA) learns the manifold of plausible human meshes in the form of latent codes using AMASS, which is a large-scale motion capture dataset. Body code predictor (BCP) utilizes the learned body prior from VHA for human mesh reconstruction from multi-view images through latent code-based supervision and transfer of pretrained weights. According to experiments on Human3.6M and LightStage datasets, the proposed method outperforms previous methods and achieves state-of-the-art human mesh reconstruction performance.
Learnable human mesh triangulation for 3D human pose and shape estimation
Aug 24, 2022

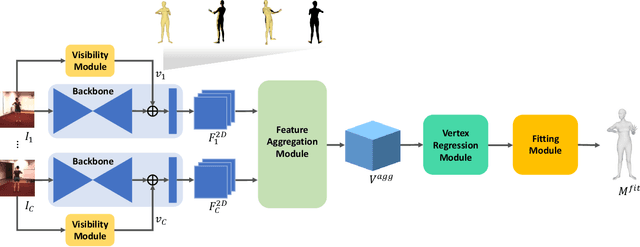

Compared to joint position, the accuracy of joint rotation and shape estimation has received relatively little attention in the skinned multi-person linear model (SMPL)-based human mesh reconstruction from multi-view images. The work in this field is broadly classified into two categories. The first approach performs joint estimation and then produces SMPL parameters by fitting SMPL to resultant joints. The second approach regresses SMPL parameters directly from the input images through a convolutional neural network (CNN)-based model. However, these approaches suffer from the lack of information for resolving the ambiguity of joint rotation and shape reconstruction and the difficulty of network learning. To solve the aforementioned problems, we propose a two-stage method. The proposed method first estimates the coordinates of mesh vertices through a CNN-based model from input images, and acquires SMPL parameters by fitting the SMPL model to the estimated vertices. Estimated mesh vertices provide sufficient information for determining joint rotation and shape, and are easier to learn than SMPL parameters. According to experiments using Human3.6M and MPI-INF-3DHP datasets, the proposed method significantly outperforms the previous works in terms of joint rotation and shape estimation, and achieves competitive performance in terms of joint location estimation.
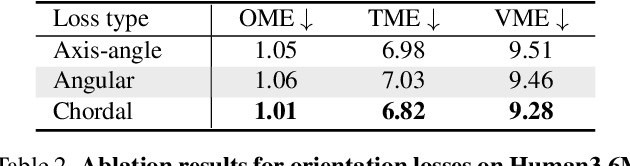
Camera Motion Agnostic 3D Human Pose Estimation
Dec 01, 2021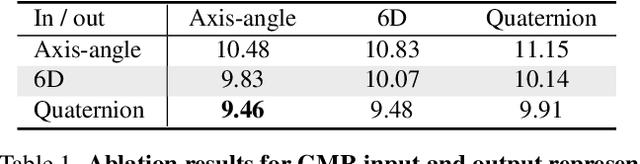

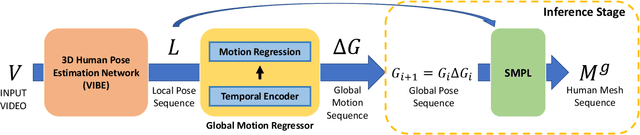
Although the performance of 3D human pose and shape estimation methods has improved significantly in recent years, existing approaches typically generate 3D poses defined in camera or human-centered coordinate system. This makes it difficult to estimate a person's pure pose and motion in world coordinate system for a video captured using a moving camera. To address this issue, this paper presents a camera motion agnostic approach for predicting 3D human pose and mesh defined in the world coordinate system. The core idea of the proposed approach is to estimate the difference between two adjacent global poses (i.e., global motion) that is invariant to selecting the coordinate system, instead of the global pose coupled to the camera motion. To this end, we propose a network based on bidirectional gated recurrent units (GRUs) that predicts the global motion sequence from the local pose sequence consisting of relative rotations of joints called global motion regressor (GMR). We use 3DPW and synthetic datasets, which are constructed in a moving-camera environment, for evaluation. We conduct extensive experiments and prove the effectiveness of the proposed method empirically. Code and datasets are available at https://github.com/seonghyunkim1212/GMR