 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseFix: Model-agnostic General Human Pose Refinement Network
Paper and Code


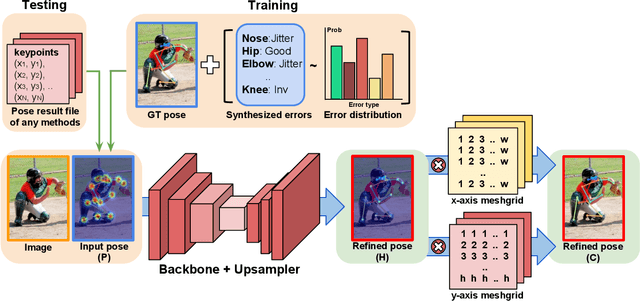
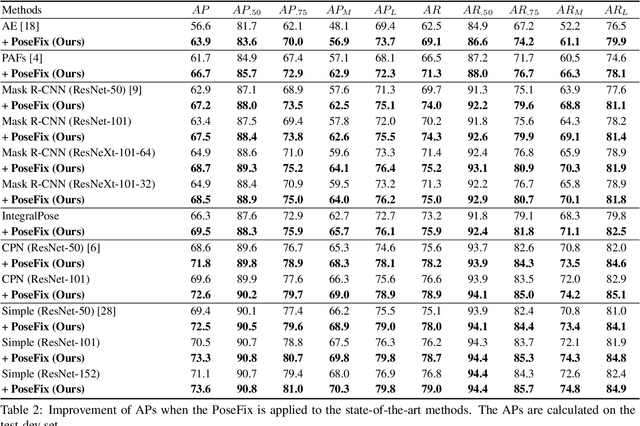
Multi-person pose estimation from a 2D image is an essential technique for human behavior understanding. In this paper, we propose a human pose refinement network that estimates a refined pose from a tuple of an input image and input pose. The pose refinement was performed mainly through an end-to-end trainable multi-stage architecture in previous methods. However, they are highly dependent on pose estimation models and require careful model design. By contrast, we propose a model-agnostic pose refinement method. According to a recent study, state-of-the-art 2D human pose estimation methods have similar error distributions. We use this error statistics as prior information to generate synthetic poses and use the synthesized poses to train our model. In the testing stage, pose estimation results of any other methods can be input to the proposed method. Moreover, the proposed model does not require code or knowledge about other methods, which allows it to be easily used in the post-processing step. We show that the proposed approach achieves better performance than the conventional multi-stage refinement models and consistently improves the performance of various state-of-the-art pose estimation methods on the commonly used benchmark. We will release the code and pre-trained model for easy access.