 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view Monocular Depth and Uncertainty Prediction with Deep SfM in Dynamic Environments
Jan 21, 2022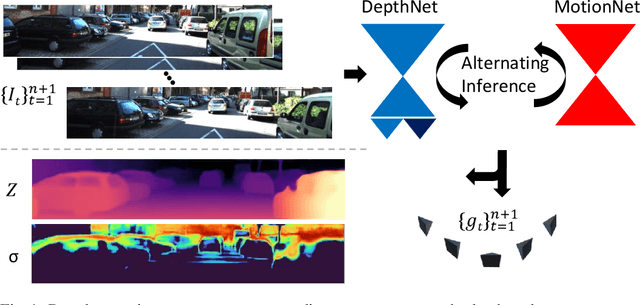
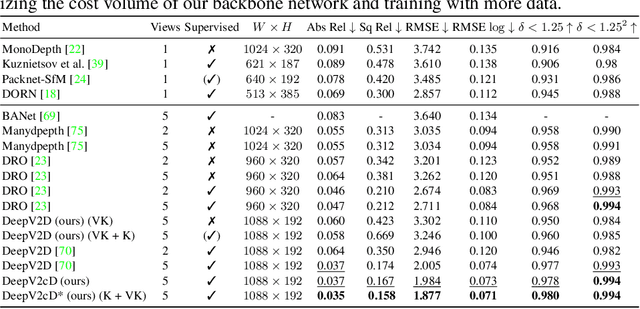
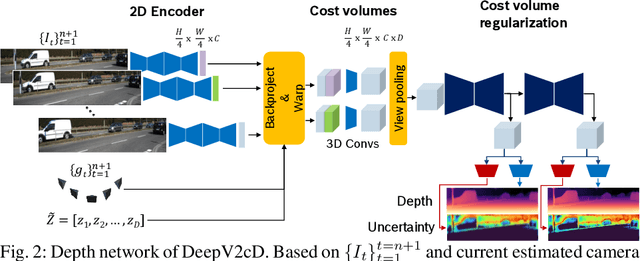
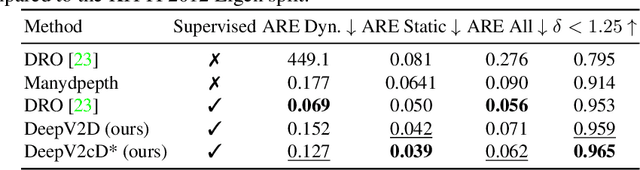
3D reconstruction of depth and motion from monocular video in dynamic environments is a highly ill-posed problem due to scale ambiguities when projecting to the 2D image domain. In this work, we investigate the performance of the current State-of-the-Art (SotA) deep multi-view systems in such environments. We find that current supervised methods work surprisingly well despite not modelling individual object motions, but make systematic errors due to a lack of dense ground truth data. To detect such errors during usage, we extend the cost volume based Deep Video to Depth (DeepV2D) framework \cite{teed2018deepv2d} with a learned uncertainty. Our Deep Video to certain Depth (DeepV2cD) model allows i) to perform en par or better with current SotA and ii) achieve a better uncertainty measure than the naive Shannon entropy. Our experiments show that a simple filter strategy based on the uncertainty can significantly reduce systematic errors. This results in cleaner reconstructions both on static and dynamic parts of the scene.
ETA Prediction with Graph Neural Networks in Google Maps
Aug 25, 2021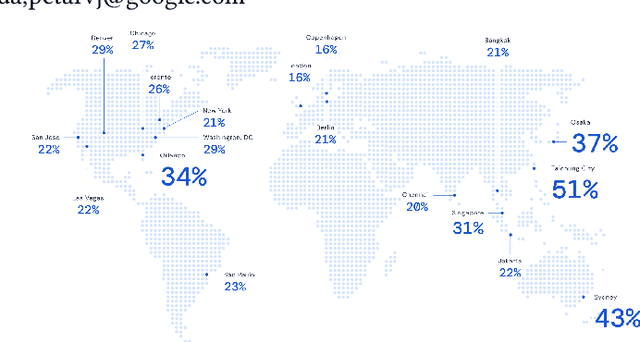


Travel-time prediction constitutes a task of high importance in transportation networks, with web mapping services like Google Maps regularly serving vast quantities of travel time queries from users and enterprises alike. Further, such a task requires accounting for complex spatiotemporal interactions (modelling both the topological properties of the road network and anticipating events -- such as rush hours -- that may occur in the future). Hence, it is an ideal target for graph representation learning at scale. Here we present a graph neural network estimator for estimated time of arrival (ETA) which we have deployed in production at Google Maps. While our main architecture consists of standard GNN building blocks, we further detail the usage of training schedule methods such as MetaGradients in order to make our model robust and production-ready. We also provide prescriptive studies: ablating on various architectural decisions and training regimes, and qualitative analyses on real-world situations where our model provides a competitive edge. Our GNN proved powerful when deployed, significantly reducing negative ETA outcomes in several regions compared to the previous production baseline (40+% in cities like Sydney).
CEREALS - Cost-Effective REgion-based Active Learning for Semantic Segmentation
Oct 23, 2018

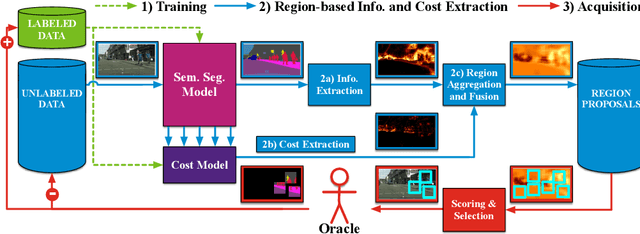
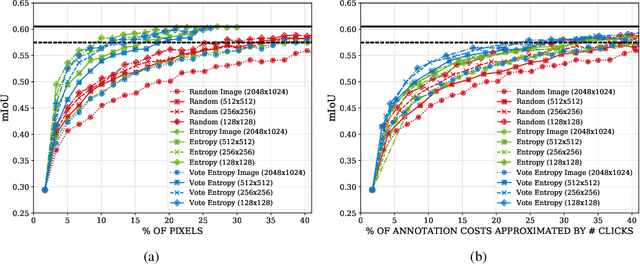
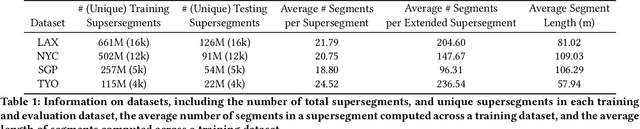
State of the art methods for semantic image segmentation are trained in a supervised fashion using a large corpus of fully labeled training images. However, gathering such a corpus is expensive, due to human annotation effort, in contrast to gathering unlabeled data. We propose an active learning-based strategy, called CEREALS, in which a human only has to hand-label a few, automatically selected, regions within an unlabeled image corpus. This minimizes human annotation effort while maximizing the performance of a semantic image segmentation method. The automatic selection procedure is achieved by: a) using a suitable information measure combined with an estimate about human annotation effort, which is inferred from a learned cost model, and b) exploiting the spatial coherency of an image. The performance of CEREALS is demonstrated on Cityscapes, where we are able to reduce the annotation effort to 17%, while keeping 95% of the mean Intersection over Union (mIoU) of a model that was trained with the fully annotated training set of Cityscapes.