 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Moving Object Segmentation from Monocular Video with Transformers
Nov 28, 2024Moving object detection and segmentation from a single moving camera is a challenging task, requiring an understanding of recognition, motion and 3D geometry. Combining both recognition and reconstruction boils down to a fusion problem, where appearance and motion features need to be combined for classification and segmentation. In this paper, we present a novel fusion architecture for monocular motion segmentation - M3Former, which leverages the strong performance of transformers for segmentation and multi-modal fusion. As reconstructing motion from monocular video is ill-posed, we systematically analyze different 2D and 3D motion representations for this problem and their importance for segmentation performance. Finally, we analyze the effect of training data and show that diverse datasets are required to achieve SotA performance on Kitti and Davis.
* WICCV2023
DROID-Splat: Combining end-to-end SLAM with 3D Gaussian Splatting
Nov 26, 2024



Recent progress in scene synthesis makes standalone SLAM systems purely based on optimizing hyperprimitives with a Rendering objective possible \cite{monogs}. However, the tracking performance still lacks behind traditional \cite{orbslam} and end-to-end SLAM systems \cite{droid}. An optimal trade-off between robustness, speed and accuracy has not yet been reached, especially for monocular video. In this paper, we introduce a SLAM system based on an end-to-end Tracker and extend it with a Renderer based on recent 3D Gaussian Splatting techniques. Our framework \textbf{DroidSplat} achieves both SotA tracking and rendering results on common SLAM benchmarks. We implemented multiple building blocks of modern SLAM systems to run in parallel, allowing for fast inference on common consumer GPU's. Recent progress in monocular depth prediction and camera calibration allows our system to achieve strong results even on in-the-wild data without known camera intrinsics. Code will be available at \url{https://github.com/ChenHoy/DROID-Splat}.
Spatio-Temporal Outdoor Lighting Aggregation on Image Sequences using Transformer Networks
Feb 18, 2022In this work, we focus on outdoor lighting estimation by aggregating individual noisy estimates from images, exploiting the rich image information from wide-angle cameras and/or temporal image sequences. Photographs inherently encode information about the scene's lighting in the form of shading and shadows. Recovering the lighting is an inverse rendering problem and as that ill-posed. Recent work based on deep neural networks has shown promising results for single image lighting estimation, but suffers from robustness. We tackle this problem by combining lighting estimates from several image views sampled in the angular and temporal domain of an image sequence. For this task, we introduce a transformer architecture that is trained in an end-2-end fashion without any statistical post-processing as required by previous work. Thereby, we propose a positional encoding that takes into account the camera calibration and ego-motion estimation to globally register the individual estimates when computing attention between visual words. We show that our method leads to improved lighting estimation while requiring less hyper-parameters compared to the state-of-the-art.
Multi-view Monocular Depth and Uncertainty Prediction with Deep SfM in Dynamic Environments
Jan 21, 2022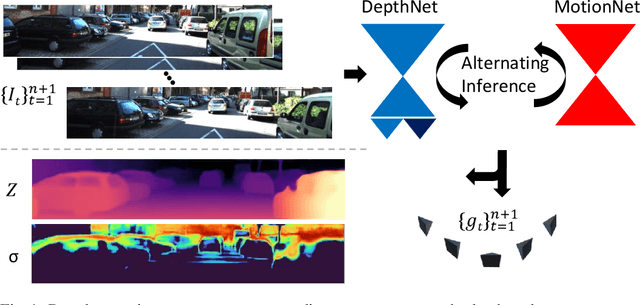
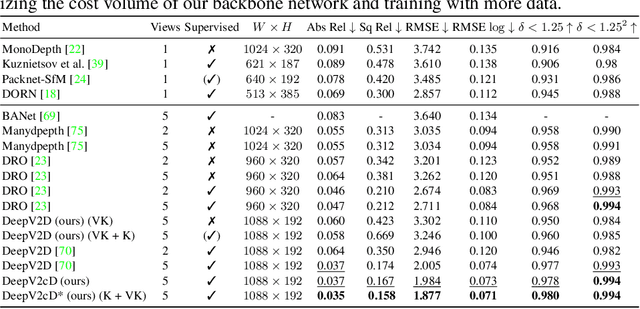
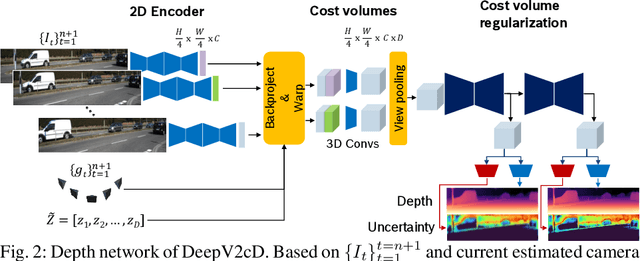
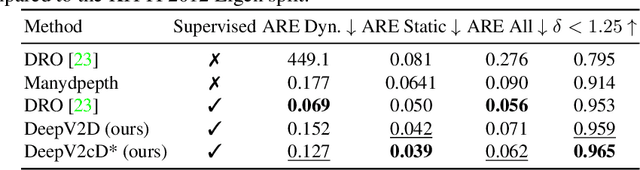
3D reconstruction of depth and motion from monocular video in dynamic environments is a highly ill-posed problem due to scale ambiguities when projecting to the 2D image domain. In this work, we investigate the performance of the current State-of-the-Art (SotA) deep multi-view systems in such environments. We find that current supervised methods work surprisingly well despite not modelling individual object motions, but make systematic errors due to a lack of dense ground truth data. To detect such errors during usage, we extend the cost volume based Deep Video to Depth (DeepV2D) framework \cite{teed2018deepv2d} with a learned uncertainty. Our Deep Video to certain Depth (DeepV2cD) model allows i) to perform en par or better with current SotA and ii) achieve a better uncertainty measure than the naive Shannon entropy. Our experiments show that a simple filter strategy based on the uncertainty can significantly reduce systematic errors. This results in cleaner reconstructions both on static and dynamic parts of the scene.