 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view Monocular Depth and Uncertainty Prediction with Deep SfM in Dynamic Environments
Paper and Code
Jan 21, 2022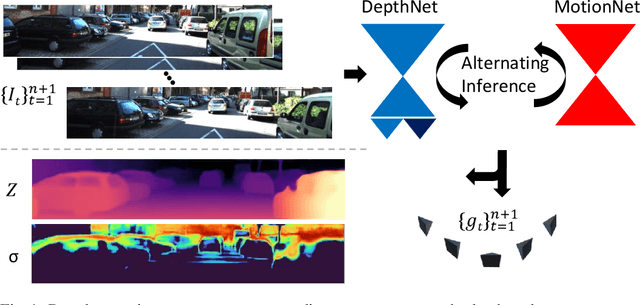
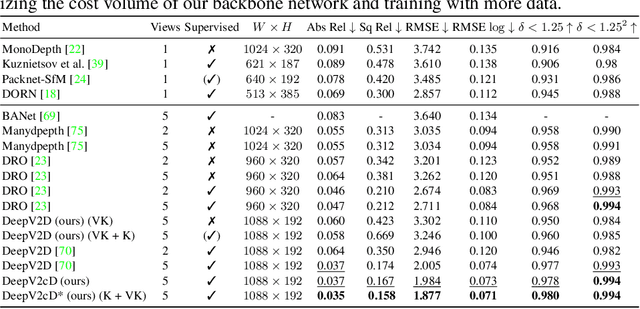
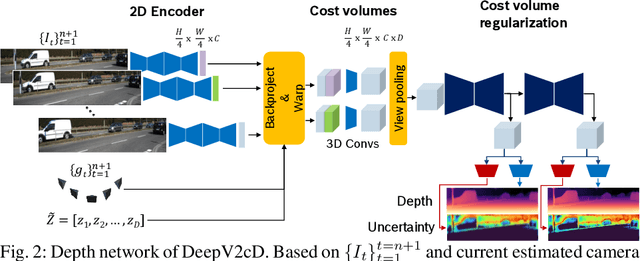
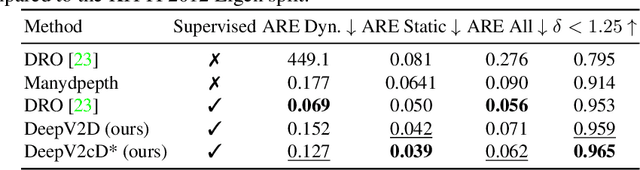
3D reconstruction of depth and motion from monocular video in dynamic environments is a highly ill-posed problem due to scale ambiguities when projecting to the 2D image domain. In this work, we investigate the performance of the current State-of-the-Art (SotA) deep multi-view systems in such environments. We find that current supervised methods work surprisingly well despite not modelling individual object motions, but make systematic errors due to a lack of dense ground truth data. To detect such errors during usage, we extend the cost volume based Deep Video to Depth (DeepV2D) framework \cite{teed2018deepv2d} with a learned uncertainty. Our Deep Video to certain Depth (DeepV2cD) model allows i) to perform en par or better with current SotA and ii) achieve a better uncertainty measure than the naive Shannon entropy. Our experiments show that a simple filter strategy based on the uncertainty can significantly reduce systematic errors. This results in cleaner reconstructions both on static and dynamic parts of the scene.