 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Keyword Spotting through long-range interactions with Temporal Lambda Networks
Apr 16, 2021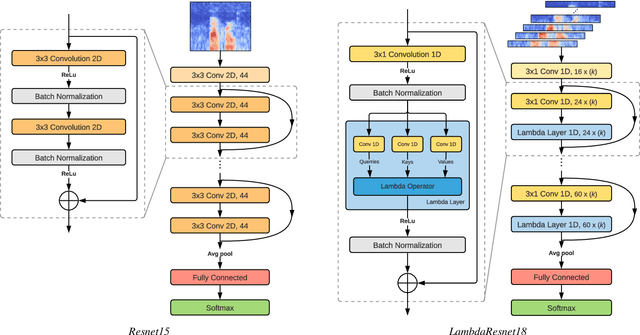
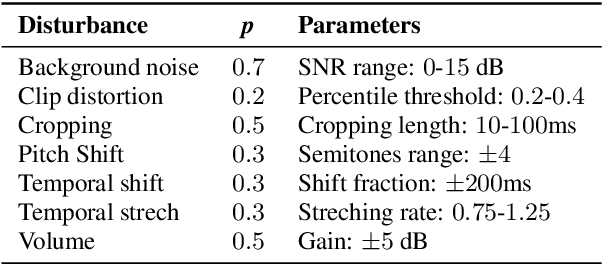
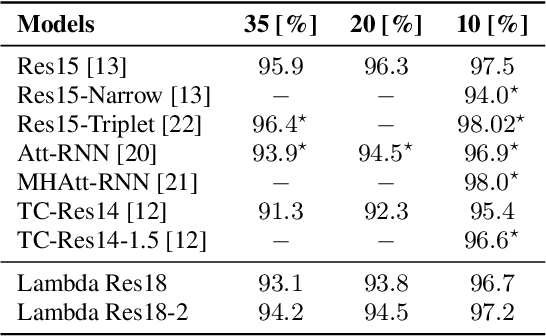
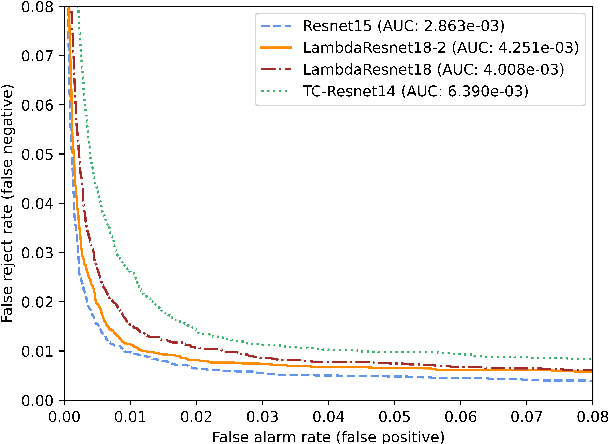
Recent models based on attention mechanisms have shown unprecedented performance in the speech recognition domain. These are computational expensive and unnecessarily complex for the keyword spotting task where its main usage is in small-footprint devices. This work explores the application of the Lambda networks, a framework for capturing long-range interactions, within this spotting task. The proposed architecture is inspired by current state-of-the-art models for keyword spotting built on residual connections. Our main contribution consists on swapping the residual blocks by temporal Lambda layers thus bypassing the expensive computation of attention maps, largely reducing the model complexity. Furthermore, the proposed Lambda network is built upon uni-dimensional convolutions which also dramatically decreases the number of floating point operations performed along the inference stage. This architecture does not only reach state-of-the-art accuracies on the Google Speech Commands dataset, but it is 85% and 65% lighter than its multi headed attention (MHAtt-RNN) and residual convolutional (Res15) counterparts, while being up to 100x faster than them. To the best of our knowledge, this is the first attempt to examine the Lambda framework within the speech domain and therefore, we unravel further research and development of future speech interfaces based on this architecture.