 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Last JITAI? The Unreasonable Effectiveness of Large Language Models in Issuing Just-in-Time Adaptive Interventions: Fostering Physical Activity in a Prospective Cardiac Rehabilitation Setting
Feb 13, 2024



We explored the viability of Large Language Models (LLMs) for triggering and personalizing content for Just-in-Time Adaptive Interventions (JITAIs) in digital health. JITAIs are being explored as a key mechanism for sustainable behavior change, adapting interventions to an individual's current context and needs. However, traditional rule-based and machine learning models for JITAI implementation face scalability and reliability limitations, such as lack of personalization, difficulty in managing multi-parametric systems, and issues with data sparsity. To investigate JITAI implementation via LLMs, we tested the contemporary overall performance-leading model 'GPT-4' with examples grounded in the use case of fostering heart-healthy physical activity in outpatient cardiac rehabilitation. Three personas and five sets of context information per persona were used as a basis of triggering and personalizing JITAIs. Subsequently, we generated a total of 450 proposed JITAI decisions and message content, divided equally into JITAIs generated by 10 iterations with GPT-4, a baseline provided by 10 laypersons (LayPs), and a gold standard set by 10 healthcare professionals (HCPs). Ratings from 27 LayPs indicated that JITAIs generated by GPT-4 were superior to those by HCPs and LayPs over all assessed scales: i.e., appropriateness, engagement, effectiveness, and professionality. This study indicates that LLMs have significant potential for implementing JITAIs as a building block of personalized or "precision" health, offering scalability, effective personalization based on opportunistically sampled information, and good acceptability.
Application-driven Validation of Posteriors in Inverse Problems
Sep 18, 2023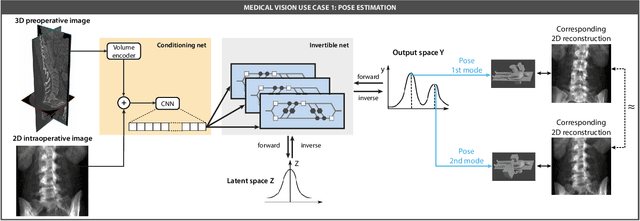
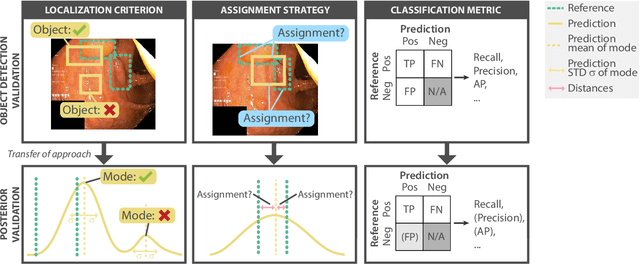
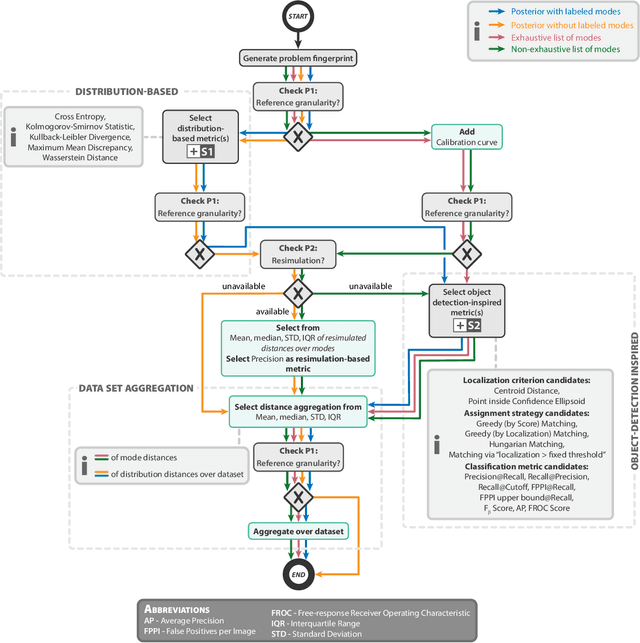
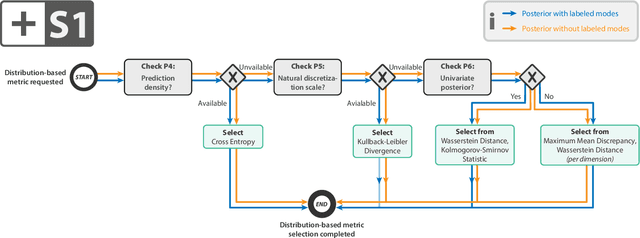
Current deep learning-based solutions for image analysis tasks are commonly incapable of handling problems to which multiple different plausible solutions exist. In response, posterior-based methods such as conditional Diffusion Models and Invertible Neural Networks have emerged; however, their translation is hampered by a lack of research on adequate validation. In other words, the way progress is measured often does not reflect the needs of the driving practical application. Closing this gap in the literature, we present the first systematic framework for the application-driven validation of posterior-based methods in inverse problems. As a methodological novelty, it adopts key principles from the field of object detection validation, which has a long history of addressing the question of how to locate and match multiple object instances in an image. Treating modes as instances enables us to perform mode-centric validation, using well-interpretable metrics from the application perspective. We demonstrate the value of our framework through instantiations for a synthetic toy example and two medical vision use cases: pose estimation in surgery and imaging-based quantification of functional tissue parameters for diagnostics. Our framework offers key advantages over common approaches to posterior validation in all three examples and could thus revolutionize performance assessment in inverse problems.
Trustworthy Deep Learning via Proper Calibration Errors: A Unifying Approach for Quantifying the Reliability of Predictive Uncertainty
Mar 15, 2022

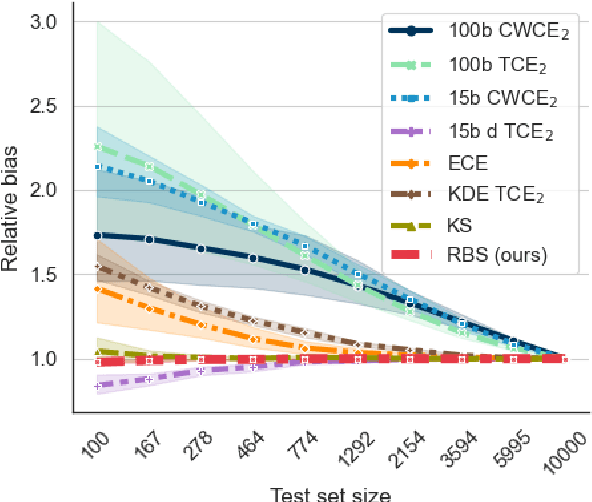

With model trustworthiness being crucial for sensitive real-world applications, practitioners are putting more and more focus on evaluating deep neural networks in terms of uncertainty calibration. Calibration errors are designed to quantify the reliability of probabilistic predictions but their estimators are usually biased and inconsistent. In this work, we introduce the framework of proper calibration errors, which relates every calibration error to a proper score and provides a respective upper bound with optimal estimation properties. This upper bound allows us to reliably estimate the calibration improvement of any injective recalibration method in an unbiased manner. We demonstrate that, in contrast to our approach, the most commonly used estimators are substantially biased with respect to the true improvement of recalibration methods.
Post-hoc Uncertainty Calibration for Domain Drift Scenarios
Dec 20, 2020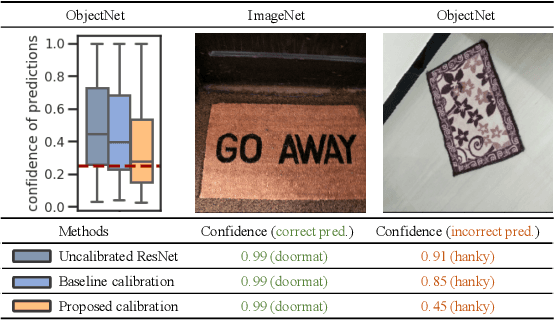

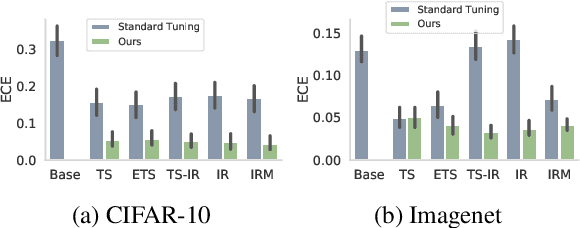
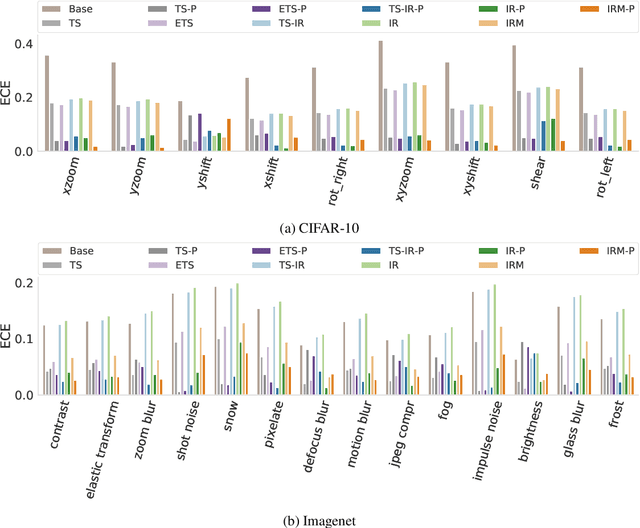
We address the problem of uncertainty calibration. While standard deep neural networks typically yield uncalibrated predictions, calibrated confidence scores that are representative of the true likelihood of a prediction can be achieved using post-hoc calibration methods. However, to date the focus of these approaches has been on in-domain calibration. Our contribution is two-fold. First, we show that existing post-hoc calibration methods yield highly over-confident predictions under domain shift. Second, we introduce a simple strategy where perturbations are applied to samples in the validation set before performing the post-hoc calibration step. In extensive experiments, we demonstrate that this perturbation step results in substantially better calibration under domain shift on a wide range of architectures and modelling tasks.