 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Based Abstention in LLMs Improves Safety and Reduces Hallucinations
Apr 16, 2024A major barrier towards the practical deployment of large language models (LLMs) is their lack of reliability. Three situations where this is particularly apparent are correctness, hallucinations when given unanswerable questions, and safety. In all three cases, models should ideally abstain from responding, much like humans, whose ability to understand uncertainty makes us refrain from answering questions we don't know. Inspired by analogous approaches in classification, this study explores the feasibility and efficacy of abstaining while uncertain in the context of LLMs within the domain of question-answering. We investigate two kinds of uncertainties, statistical uncertainty metrics and a distinct verbalized measure, termed as In-Dialogue Uncertainty (InDU). Using these uncertainty measures combined with models with and without Reinforcement Learning with Human Feedback (RLHF), we show that in all three situations, abstention based on the right kind of uncertainty measure can boost the reliability of LLMs. By sacrificing only a few highly uncertain samples we can improve correctness by 2% to 8%, avoid 50% hallucinations via correctly identifying unanswerable questions and increase safety by 70% up to 99% with almost no additional computational overhead.
Quality Control at Your Fingertips: Quality-Aware Translation Models
Oct 10, 2023Maximum-a-posteriori (MAP) decoding is the most widely used decoding strategy for neural machine translation (NMT) models. The underlying assumption is that model probability correlates well with human judgment, with better translations being more likely. However, research has shown that this assumption does not always hold, and decoding strategies which directly optimize a utility function, like Minimum Bayes Risk (MBR) or Quality-Aware decoding can significantly improve translation quality over standard MAP decoding. The main disadvantage of these methods is that they require an additional model to predict the utility, and additional steps during decoding, which makes the entire process computationally demanding. In this paper, we propose to make the NMT models themselves quality-aware by training them to estimate the quality of their own output. During decoding, we can use the model's own quality estimates to guide the generation process and produce the highest-quality translations possible. We demonstrate that the model can self-evaluate its own output during translation, eliminating the need for a separate quality estimation model. Moreover, we show that using this quality signal as a prompt during MAP decoding can significantly improve translation quality. When using the internal quality estimate to prune the hypothesis space during MBR decoding, we can not only further improve translation quality, but also reduce inference speed by two orders of magnitude.
Beyond In-Domain Scenarios: Robust Density-Aware Calibration
Feb 10, 2023



Calibrating deep learning models to yield uncertainty-aware predictions is crucial as deep neural networks get increasingly deployed in safety-critical applications. While existing post-hoc calibration methods achieve impressive results on in-domain test datasets, they are limited by their inability to yield reliable uncertainty estimates in domain-shift and out-of-domain (OOD) scenarios. We aim to bridge this gap by proposing DAC, an accuracy-preserving as well as Density-Aware Calibration method based on k-nearest-neighbors (KNN). In contrast to existing post-hoc methods, we utilize hidden layers of classifiers as a source for uncertainty-related information and study their importance. We show that DAC is a generic method that can readily be combined with state-of-the-art post-hoc methods. DAC boosts the robustness of calibration performance in domain-shift and OOD, while maintaining excellent in-domain predictive uncertainty estimates. We demonstrate that DAC leads to consistently better calibration across a large number of model architectures, datasets, and metrics. Additionally, we show that DAC improves calibration substantially on recent large-scale neural networks pre-trained on vast amounts of data.
What Makes Graph Neural Networks Miscalibrated?
Oct 12, 2022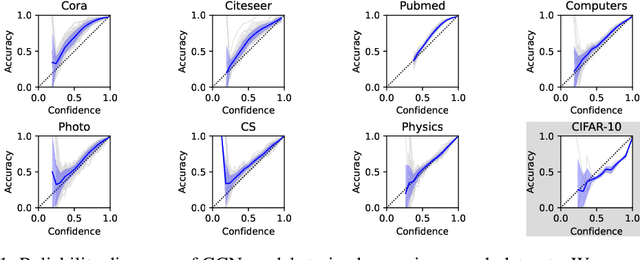
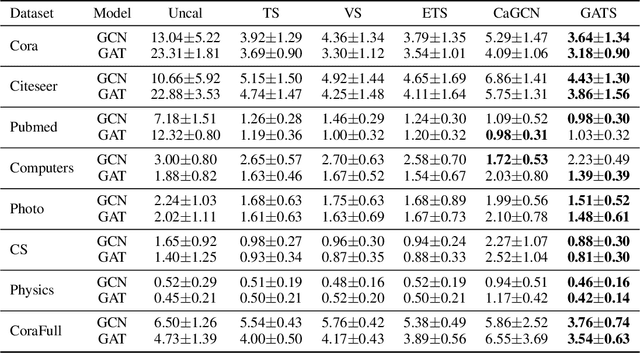
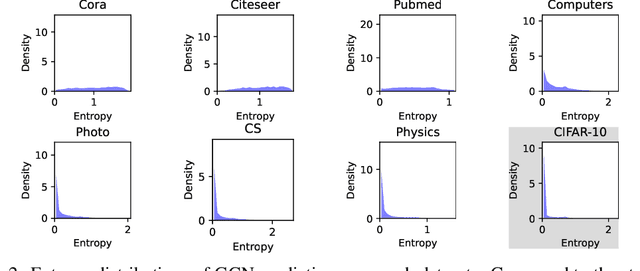
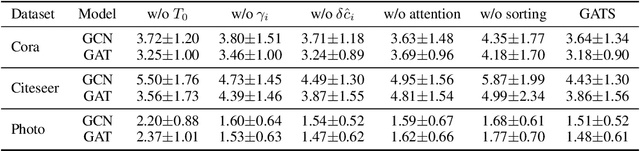
Given the importance of getting calibrated predictions and reliable uncertainty estimations, various post-hoc calibration methods have been developed for neural networks on standard multi-class classification tasks. However, these methods are not well suited for calibrating graph neural networks (GNNs), which presents unique challenges such as accounting for the graph structure and the graph-induced correlations between the nodes. In this work, we conduct a systematic study on the calibration qualities of GNN node predictions. In particular, we identify five factors which influence the calibration of GNNs: general under-confident tendency, diversity of nodewise predictive distributions, distance to training nodes, relative confidence level, and neighborhood similarity. Furthermore, based on the insights from this study, we design a novel calibration method named Graph Attention Temperature Scaling (GATS), which is tailored for calibrating graph neural networks. GATS incorporates designs that address all the identified influential factors and produces nodewise temperature scaling using an attention-based architecture. GATS is accuracy-preserving, data-efficient, and expressive at the same time. Our experiments empirically verify the effectiveness of GATS, demonstrating that it can consistently achieve state-of-the-art calibration results on various graph datasets for different GNN backbones.
CHALLENGER: Training with Attribution Maps
May 30, 2022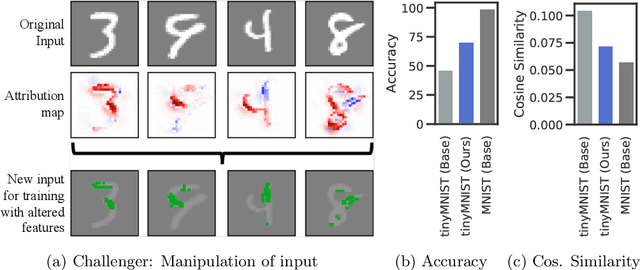


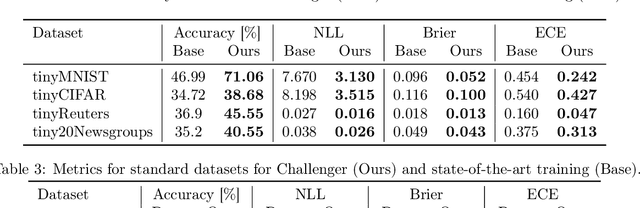
We show that utilizing attribution maps for training neural networks can improve regularization of models and thus increase performance. Regularization is key in deep learning, especially when training complex models on relatively small datasets. In order to understand inner workings of neural networks, attribution methods such as Layer-wise Relevance Propagation (LRP) have been extensively studied, particularly for interpreting the relevance of input features. We introduce Challenger, a module that leverages the explainable power of attribution maps in order to manipulate particularly relevant input patterns. Therefore, exposing and subsequently resolving regions of ambiguity towards separating classes on the ground-truth data manifold, an issue that arises particularly when training models on rather small datasets. Our Challenger module increases model performance through building more diverse filters within the network and can be applied to any input data domain. We demonstrate that our approach results in substantially better classification as well as calibration performance on datasets with only a few samples up to datasets with thousands of samples. In particular, we show that our generic domain-independent approach yields state-of-the-art results in vision, natural language processing and on time series tasks.
Parameterized Temperature Scaling for Boosting the Expressive Power in Post-Hoc Uncertainty Calibration
Feb 24, 2021

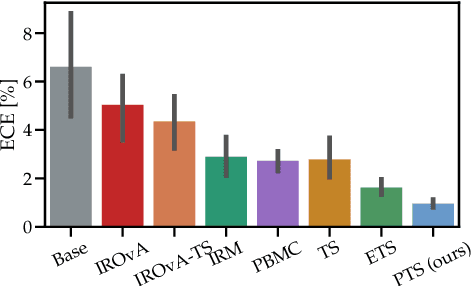

We address the problem of uncertainty calibration and introduce a novel calibration method, Parametrized Temperature Scaling (PTS). Standard deep neural networks typically yield uncalibrated predictions, which can be transformed into calibrated confidence scores using post-hoc calibration methods. In this contribution, we demonstrate that the performance of accuracy-preserving state-of-the-art post-hoc calibrators is limited by their intrinsic expressive power. We generalize temperature scaling by computing prediction-specific temperatures, parameterized by a neural network. We show with extensive experiments that our novel accuracy-preserving approach consistently outperforms existing algorithms across a large number of model architectures, datasets and metrics.
Post-hoc Uncertainty Calibration for Domain Drift Scenarios
Dec 20, 2020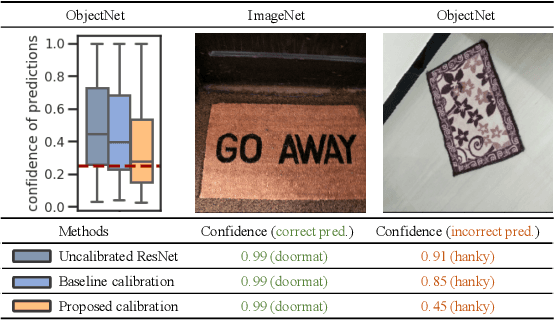

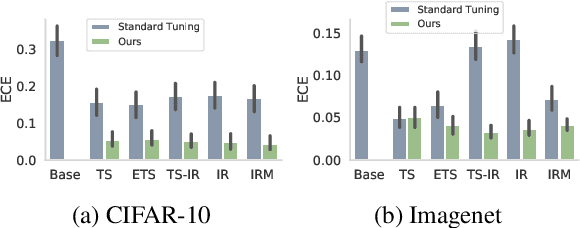
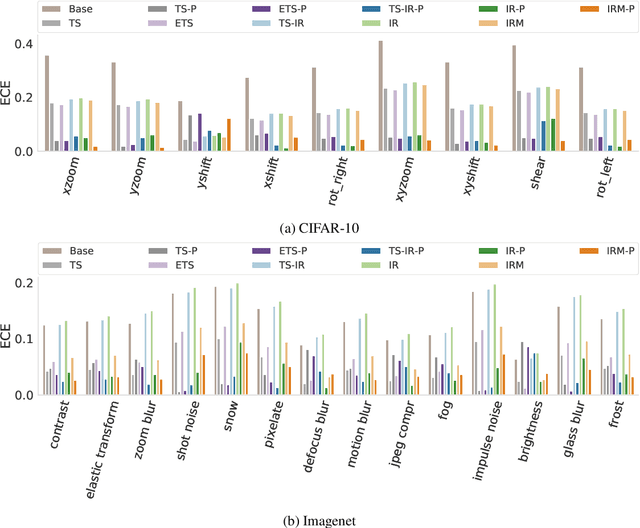
We address the problem of uncertainty calibration. While standard deep neural networks typically yield uncalibrated predictions, calibrated confidence scores that are representative of the true likelihood of a prediction can be achieved using post-hoc calibration methods. However, to date the focus of these approaches has been on in-domain calibration. Our contribution is two-fold. First, we show that existing post-hoc calibration methods yield highly over-confident predictions under domain shift. Second, we introduce a simple strategy where perturbations are applied to samples in the validation set before performing the post-hoc calibration step. In extensive experiments, we demonstrate that this perturbation step results in substantially better calibration under domain shift on a wide range of architectures and modelling tasks.
Towards Trustworthy Predictions from Deep Neural Networks with Fast Adversarial Calibration
Dec 20, 2020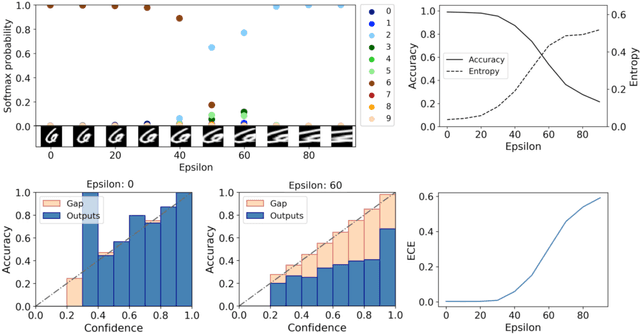


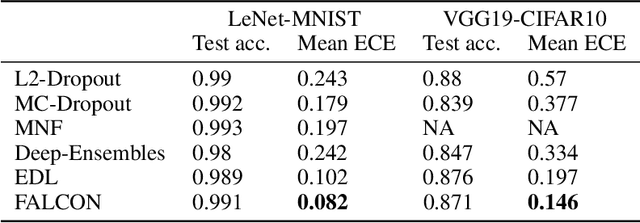
To facilitate a wide-spread acceptance of AI systems guiding decision making in real-world applications, trustworthiness of deployed models is key. That is, it is crucial for predictive models to be uncertainty-aware and yield well-calibrated (and thus trustworthy) predictions for both in-domain samples as well as under domain shift. Recent efforts to account for predictive uncertainty include post-processing steps for trained neural networks, Bayesian neural networks as well as alternative non-Bayesian approaches such as ensemble approaches and evidential deep learning. Here, we propose an efficient yet general modelling approach for obtaining well-calibrated, trustworthy probabilities for samples obtained after a domain shift. We introduce a new training strategy combining an entropy-encouraging loss term with an adversarial calibration loss term and demonstrate that this results in well-calibrated and technically trustworthy predictions for a wide range of domain drifts. We comprehensively evaluate previously proposed approaches on different data modalities, a large range of data sets including sequence data, network architectures and perturbation strategies. We observe that our modelling approach substantially outperforms existing state-of-the-art approaches, yielding well-calibrated predictions under domain drift.