 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-based material parameters extraction from perovskite experiments via Gaussian process
Feb 24, 2024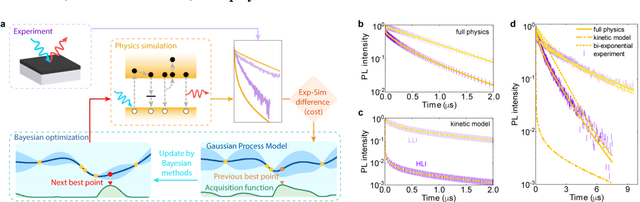
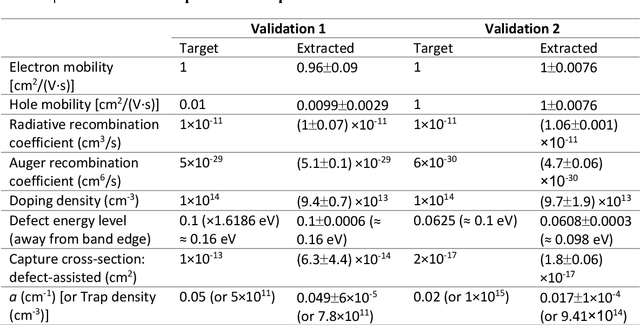
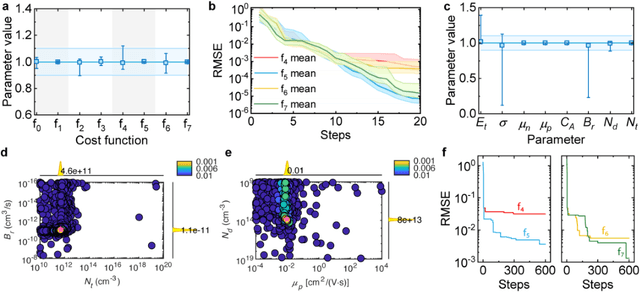

The ability to extract material parameters of perovskite from quantitative experimental analysis is essential for rational design of photovoltaic and optoelectronic applications. However, the difficulty of this analysis increases significantly with the complexity of the theoretical model and the number of material parameters for perovskite. Here we use Gaussian process to develop an analysis platform that can extract up to 8 fundamental material parameters of an organometallic perovskite semiconductor from a transient photoluminescence experiment, based on a complex full physics model that includes drift-diffusion of carriers and dynamic defect occupation. An example study of thermal degradation reveals that changes in doping concentration and carrier mobility dominate, while the defect energy level remains nearly unchanged. This platform can be conveniently applied to other experiments or to combinations of experiments, accelerating materials discovery and optimization of semiconductor materials for photovoltaics and other applications.
Exoplanet Characterization using Conditional Invertible Neural Networks
Jan 31, 2022



The characterization of an exoplanet's interior is an inverse problem, which requires statistical methods such as Bayesian inference in order to be solved. Current methods employ Markov Chain Monte Carlo (MCMC) sampling to infer the posterior probability of planetary structure parameters for a given exoplanet. These methods are time consuming since they require the calculation of a large number of planetary structure models. To speed up the inference process when characterizing an exoplanet, we propose to use conditional invertible neural networks (cINNs) to calculate the posterior probability of the internal structure parameters. cINNs are a special type of neural network which excel in solving inverse problems. We constructed a cINN using FrEIA, which was then trained on a database of $5.6\cdot 10^6$ internal structure models to recover the inverse mapping between internal structure parameters and observable features (i.e., planetary mass, planetary radius and composition of the host star). The cINN method was compared to a Metropolis-Hastings MCMC. For that we repeated the characterization of the exoplanet K2-111 b, using both the MCMC method and the trained cINN. We show that the inferred posterior probability of the internal structure parameters from both methods are very similar, with the biggest differences seen in the exoplanet's water content. Thus cINNs are a possible alternative to the standard time-consuming sampling methods. Indeed, using cINNs allows for orders of magnitude faster inference of an exoplanet's composition than what is possible using an MCMC method, however, it still requires the computation of a large database of internal structures to train the cINN. Since this database is only computed once, we found that using a cINN is more efficient than an MCMC, when more than 10 exoplanets are characterized using the same cINN.
Evaluation of Output Embeddings for Fine-Grained Image Classification
Aug 28, 2015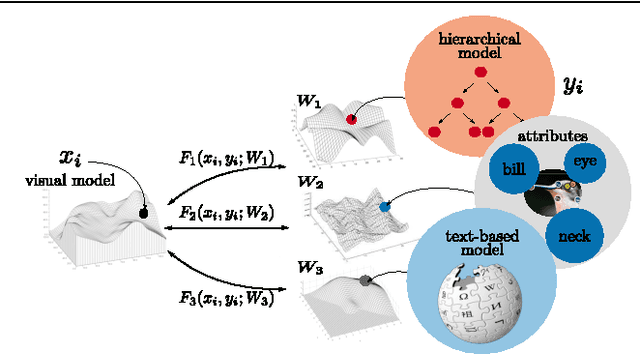
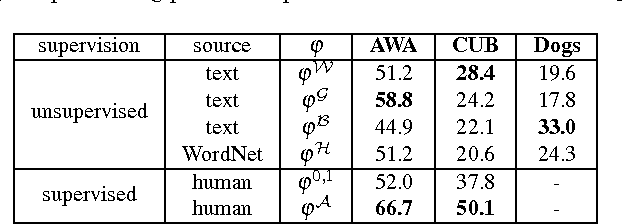
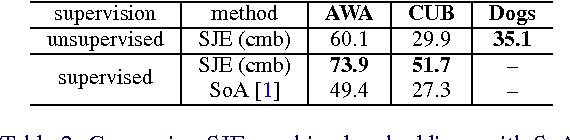
Image classification has advanced significantly in recent years with the availability of large-scale image sets. However, fine-grained classification remains a major challenge due to the annotation cost of large numbers of fine-grained categories. This project shows that compelling classification performance can be achieved on such categories even without labeled training data. Given image and class embeddings, we learn a compatibility function such that matching embeddings are assigned a higher score than mismatching ones; zero-shot classification of an image proceeds by finding the label yielding the highest joint compatibility score. We use state-of-the-art image features and focus on different supervised attributes and unsupervised output embeddings either derived from hierarchies or learned from unlabeled text corpora. We establish a substantially improved state-of-the-art on the Animals with Attributes and Caltech-UCSD Birds datasets. Most encouragingly, we demonstrate that purely unsupervised output embeddings (learned from Wikipedia and improved with fine-grained text) achieve compelling results, even outperforming the previous supervised state-of-the-art. By combining different output embeddings, we further improve results.