 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of the BraTS 2023 Intracranial Meningioma Segmentation Challenge
May 16, 2024



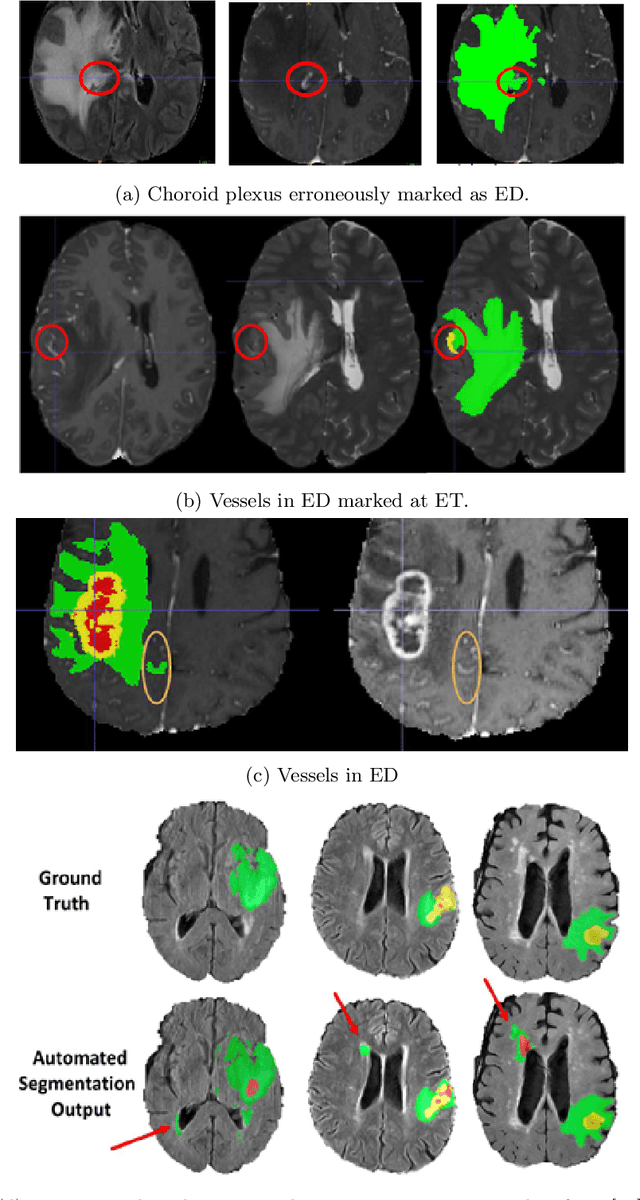
We describe the design and results from the BraTS 2023 Intracranial Meningioma Segmentation Challenge. The BraTS Meningioma Challenge differed from prior BraTS Glioma challenges in that it focused on meningiomas, which are typically benign extra-axial tumors with diverse radiologic and anatomical presentation and a propensity for multiplicity. Nine participating teams each developed deep-learning automated segmentation models using image data from the largest multi-institutional systematically expert annotated multilabel multi-sequence meningioma MRI dataset to date, which included 1000 training set cases, 141 validation set cases, and 283 hidden test set cases. Each case included T2, T2/FLAIR, T1, and T1Gd brain MRI sequences with associated tumor compartment labels delineating enhancing tumor, non-enhancing tumor, and surrounding non-enhancing T2/FLAIR hyperintensity. Participant automated segmentation models were evaluated and ranked based on a scoring system evaluating lesion-wise metrics including dice similarity coefficient (DSC) and 95% Hausdorff Distance. The top ranked team had a lesion-wise median dice similarity coefficient (DSC) of 0.976, 0.976, and 0.964 for enhancing tumor, tumor core, and whole tumor, respectively and a corresponding average DSC of 0.899, 0.904, and 0.871, respectively. These results serve as state-of-the-art benchmarks for future pre-operative meningioma automated segmentation algorithms. Additionally, we found that 1286 of 1424 cases (90.3%) had at least 1 compartment voxel abutting the edge of the skull-stripped image edge, which requires further investigation into optimal pre-processing face anonymization steps.
The Brain Tumor Segmentation Challenge 2023: Brain MR Image Synthesis for Tumor Segmentation
May 20, 2023
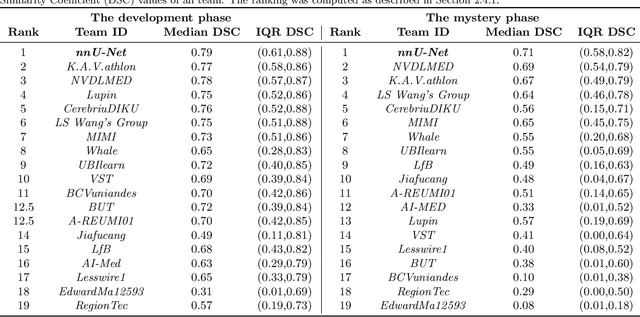
Automated brain tumor segmentation methods are well established, reaching performance levels with clear clinical utility. Most algorithms require four input magnetic resonance imaging (MRI) modalities, typically T1-weighted images with and without contrast enhancement, T2-weighted images, and FLAIR images. However, some of these sequences are often missing in clinical practice, e.g., because of time constraints and/or image artifacts (such as patient motion). Therefore, substituting missing modalities to recover segmentation performance in these scenarios is highly desirable and necessary for the more widespread adoption of such algorithms in clinical routine. In this work, we report the set-up of the Brain MR Image Synthesis Benchmark (BraSyn), organized in conjunction with the Medical Image Computing and Computer-Assisted Intervention (MICCAI) 2023. The objective of the challenge is to benchmark image synthesis methods that realistically synthesize missing MRI modalities given multiple available images to facilitate automated brain tumor segmentation pipelines. The image dataset is multi-modal and diverse, created in collaboration with various hospitals and research institutions.
The Brain Tumor Segmentation Challenge 2023: Local Synthesis of Healthy Brain Tissue via Inpainting
May 15, 2023



A myriad of algorithms for the automatic analysis of brain MR images is available to support clinicians in their decision-making. For brain tumor patients, the image acquisition time series typically starts with a scan that is already pathological. This poses problems, as many algorithms are designed to analyze healthy brains and provide no guarantees for images featuring lesions. Examples include but are not limited to algorithms for brain anatomy parcellation, tissue segmentation, and brain extraction. To solve this dilemma, we introduce the BraTS 2023 inpainting challenge. Here, the participants' task is to explore inpainting techniques to synthesize healthy brain scans from lesioned ones. The following manuscript contains the task formulation, dataset, and submission procedure. Later it will be updated to summarize the findings of the challenge. The challenge is organized as part of the BraTS 2023 challenge hosted at the MICCAI 2023 conference in Vancouver, Canada.
Federated Learning Enables Big Data for Rare Cancer Boundary Detection
Apr 25, 2022Although machine learning (ML) has shown promise in numerous domains, there are concerns about generalizability to out-of-sample data. This is currently addressed by centrally sharing ample, and importantly diverse, data from multiple sites. However, such centralization is challenging to scale (or even not feasible) due to various limitations. Federated ML (FL) provides an alternative to train accurate and generalizable ML models, by only sharing numerical model updates. Here we present findings from the largest FL study to-date, involving data from 71 healthcare institutions across 6 continents, to generate an automatic tumor boundary detector for the rare disease of glioblastoma, utilizing the largest dataset of such patients ever used in the literature (25,256 MRI scans from 6,314 patients). We demonstrate a 33% improvement over a publicly trained model to delineate the surgically targetable tumor, and 23% improvement over the tumor's entire extent. We anticipate our study to: 1) enable more studies in healthcare informed by large and diverse data, ensuring meaningful results for rare diseases and underrepresented populations, 2) facilitate further quantitative analyses for glioblastoma via performance optimization of our consensus model for eventual public release, and 3) demonstrate the effectiveness of FL at such scale and task complexity as a paradigm shift for multi-site collaborations, alleviating the need for data sharing.
The Brain Tumor Sequence Registration Challenge: Establishing Correspondence between Pre-Operative and Follow-up MRI scans of diffuse glioma patients
Dec 13, 2021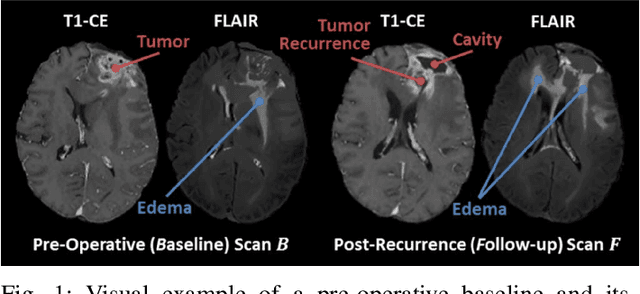
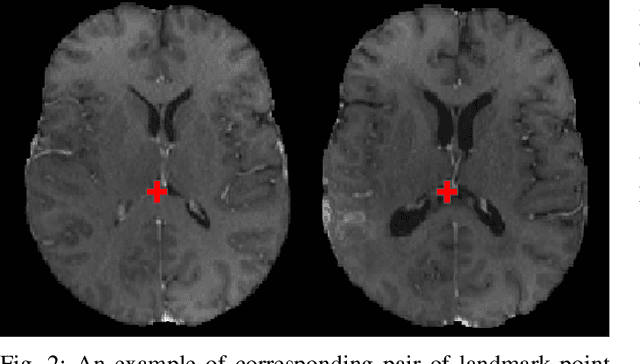
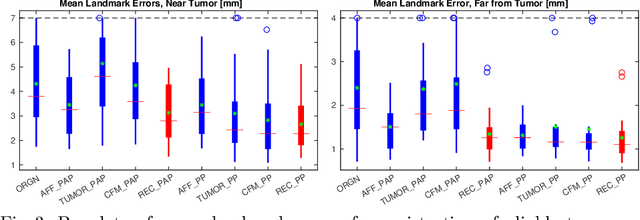
Registration of longitudinal brain Magnetic Resonance Imaging (MRI) scans containing pathologies is challenging due to tissue appearance changes, and still an unsolved problem. This paper describes the first Brain Tumor Sequence Registration (BraTS-Reg) challenge, focusing on estimating correspondences between pre-operative and follow-up scans of the same patient diagnosed with a brain diffuse glioma. The BraTS-Reg challenge intends to establish a public benchmark environment for deformable registration algorithms. The associated dataset comprises de-identified multi-institutional multi-parametric MRI (mpMRI) data, curated for each scan's size and resolution, according to a common anatomical template. Clinical experts have generated extensive annotations of landmarks points within the scans, descriptive of distinct anatomical locations across the temporal domain. The training data along with these ground truth annotations will be released to participants to design and develop their registration algorithms, whereas the annotations for the validation and the testing data will be withheld by the organizers and used to evaluate the containerized algorithms of the participants. Each submitted algorithm will be quantitatively evaluated using several metrics, such as the Median Absolute Error (MAE), Robustness, and the Jacobian determinant.
The RSNA-ASNR-MICCAI BraTS 2021 Benchmark on Brain Tumor Segmentation and Radiogenomic Classification
Jul 05, 2021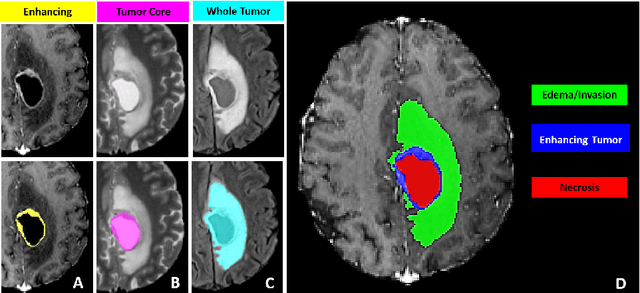
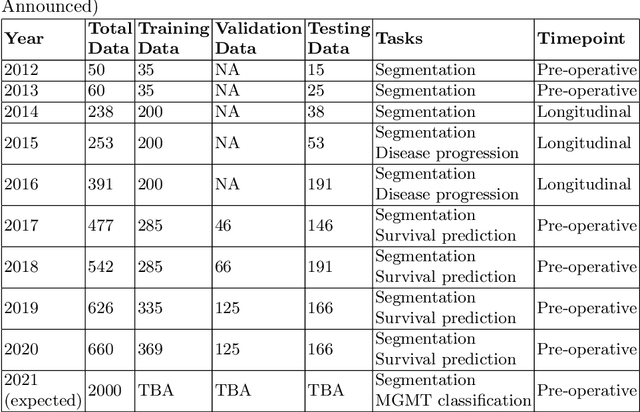
The BraTS 2021 challenge celebrates its 10th anniversary and is jointly organized by the Radiological Society of North America (RSNA), the American Society of Neuroradiology (ASNR), and the Medical Image Computing and Computer Assisted Interventions (MICCAI) society. Since its inception, BraTS has been focusing on being a common benchmarking venue for brain glioma segmentation algorithms, with well-curated multi-institutional multi-parametric magnetic resonance imaging (mpMRI) data. Gliomas are the most common primary malignancies of the central nervous system, with varying degrees of aggressiveness and prognosis. The RSNA-ASNR-MICCAI BraTS 2021 challenge targets the evaluation of computational algorithms assessing the same tumor compartmentalization, as well as the underlying tumor's molecular characterization, in pre-operative baseline mpMRI data from 2,000 patients. Specifically, the two tasks that BraTS 2021 focuses on are: a) the segmentation of the histologically distinct brain tumor sub-regions, and b) the classification of the tumor's O[6]-methylguanine-DNA methyltransferase (MGMT) promoter methylation status. The performance evaluation of all participating algorithms in BraTS 2021 will be conducted through the Sage Bionetworks Synapse platform (Task 1) and Kaggle (Task 2), concluding in distributing to the top ranked participants monetary awards of $60,000 collectively.
The Medical Segmentation Decathlon
Jun 10, 2021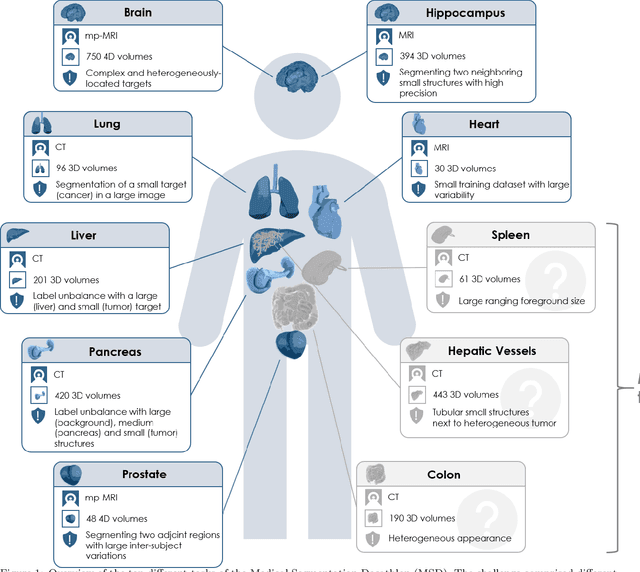
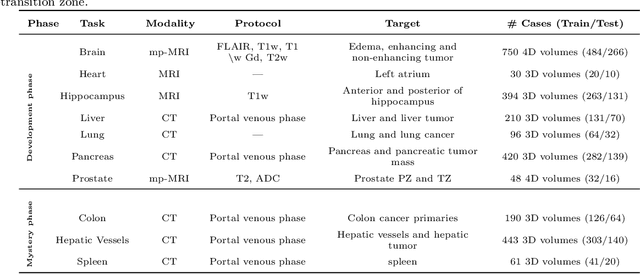
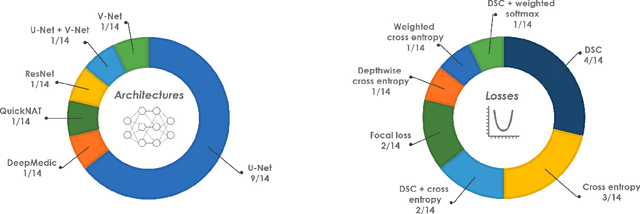
International challenges have become the de facto standard for comparative assessment of image analysis algorithms given a specific task. Segmentation is so far the most widely investigated medical image processing task, but the various segmentation challenges have typically been organized in isolation, such that algorithm development was driven by the need to tackle a single specific clinical problem. We hypothesized that a method capable of performing well on multiple tasks will generalize well to a previously unseen task and potentially outperform a custom-designed solution. To investigate the hypothesis, we organized the Medical Segmentation Decathlon (MSD) - a biomedical image analysis challenge, in which algorithms compete in a multitude of both tasks and modalities. The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data and small objects. The MSD challenge confirmed that algorithms with a consistent good performance on a set of tasks preserved their good average performance on a different set of previously unseen tasks. Moreover, by monitoring the MSD winner for two years, we found that this algorithm continued generalizing well to a wide range of other clinical problems, further confirming our hypothesis. Three main conclusions can be drawn from this study: (1) state-of-the-art image segmentation algorithms are mature, accurate, and generalize well when retrained on unseen tasks; (2) consistent algorithmic performance across multiple tasks is a strong surrogate of algorithmic generalizability; (3) the training of accurate AI segmentation models is now commoditized to non AI experts.
A Deep Network for Joint Registration and Reconstruction of Images with Pathologies
Aug 17, 2020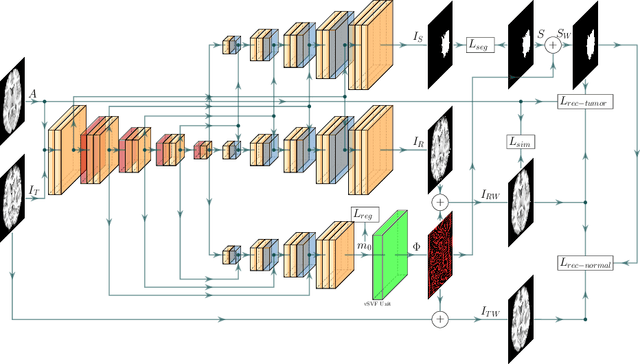
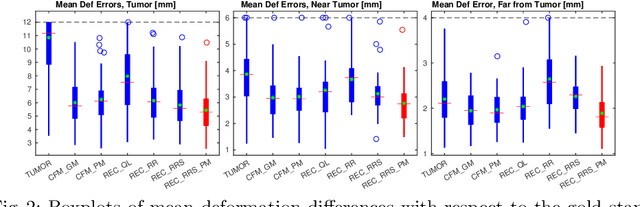
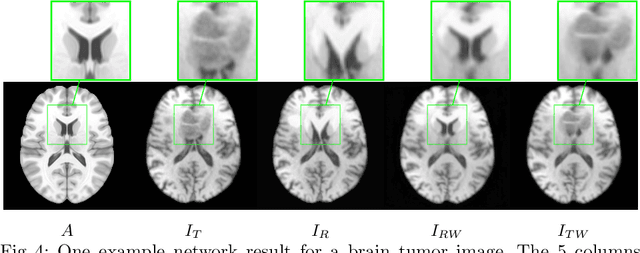
Registration of images with pathologies is challenging due to tissue appearance changes and missing correspondences caused by the pathologies. Moreover, mass effects as observed for brain tumors may displace tissue, creating larger deformations over time than what is observed in a healthy brain. Deep learning models have successfully been applied to image registration to offer dramatic speed up and to use surrogate information (e.g., segmentations) during training. However, existing approaches focus on learning registration models using images from healthy patients. They are therefore not designed for the registration of images with strong pathologies for example in the context of brain tumors, and traumatic brain injuries. In this work, we explore a deep learning approach to register images with brain tumors to an atlas. Our model learns an appearance mapping from images with tumors to the atlas, while simultaneously predicting the transformation to atlas space. Using separate decoders, the network disentangles the tumor mass effect from the reconstruction of quasi-normal images. Results on both synthetic and real brain tumor scans show that our approach outperforms cost function masking for registration to the atlas and that reconstructed quasi-normal images can be used for better longitudinal registrations.
A large annotated medical image dataset for the development and evaluation of segmentation algorithms
Feb 25, 2019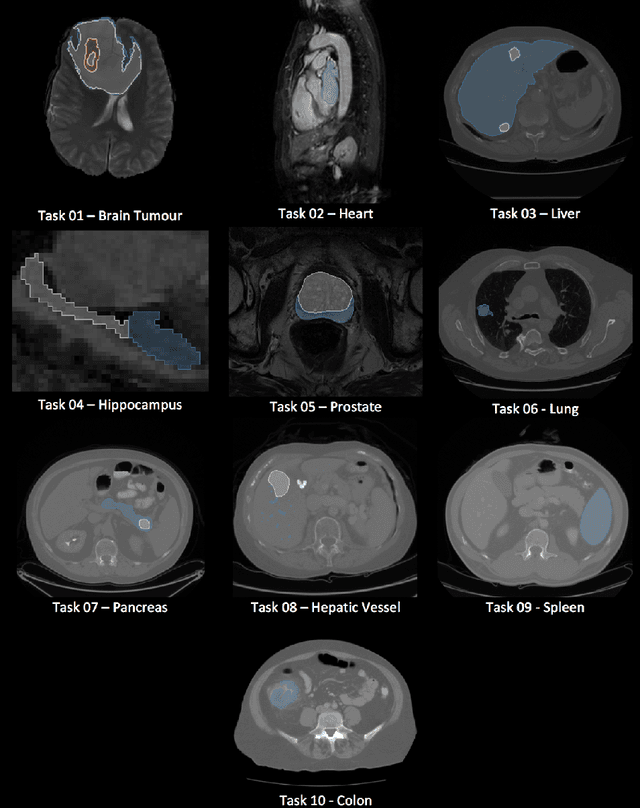

Semantic segmentation of medical images aims to associate a pixel with a label in a medical image without human initialization. The success of semantic segmentation algorithms is contingent on the availability of high-quality imaging data with corresponding labels provided by experts. We sought to create a large collection of annotated medical image datasets of various clinically relevant anatomies available under open source license to facilitate the development of semantic segmentation algorithms. Such a resource would allow: 1) objective assessment of general-purpose segmentation methods through comprehensive benchmarking and 2) open and free access to medical image data for any researcher interested in the problem domain. Through a multi-institutional effort, we generated a large, curated dataset representative of several highly variable segmentation tasks that was used in a crowd-sourced challenge - the Medical Segmentation Decathlon held during the 2018 Medical Image Computing and Computer Aided Interventions Conference in Granada, Spain. Here, we describe these ten labeled image datasets so that these data may be effectively reused by the research community.