 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Brain Tumor Segmentation Challenge 2023: Brain MR Image Synthesis for Tumor Segmentation
May 20, 2023
Automated brain tumor segmentation methods are well established, reaching performance levels with clear clinical utility. Most algorithms require four input magnetic resonance imaging (MRI) modalities, typically T1-weighted images with and without contrast enhancement, T2-weighted images, and FLAIR images. However, some of these sequences are often missing in clinical practice, e.g., because of time constraints and/or image artifacts (such as patient motion). Therefore, substituting missing modalities to recover segmentation performance in these scenarios is highly desirable and necessary for the more widespread adoption of such algorithms in clinical routine. In this work, we report the set-up of the Brain MR Image Synthesis Benchmark (BraSyn), organized in conjunction with the Medical Image Computing and Computer-Assisted Intervention (MICCAI) 2023. The objective of the challenge is to benchmark image synthesis methods that realistically synthesize missing MRI modalities given multiple available images to facilitate automated brain tumor segmentation pipelines. The image dataset is multi-modal and diverse, created in collaboration with various hospitals and research institutions.
The Brain Tumor Segmentation Challenge 2023: Local Synthesis of Healthy Brain Tissue via Inpainting
May 15, 2023



A myriad of algorithms for the automatic analysis of brain MR images is available to support clinicians in their decision-making. For brain tumor patients, the image acquisition time series typically starts with a scan that is already pathological. This poses problems, as many algorithms are designed to analyze healthy brains and provide no guarantees for images featuring lesions. Examples include but are not limited to algorithms for brain anatomy parcellation, tissue segmentation, and brain extraction. To solve this dilemma, we introduce the BraTS 2023 inpainting challenge. Here, the participants' task is to explore inpainting techniques to synthesize healthy brain scans from lesioned ones. The following manuscript contains the task formulation, dataset, and submission procedure. Later it will be updated to summarize the findings of the challenge. The challenge is organized as part of the BraTS 2023 challenge hosted at the MICCAI 2023 conference in Vancouver, Canada.
Federated Learning Enables Big Data for Rare Cancer Boundary Detection
Apr 25, 2022Although machine learning (ML) has shown promise in numerous domains, there are concerns about generalizability to out-of-sample data. This is currently addressed by centrally sharing ample, and importantly diverse, data from multiple sites. However, such centralization is challenging to scale (or even not feasible) due to various limitations. Federated ML (FL) provides an alternative to train accurate and generalizable ML models, by only sharing numerical model updates. Here we present findings from the largest FL study to-date, involving data from 71 healthcare institutions across 6 continents, to generate an automatic tumor boundary detector for the rare disease of glioblastoma, utilizing the largest dataset of such patients ever used in the literature (25,256 MRI scans from 6,314 patients). We demonstrate a 33% improvement over a publicly trained model to delineate the surgically targetable tumor, and 23% improvement over the tumor's entire extent. We anticipate our study to: 1) enable more studies in healthcare informed by large and diverse data, ensuring meaningful results for rare diseases and underrepresented populations, 2) facilitate further quantitative analyses for glioblastoma via performance optimization of our consensus model for eventual public release, and 3) demonstrate the effectiveness of FL at such scale and task complexity as a paradigm shift for multi-site collaborations, alleviating the need for data sharing.
Making Document-Level Information Extraction Right for the Right Reasons
Oct 14, 2021

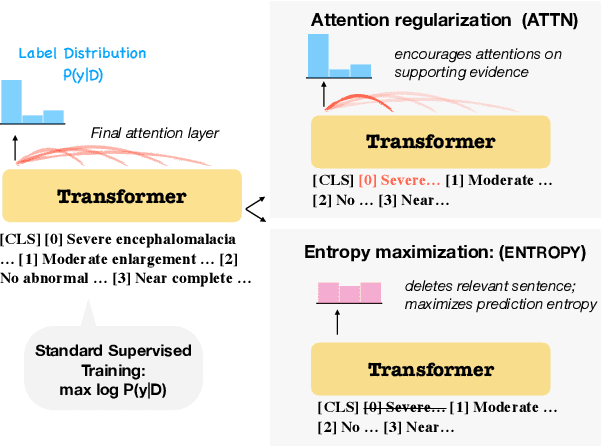
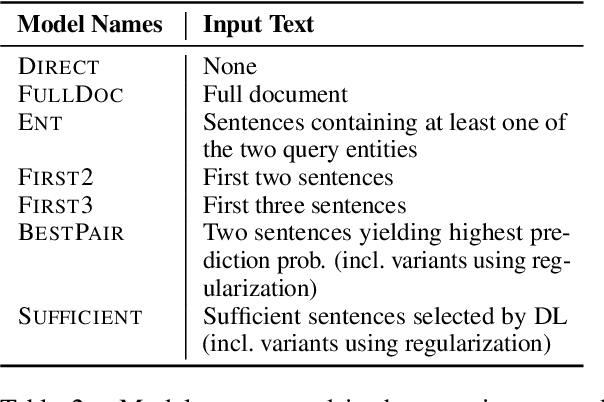
Document-level information extraction is a flexible framework compatible with applications where information is not necessarily localized in a single sentence. For example, key features of a diagnosis in radiology a report may not be explicitly stated, but nevertheless can be inferred from the report's text. However, document-level neural models can easily learn spurious correlations from irrelevant information. This work studies how to ensure that these models make correct inferences from complex text and make those inferences in an auditable way: beyond just being right, are these models "right for the right reasons?" We experiment with post-hoc evidence extraction in a predict-select-verify framework using feature attribution techniques. While this basic approach can extract reasonable evidence, it can be regularized with small amounts of evidence supervision during training, which substantially improves the quality of extracted evidence. We evaluate on two domains: a small-scale labeled dataset of brain MRI reports and a large-scale modified version of DocRED (Yao et al., 2019) and show that models' plausibility can be improved with no loss in accuracy.
The RSNA-ASNR-MICCAI BraTS 2021 Benchmark on Brain Tumor Segmentation and Radiogenomic Classification
Jul 05, 2021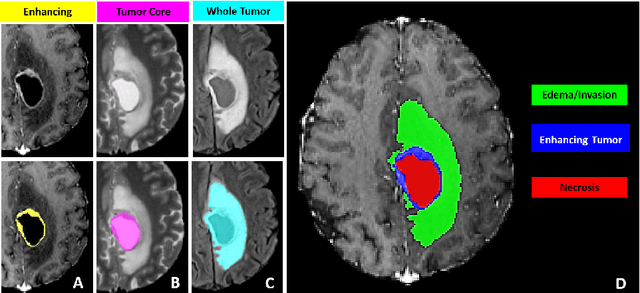
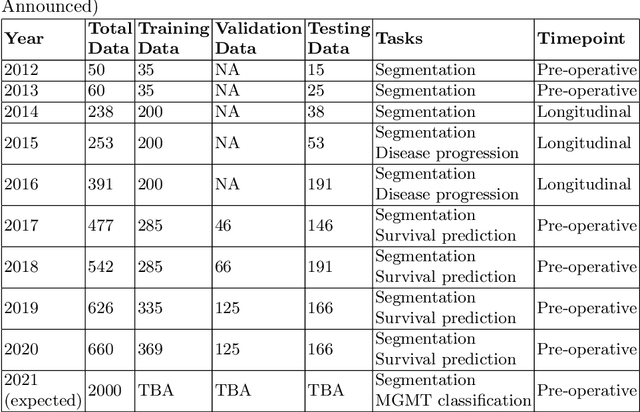
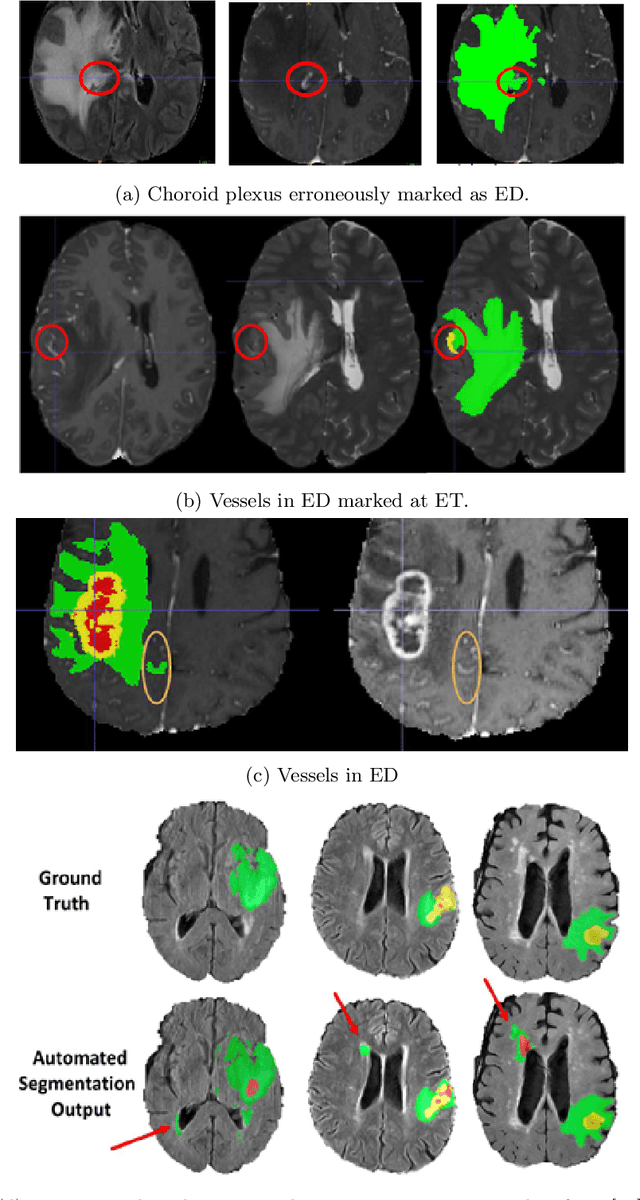
The BraTS 2021 challenge celebrates its 10th anniversary and is jointly organized by the Radiological Society of North America (RSNA), the American Society of Neuroradiology (ASNR), and the Medical Image Computing and Computer Assisted Interventions (MICCAI) society. Since its inception, BraTS has been focusing on being a common benchmarking venue for brain glioma segmentation algorithms, with well-curated multi-institutional multi-parametric magnetic resonance imaging (mpMRI) data. Gliomas are the most common primary malignancies of the central nervous system, with varying degrees of aggressiveness and prognosis. The RSNA-ASNR-MICCAI BraTS 2021 challenge targets the evaluation of computational algorithms assessing the same tumor compartmentalization, as well as the underlying tumor's molecular characterization, in pre-operative baseline mpMRI data from 2,000 patients. Specifically, the two tasks that BraTS 2021 focuses on are: a) the segmentation of the histologically distinct brain tumor sub-regions, and b) the classification of the tumor's O[6]-methylguanine-DNA methyltransferase (MGMT) promoter methylation status. The performance evaluation of all participating algorithms in BraTS 2021 will be conducted through the Sage Bionetworks Synapse platform (Task 1) and Kaggle (Task 2), concluding in distributing to the top ranked participants monetary awards of $60,000 collectively.