 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Video Captioning through Scene Graph Consolidation
Feb 23, 2025Recent advances in visual language models (VLMs) have significantly improved image captioning, but extending these gains to video understanding remains challenging due to the scarcity of fine-grained video captioning datasets. To bridge this gap, we propose a novel zero-shot video captioning approach that combines frame-level scene graphs from a video to obtain intermediate representations for caption generation. Our method first generates frame-level captions using an image VLM, converts them into scene graphs, and consolidates these graphs to produce comprehensive video-level descriptions. To achieve this, we leverage a lightweight graph-to-text model trained solely on text corpora, eliminating the need for video captioning annotations. Experiments on the MSR-VTT and ActivityNet Captions datasets show that our approach outperforms zero-shot video captioning baselines, demonstrating that aggregating frame-level scene graphs yields rich video understanding without requiring large-scale paired data or high inference cost.
Re-evaluating Group Robustness via Adaptive Class-Specific Scaling
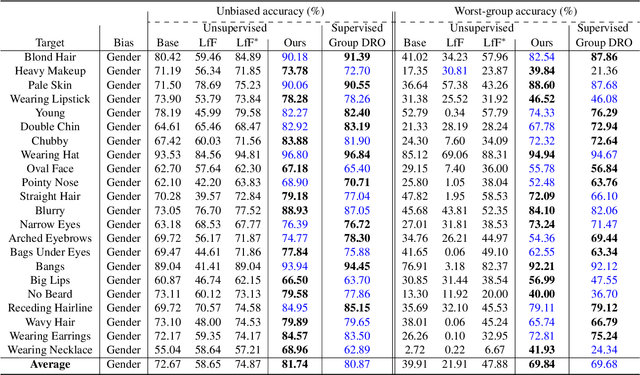
Dec 19, 2024Group distributionally robust optimization, which aims to improve robust accuracies -- worst-group and unbiased accuracies -- is a prominent algorithm used to mitigate spurious correlations and address dataset bias. Although existing approaches have reported improvements in robust accuracies, these gains often come at the cost of average accuracy due to inherent trade-offs. To control this trade-off flexibly and efficiently, we propose a simple class-specific scaling strategy, directly applicable to existing debiasing algorithms with no additional training. We further develop an instance-wise adaptive scaling technique to alleviate this trade-off, even leading to improvements in both robust and average accuracies. Our approach reveals that a na\"ive ERM baseline matches or even outperforms the recent debiasing methods by simply adopting the class-specific scaling technique. Additionally, we introduce a novel unified metric that quantifies the trade-off between the two accuracies as a scalar value, allowing for a comprehensive evaluation of existing algorithms. By tackling the inherent trade-off and offering a performance landscape, our approach provides valuable insights into robust techniques beyond just robust accuracy. We validate the effectiveness of our framework through experiments across datasets in computer vision and natural language processing domains.
Learning to Translate Noise for Robust Image Denoising
Dec 06, 2024



Deep learning-based image denoising techniques often struggle with poor generalization performance to out-of-distribution real-world noise. To tackle this challenge, we propose a novel noise translation framework that performs denoising on an image with translated noise rather than directly denoising an original noisy image. Specifically, our approach translates complex, unknown real-world noise into Gaussian noise, which is spatially uncorrelated and independent of image content, through a noise translation network. The translated noisy images are then processed by an image denoising network pretrained to effectively remove Gaussian noise, enabling robust and consistent denoising performance. We also design well-motivated loss functions and architectures for the noise translation network by leveraging the mathematical properties of Gaussian noise. Experimental results demonstrate that the proposed method substantially improves robustness and generalizability, outperforming state-of-the-art methods across diverse benchmarks. Visualized denoising results and the source code are available on our project page.
Revisiting Machine Unlearning with Dimensional Alignment
Jul 25, 2024



Machine unlearning, an emerging research topic focusing on compliance with data privacy regulations, enables trained models to remove the information learned from specific data. While many existing methods indirectly address this issue by intentionally injecting incorrect supervisions, they can drastically and unpredictably alter the decision boundaries and feature spaces, leading to training instability and undesired side effects. To fundamentally approach this task, we first analyze the changes in latent feature spaces between original and retrained models, and observe that the feature representations of samples not involved in training are closely aligned with the feature manifolds of previously seen samples in training. Based on these findings, we introduce a novel evaluation metric for machine unlearning, coined dimensional alignment, which measures the alignment between the eigenspaces of the forget and retain set samples. We employ this metric as a regularizer loss to build a robust and stable unlearning framework, which is further enhanced by integrating a self-distillation loss and an alternating training scheme. Our framework effectively eliminates information from the forget set and preserves knowledge from the retain set. Lastly, we identify critical flaws in established evaluation metrics for machine unlearning, and introduce new evaluation tools that more accurately reflect the fundamental goals of machine unlearning.
Relaxed Contrastive Learning for Federated Learning
Jan 10, 2024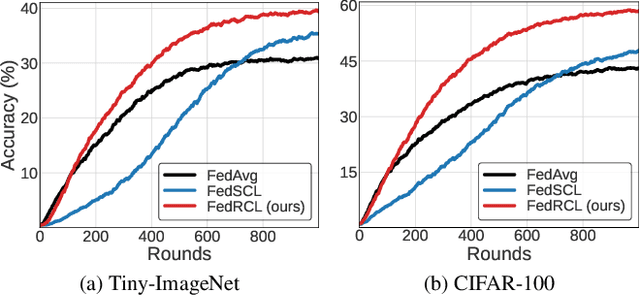
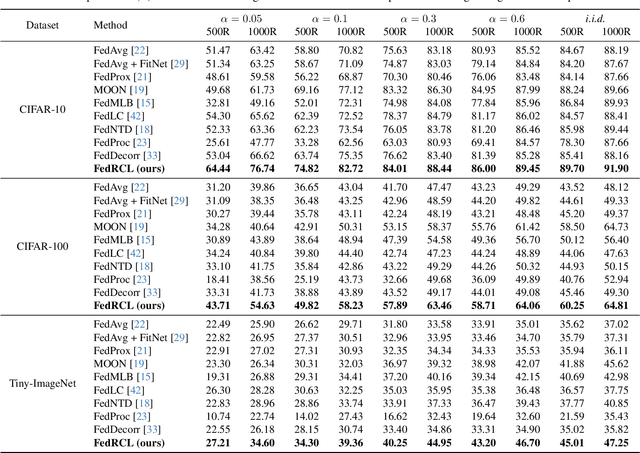
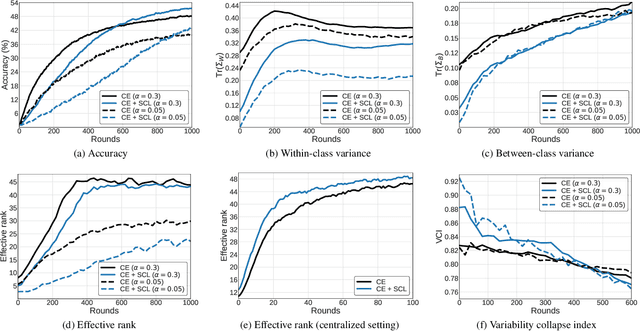
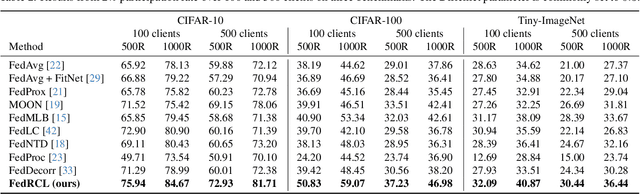
We propose a novel contrastive learning framework to effectively address the challenges of data heterogeneity in federated learning. We first analyze the inconsistency of gradient updates across clients during local training and establish its dependence on the distribution of feature representations, leading to the derivation of the supervised contrastive learning (SCL) objective to mitigate local deviations. In addition, we show that a na\"ive adoption of SCL in federated learning leads to representation collapse, resulting in slow convergence and limited performance gains. To address this issue, we introduce a relaxed contrastive learning loss that imposes a divergence penalty on excessively similar sample pairs within each class. This strategy prevents collapsed representations and enhances feature transferability, facilitating collaborative training and leading to significant performance improvements. Our framework outperforms all existing federated learning approaches by huge margins on the standard benchmarks through extensive experimental results.
Online Backfilling with No Regret for Large-Scale Image Retrieval
Jan 10, 2023Backfilling is the process of re-extracting all gallery embeddings from upgraded models in image retrieval systems. It inevitably requires a prohibitively large amount of computational cost and even entails the downtime of the service. Although backward-compatible learning sidesteps this challenge by tackling query-side representations, this leads to suboptimal solutions in principle because gallery embeddings cannot benefit from model upgrades. We address this dilemma by introducing an online backfilling algorithm, which enables us to achieve a progressive performance improvement during the backfilling process while not sacrificing the final performance of new model after the completion of backfilling. To this end, we first propose a simple distance rank merge technique for online backfilling. Then, we incorporate a reverse transformation module for more effective and efficient merging, which is further enhanced by adopting a metric-compatible contrastive learning approach. These two components help to make the distances of old and new models compatible, resulting in desirable merge results during backfilling with no extra computational overhead. Extensive experiments show the effectiveness of our framework on four standard benchmarks in various settings.
Information-Theoretic Bias Reduction via Causal View of Spurious Correlation
Jan 10, 2022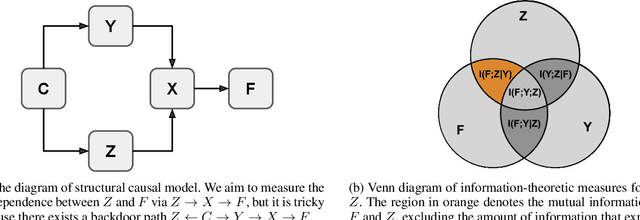
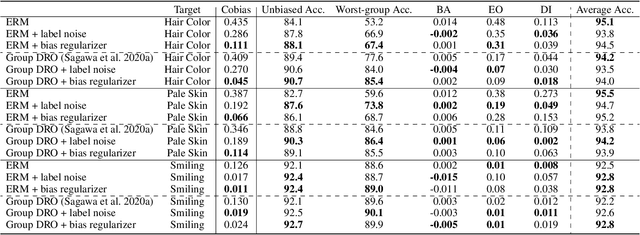
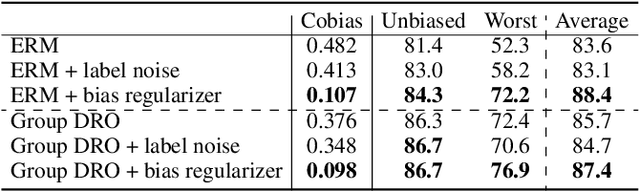

We propose an information-theoretic bias measurement technique through a causal interpretation of spurious correlation, which is effective to identify the feature-level algorithmic bias by taking advantage of conditional mutual information. Although several bias measurement methods have been proposed and widely investigated to achieve algorithmic fairness in various tasks such as face recognition, their accuracy- or logit-based metrics are susceptible to leading to trivial prediction score adjustment rather than fundamental bias reduction. Hence, we design a novel debiasing framework against the algorithmic bias, which incorporates a bias regularization loss derived by the proposed information-theoretic bias measurement approach. In addition, we present a simple yet effective unsupervised debiasing technique based on stochastic label noise, which does not require the explicit supervision of bias information. The proposed bias measurement and debiasing approaches are validated in diverse realistic scenarios through extensive experiments on multiple standard benchmarks.
InfoNeRF: Ray Entropy Minimization for Few-Shot Neural Volume Rendering
Dec 31, 2021



We present an information-theoretic regularization technique for few-shot novel view synthesis based on neural implicit representation. The proposed approach minimizes potential reconstruction inconsistency that happens due to insufficient viewpoints by imposing the entropy constraint of the density in each ray. In addition, to alleviate the potential degenerate issue when all training images are acquired from almost redundant viewpoints, we further incorporate the spatially smoothness constraint into the estimated images by restricting information gains from a pair of rays with slightly different viewpoints. The main idea of our algorithm is to make reconstructed scenes compact along individual rays and consistent across rays in the neighborhood. The proposed regularizers can be plugged into most of existing neural volume rendering techniques based on NeRF in a straightforward way. Despite its simplicity, we achieve consistently improved performance compared to existing neural view synthesis methods by large margins on multiple standard benchmarks. Our project website is available at \url{http://cvlab.snu.ac.kr/research/InfoNeRF}.
Unsupervised Learning of Debiased Representations with Pseudo-Attributes
Aug 06, 2021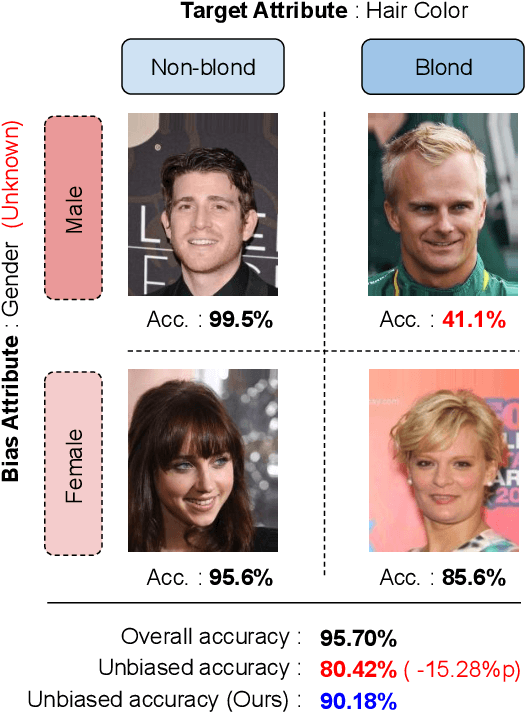

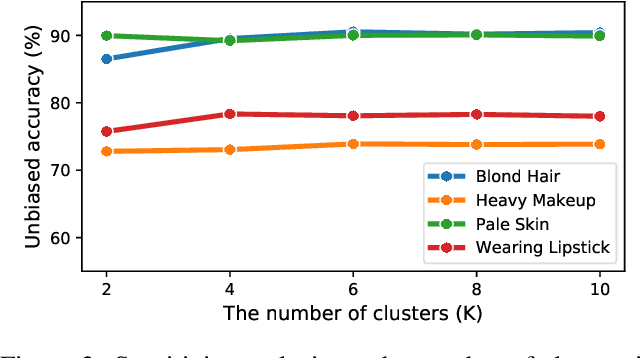
Dataset bias is a critical challenge in machine learning, and its negative impact is aggravated when models capture unintended decision rules with spurious correlations. Although existing works often handle this issue using human supervision, the availability of the proper annotations is impractical and even unrealistic. To better tackle this challenge, we propose a simple but effective debiasing technique in an unsupervised manner. Specifically, we perform clustering on the feature embedding space and identify pseudoattributes by taking advantage of the clustering results even without an explicit attribute supervision. Then, we employ a novel cluster-based reweighting scheme for learning debiased representation; this prevents minority groups from being discounted for minimizing the overall loss, which is desirable for worst-case generalization. The extensive experiments demonstrate the outstanding performance of our approach on multiple standard benchmarks, which is even as competitive as the supervised counterpart.
Learning to Optimize Domain Specific Normalization for Domain Generalization
Jul 09, 2019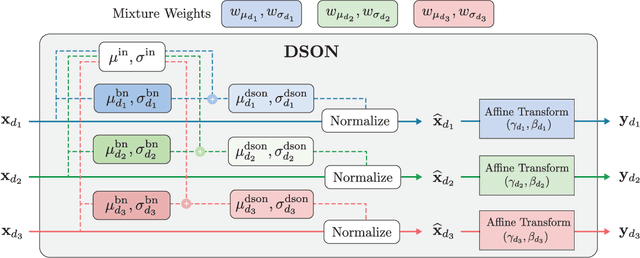
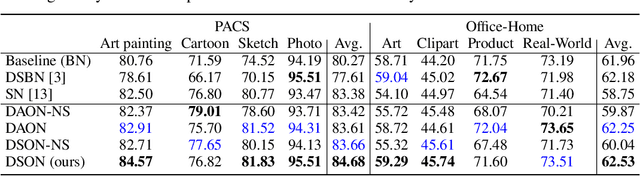
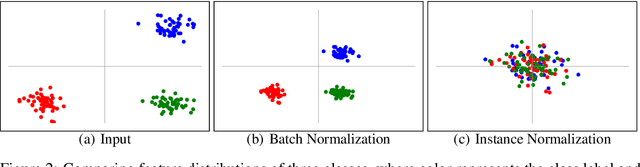
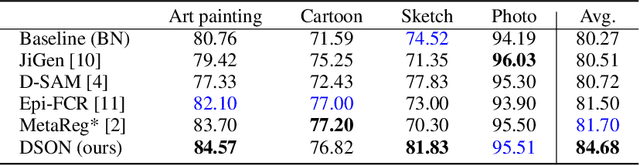
We propose a simple but effective multi-source domain generalization technique based on deep neural networks by incorporating optimized normalization layers specific to individual domains. Our key idea is to decompose discriminative representations in each domain into domain-agnostic and domain-specific components by learning a mixture of multiple normalization types. Because each domain has different characteristics, we optimize the mixture weights specialized to each domain and maximize the generalizability of the learned representations per domain. To this end, we incorporate instance normalization into the network with batch normalization since instance normalization is effective to discard the discriminative domain-specific representations. Since the joint optimization of the parameters in convolutional and normalization layers is not straightforward especially in the lower layers, the mixture weight of the normalization types is shared across all layers for the robustness of trained models. We analyze the effectiveness of the optimized normalization layers and demonstrate the state-of-the-art accuracy of our algorithm in the standard benchmark datasets in various settings.