 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Debiased Representations with Pseudo-Attributes
Paper and Code
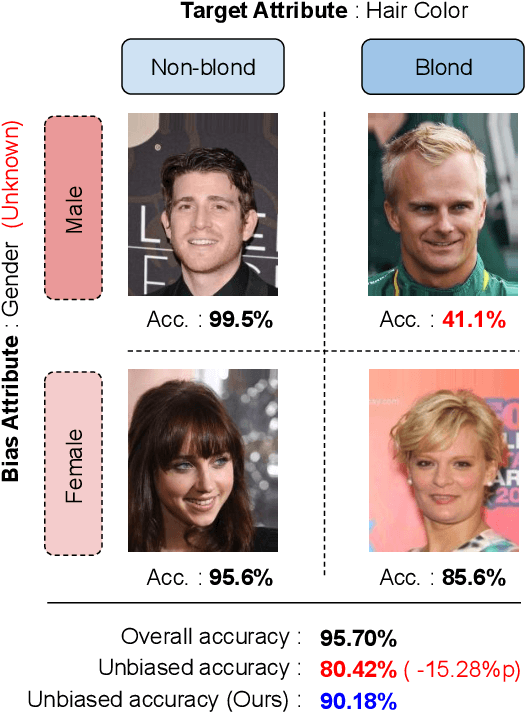
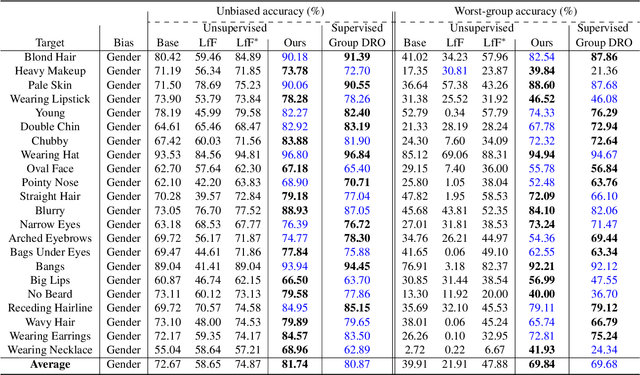

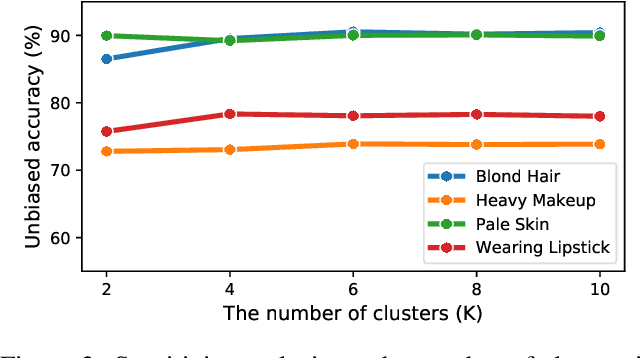
Dataset bias is a critical challenge in machine learning, and its negative impact is aggravated when models capture unintended decision rules with spurious correlations. Although existing works often handle this issue using human supervision, the availability of the proper annotations is impractical and even unrealistic. To better tackle this challenge, we propose a simple but effective debiasing technique in an unsupervised manner. Specifically, we perform clustering on the feature embedding space and identify pseudoattributes by taking advantage of the clustering results even without an explicit attribute supervision. Then, we employ a novel cluster-based reweighting scheme for learning debiased representation; this prevents minority groups from being discounted for minimizing the overall loss, which is desirable for worst-case generalization. The extensive experiments demonstrate the outstanding performance of our approach on multiple standard benchmarks, which is even as competitive as the supervised counterpart.