 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQualitative vision-based navigation based on sloped funnel lane concept
Aug 23, 2018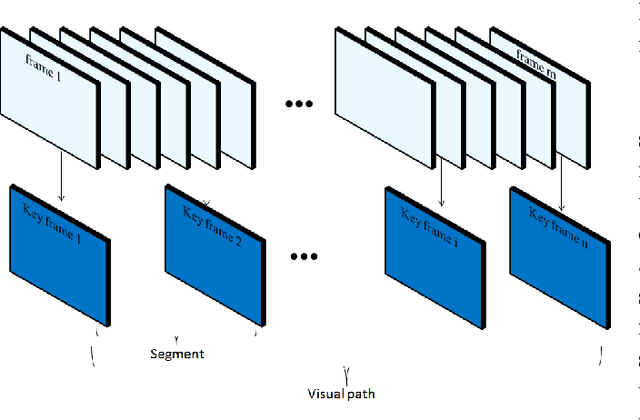

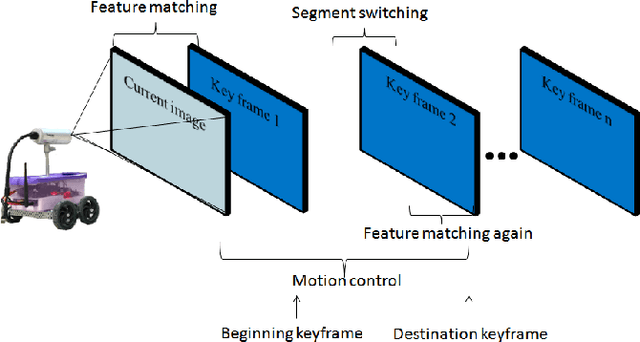
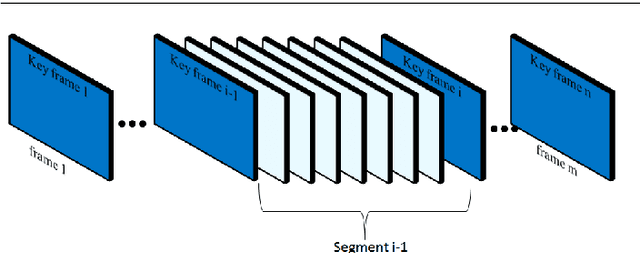
A new visual navigation based on visual teach and repeat technique is described in this paper. In this kind of navigation, a robot is controlled to follow a path while it is recording a video. Some keyframes are extracted from the video. The extracted keyframes are called visual path and the interval between each two keyframes is called a segment. Later, the robot uses these keyframes to navigate autonomously to follow the desired path. Funnel lane is a recent method to follow visual paths which was proposed by Chen and Birchfield. The method requires a single camera with no calibration or any further calculations such as Jacobian, homography or fundamental matrix. A qualitative comparison between features coordinates is done to follow the visual path. Although experimental results on ground and flying robots show the effectiveness of this method, the method has some limitations. It cannot deal with all types of turning conditions such as rotations in place. Another limitation is an ambiguity between translation and rotation which in some cases may cause the robot to deviate from the desired path. In this paper, we introduce the sloped funnel lane and we explain how it can overcome these limitations. In addition, some challenging scenarios were conducted on a real ground robot to show that. Also, the accuracy and the repeatability of both methods were compared in two different paths. The results show that sloped funnel lane is superior.
Log-Euclidean Bag of Words for Human Action Recognition
Jul 07, 2016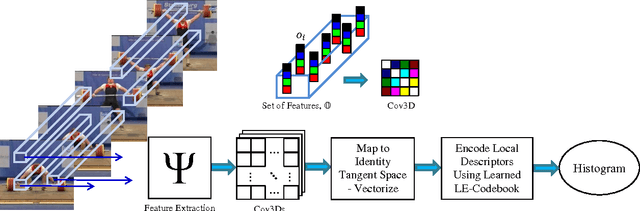

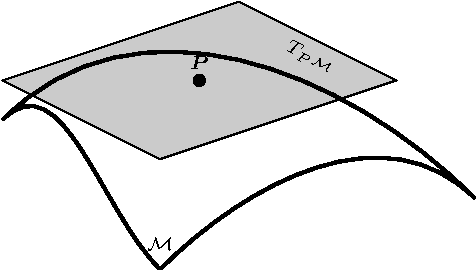

Representing videos by densely extracted local space-time features has recently become a popular approach for analysing actions. In this paper, we tackle the problem of categorising human actions by devising Bag of Words (BoW) models based on covariance matrices of spatio-temporal features, with the features formed from histograms of optical flow. Since covariance matrices form a special type of Riemannian manifold, the space of Symmetric Positive Definite (SPD) matrices, non-Euclidean geometry should be taken into account while discriminating between covariance matrices. To this end, we propose to embed SPD manifolds to Euclidean spaces via a diffeomorphism and extend the BoW approach to its Riemannian version. The proposed BoW approach takes into account the manifold geometry of SPD matrices during the generation of the codebook and histograms. Experiments on challenging human action datasets show that the proposed method obtains notable improvements in discrimination accuracy, in comparison to several state-of-the-art methods.