 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Unscented Kalman Filter-Based SLAM in Dynamic Environments: Euclidean Approach
Dec 19, 2023This paper introduces an innovative approach to Simultaneous Localization and Mapping (SLAM) using the Unscented Kalman Filter (UKF) in a dynamic environment. The UKF is proven to be a robust estimator and demonstrates lower sensitivity to sensor data errors compared to alternative SLAM algorithms. However, conventional algorithms are primarily concerned with stationary landmarks, which might prevent localization in dynamic environments. This paper proposes an Euclidean-based method for handling moving landmarks, calculating and estimating distances between the robot and each moving landmark, and addressing sensor measurement conflicts. The approach is evaluated through simulations in MATLAB and comparing results with the conventional UKF-SLAM algorithm. We also introduce a dataset for filter-based algorithms in dynamic environments, which can be used as a benchmark for evaluating of future algorithms. The outcomes of the proposed algorithm underscore that this simple yet effective approach mitigates the disruptive impact of moving landmarks, as evidenced by a thorough examination involving parameters such as the number of moving and stationary landmarks, waypoints, and computational efficiency. We also evaluated our algorithms in a realistic simulation of a real-world mapping task. This approach allowed us to assess our methods in practical conditions and gain insights for future enhancements. Our algorithm surpassed the performance of all competing methods in the evaluation, showcasing its ability to excel in real-world mapping scenarios.
Multiscale Attention via Wavelet Neural Operators for Vision Transformers
Mar 26, 2023Transformers have achieved widespread success in computer vision. At their heart, there is a Self-Attention (SA) mechanism, an inductive bias that associates each token in the input with every other token through a weighted basis. The standard SA mechanism has quadratic complexity with the sequence length, which impedes its utility to long sequences appearing in high resolution vision. Recently, inspired by operator learning for PDEs, Adaptive Fourier Neural Operators (AFNO) were introduced for high resolution attention based on global convolution that is efficiently implemented via FFT. However, the AFNO global filtering cannot well represent small and moderate scale structures that commonly appear in natural images. To leverage the coarse-to-fine scale structures we introduce a Multiscale Wavelet Attention (MWA) by leveraging wavelet neural operators which incurs linear complexity in the sequence size. We replace the attention in ViT with MWA and our experiments with CIFAR and ImageNet classification demonstrate significant improvement over alternative Fourier-based attentions such as AFNO and Global Filter Network (GFN).
An Event-based Algorithm for Simultaneous 6-DOF Camera Pose Tracking and Mapping
Jan 10, 2023Compared to regular cameras, Dynamic Vision Sensors or Event Cameras can output compact visual data based on a change in the intensity in each pixel location asynchronously. In this paper, we study the application of current image-based SLAM techniques to these novel sensors. To this end, the information in adaptively selected event windows is processed to form motion-compensated images. These images are then used to reconstruct the scene and estimate the 6-DOF pose of the camera. We also propose an inertial version of the event-only pipeline to assess its capabilities. We compare the results of different configurations of the proposed algorithm against the ground truth for sequences of two publicly available event datasets. We also compare the results of the proposed event-inertial pipeline with the state-of-the-art and show it can produce comparable or more accurate results provided the map estimate is reliable.
Qualitative vision-based navigation based on sloped funnel lane concept
Aug 23, 2018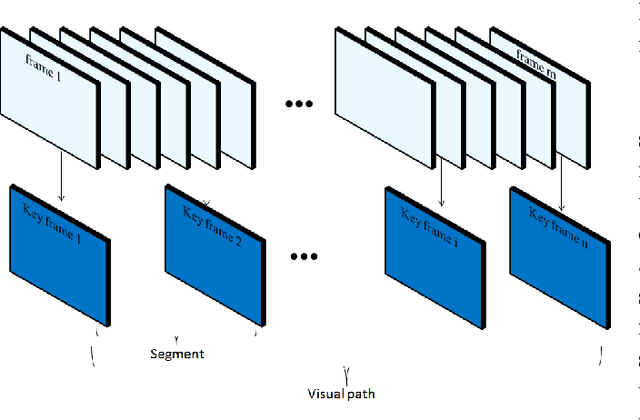

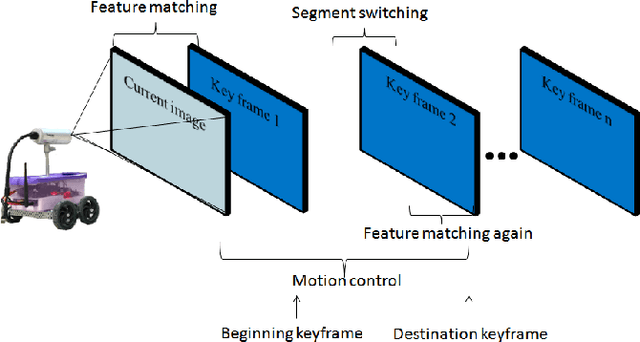
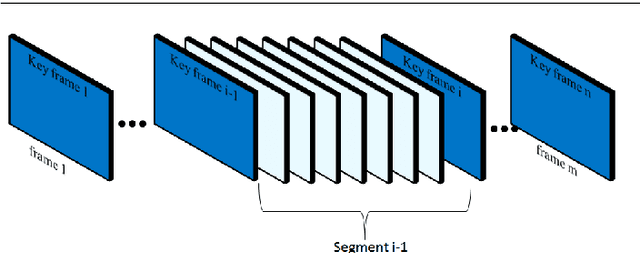
A new visual navigation based on visual teach and repeat technique is described in this paper. In this kind of navigation, a robot is controlled to follow a path while it is recording a video. Some keyframes are extracted from the video. The extracted keyframes are called visual path and the interval between each two keyframes is called a segment. Later, the robot uses these keyframes to navigate autonomously to follow the desired path. Funnel lane is a recent method to follow visual paths which was proposed by Chen and Birchfield. The method requires a single camera with no calibration or any further calculations such as Jacobian, homography or fundamental matrix. A qualitative comparison between features coordinates is done to follow the visual path. Although experimental results on ground and flying robots show the effectiveness of this method, the method has some limitations. It cannot deal with all types of turning conditions such as rotations in place. Another limitation is an ambiguity between translation and rotation which in some cases may cause the robot to deviate from the desired path. In this paper, we introduce the sloped funnel lane and we explain how it can overcome these limitations. In addition, some challenging scenarios were conducted on a real ground robot to show that. Also, the accuracy and the repeatability of both methods were compared in two different paths. The results show that sloped funnel lane is superior.