 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Deep Cross-modality Spectral Hashing
Paper and Code
Aug 18, 2020

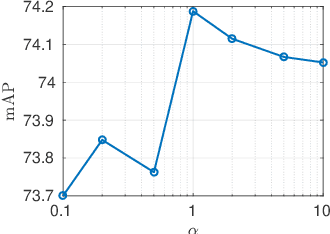
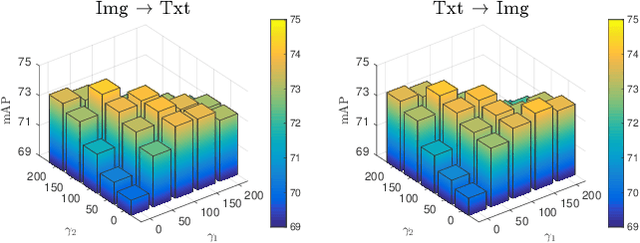
This paper presents a novel framework, namely Deep Cross-modality Spectral Hashing (DCSH), to tackle the unsupervised learning problem of binary hash codes for efficient cross-modal retrieval. The framework is a two-step hashing approach which decouples the optimization into (1) binary optimization and (2) hashing function learning. In the first step, we propose a novel spectral embedding-based algorithm to simultaneously learn single-modality and binary cross-modality representations. While the former is capable of well preserving the local structure of each modality, the latter reveals the hidden patterns from all modalities. In the second step, to learn mapping functions from informative data inputs (images and word embeddings) to binary codes obtained from the first step, we leverage the powerful CNN for images and propose a CNN-based deep architecture to learn text modality. Quantitative evaluations on three standard benchmark datasets demonstrate that the proposed DCSH method consistently outperforms other state-of-the-art methods.