 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAVIS: Multi-Camera Augmented Visual-Inertial SLAM using SE2(3) Based Exact IMU Pre-integration
Sep 18, 2023



We present a novel optimization-based Visual-Inertial SLAM system designed for multiple partially overlapped camera systems, named MAVIS. Our framework fully exploits the benefits of wide field-of-view from multi-camera systems, and the metric scale measurements provided by an inertial measurement unit (IMU). We introduce an improved IMU pre-integration formulation based on the exponential function of an automorphism of SE_2(3), which can effectively enhance tracking performance under fast rotational motion and extended integration time. Furthermore, we extend conventional front-end tracking and back-end optimization module designed for monocular or stereo setup towards multi-camera systems, and introduce implementation details that contribute to the performance of our system in challenging scenarios. The practical validity of our approach is supported by our experiments on public datasets. Our MAVIS won the first place in all the vision-IMU tracks (single and multi-session SLAM) on Hilti SLAM Challenge 2023 with 1.7 times the score compared to the second place.
Asynchronous Optimisation for Event-based Visual Odometry
Mar 02, 2022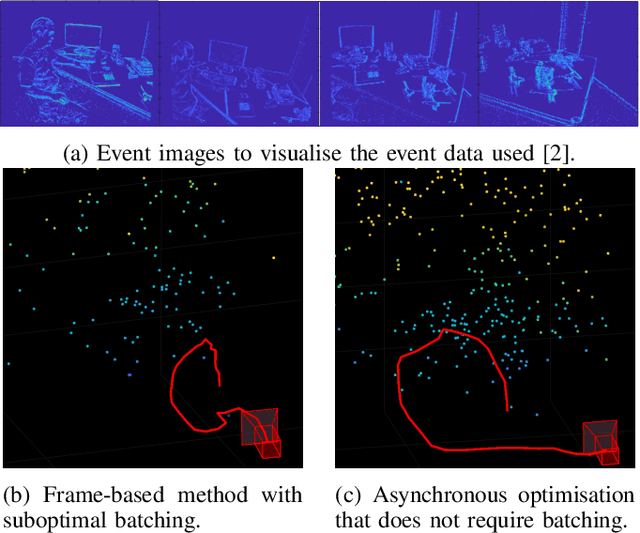


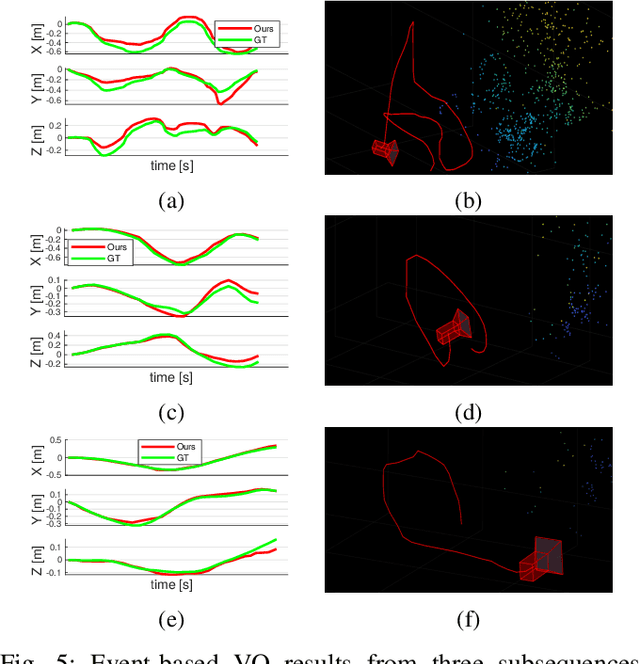
Event cameras open up new possibilities for robotic perception due to their low latency and high dynamic range. On the other hand, developing effective event-based vision algorithms that fully exploit the beneficial properties of event cameras remains work in progress. In this paper, we focus on event-based visual odometry (VO). While existing event-driven VO pipelines have adopted continuous-time representations to asynchronously process event data, they either assume a known map, restrict the camera to planar trajectories, or integrate other sensors into the system. Towards map-free event-only monocular VO in SE(3), we propose an asynchronous structure-from-motion optimisation back-end. Our formulation is underpinned by a principled joint optimisation problem involving non-parametric Gaussian Process motion modelling and incremental maximum a posteriori inference. A high-performance incremental computation engine is employed to reason about the camera trajectory with every incoming event. We demonstrate the robustness of our asynchronous back-end in comparison to frame-based methods which depend on accurate temporal accumulation of measurements.
Fast Semantic-Assisted Outlier Removal for Large-scale Point Cloud Registration
Feb 21, 2022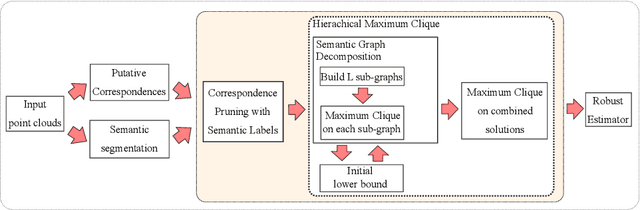
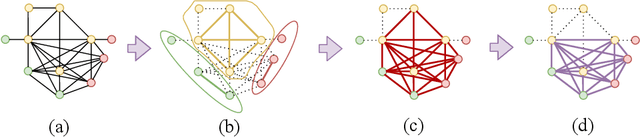

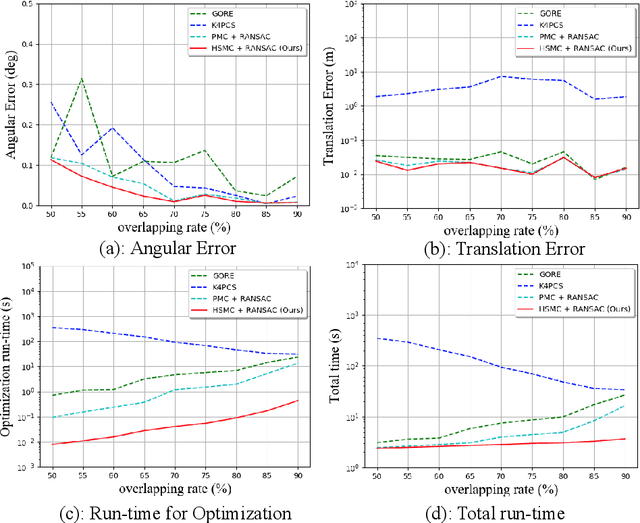
With current trends in sensors (cheaper, more volume of data) and applications (increasing affordability for new tasks, new ideas in what 3D data could be useful for); there is corresponding increasing interest in the ability to automatically, reliably, and cheaply, register together individual point clouds. The volume of data to handle, and still elusive need to have the registration occur fully reliably and fully automatically, mean there is a need to innovate further. One largely untapped area of innovation is that of exploiting the {\em semantic information} of the points in question. Points on a tree should match points on a tree, for example, and not points on car. Moreover, such a natural restriction is clearly human-like - a human would generally quickly eliminate candidate regions for matching based on semantics. Employing semantic information is not only efficient but natural. It is also timely - due to the recent advances in semantic classification capabilities. This paper advances this theme by demonstrating that state of the art registration techniques, in particular ones that rely on "preservation of length under rigid motion" as an underlying matching consistency constraint, can be augmented with semantic information. Semantic identity is of course also preserved under rigid-motion, but also under wider motions present in a scene. We demonstrate that not only the potential obstacle of cost of semantic segmentation, and the potential obstacle of the unreliability of semantic segmentation; are both no impediment to achieving both speed and accuracy in fully automatic registration of large scale point clouds.
Spatiotemporal Registration for Event-based Visual Odometry
Mar 19, 2021
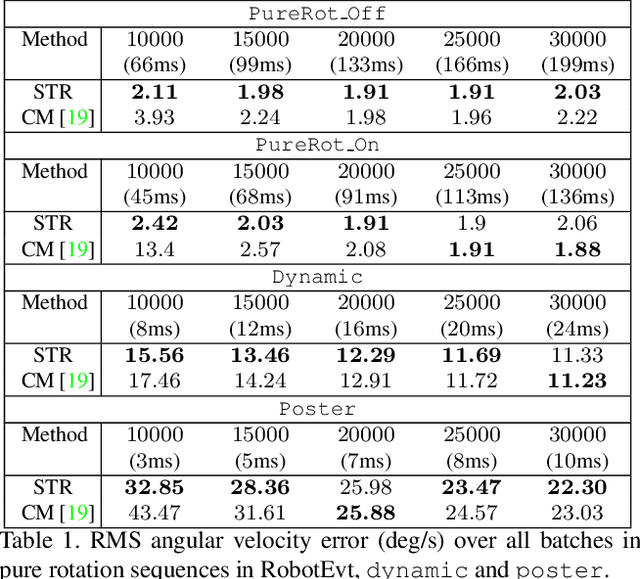
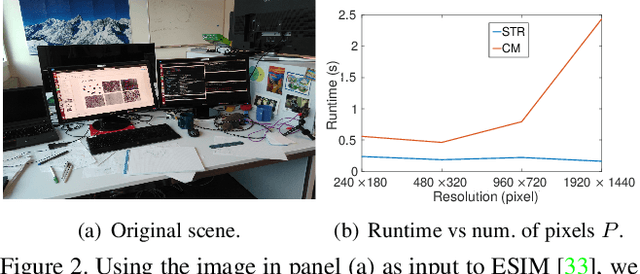
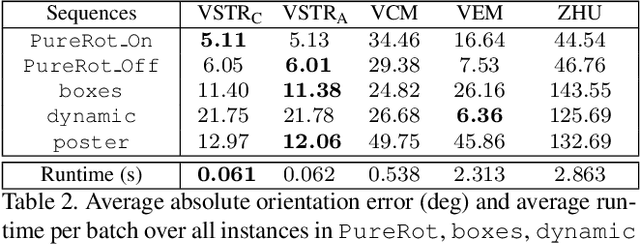
A useful application of event sensing is visual odometry, especially in settings that require high-temporal resolution. The state-of-the-art method of contrast maximisation recovers the motion from a batch of events by maximising the contrast of the image of warped events. However, the cost scales with image resolution and the temporal resolution can be limited by the need for large batch sizes to yield sufficient structure in the contrast image. In this work, we propose spatiotemporal registration as a compelling technique for event-based rotational motion estimation. We theoretcally justify the approach and establish its fundamental and practical advantages over contrast maximisation. In particular, spatiotemporal registration also produces feature tracks as a by-product, which directly supports an efficient visual odometry pipeline with graph-based optimisation for motion averaging. The simplicity of our visual odometry pipeline allows it to process more than 1 M events/second. We also contribute a new event dataset for visual odometry, where motion sequences with large velocity variations were acquired using a high-precision robot arm.
Monocular Rotational Odometry with Incremental Rotation Averaging and Loop Closure
Oct 05, 2020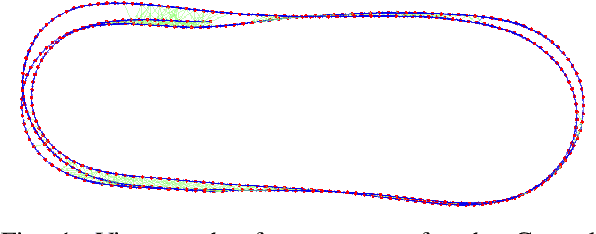
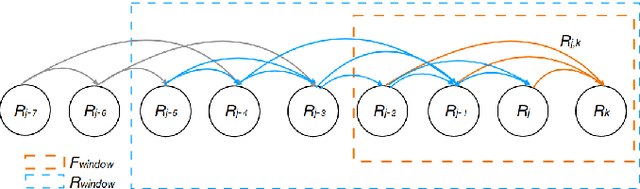
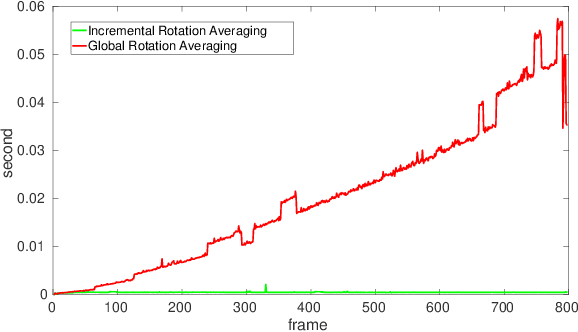
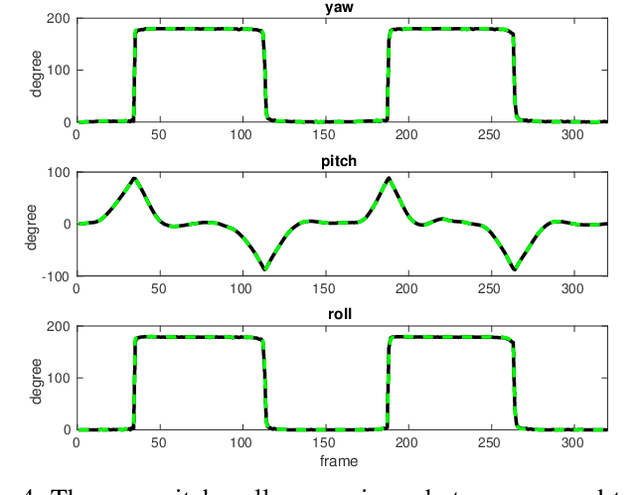
Estimating absolute camera orientations is essential for attitude estimation tasks. An established approach is to first carry out visual odometry (VO) or visual SLAM (V-SLAM), and retrieve the camera orientations (3 DOF) from the camera poses (6 DOF) estimated by VO or V-SLAM. One drawback of this approach, besides the redundancy in estimating full 6 DOF camera poses, is the dependency on estimating a map (3D scene points) jointly with the 6 DOF poses due to the basic constraint on structure-and-motion. To simplify the task of absolute orientation estimation, we formulate the monocular rotational odometry problem and devise a fast algorithm to accurately estimate camera orientations with 2D-2D feature matches alone. Underpinning our system is a new incremental rotation averaging method for fast and constant time iterative updating. Furthermore, our system maintains a view-graph that 1) allows solving loop closure to remove camera orientation drift, and 2) can be used to warm start a V-SLAM system. We conduct extensive quantitative experiments on real-world datasets to demonstrate the accuracy of our incremental camera orientation solver. Finally, we showcase the benefit of our algorithm to V-SLAM: 1) solving the known rotation problem to estimate the trajectory of the camera and the surrounding map, and 2)enabling V-SLAM systems to track pure rotational motions.
Satellite Pose Estimation with Deep Landmark Regression and Nonlinear Pose Refinement
Aug 30, 2019
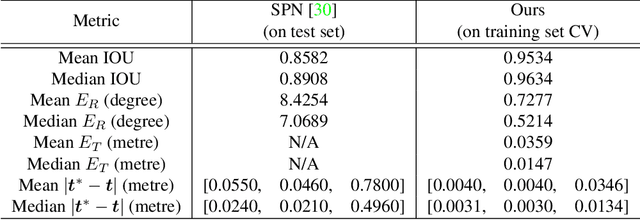
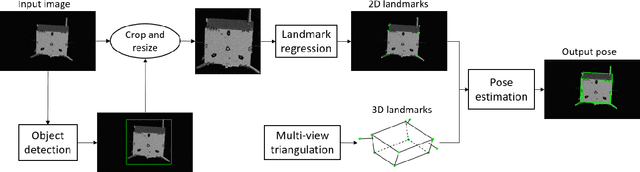
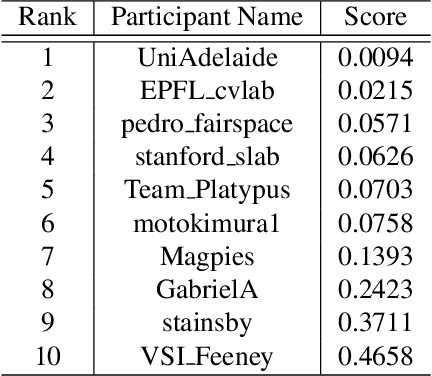
We propose an approach to estimate the 6DOF pose of a satellite, relative to a canonical pose, from a single image. Such a problem is crucial in many space proximity operations, such as docking, debris removal, and inter-spacecraft communications. Our approach combines machine learning and geometric optimisation, by predicting the coordinates of a set of landmarks in the input image, associating the landmarks to their corresponding 3D points on an a priori reconstructed 3D model, then solving for the object pose using non-linear optimisation. Our approach is not only novel for this specific pose estimation task, which helps to further open up a relatively new domain for machine learning and computer vision, but it also demonstrates superior accuracy and won the first place in the recent Kelvins Pose Estimation Challenge organised by the European Space Agency (ESA).