 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Semantic-Assisted Outlier Removal for Large-scale Point Cloud Registration
Paper and Code
Feb 21, 2022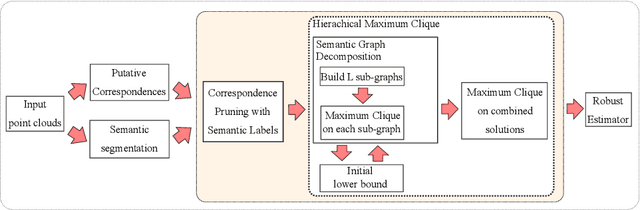
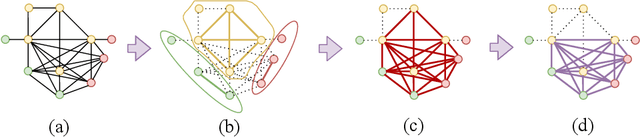

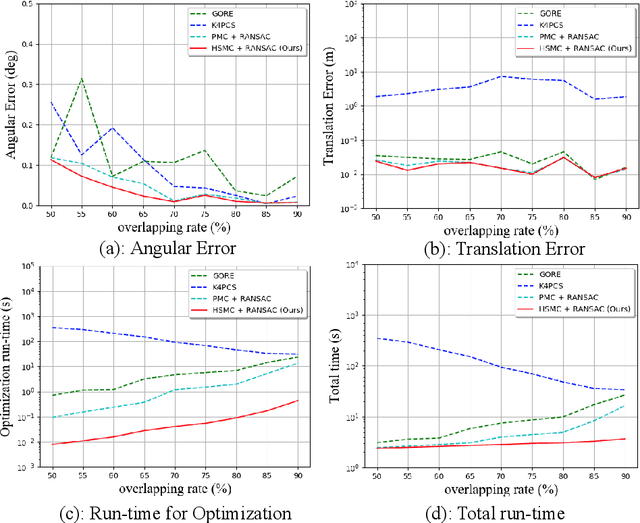
With current trends in sensors (cheaper, more volume of data) and applications (increasing affordability for new tasks, new ideas in what 3D data could be useful for); there is corresponding increasing interest in the ability to automatically, reliably, and cheaply, register together individual point clouds. The volume of data to handle, and still elusive need to have the registration occur fully reliably and fully automatically, mean there is a need to innovate further. One largely untapped area of innovation is that of exploiting the {\em semantic information} of the points in question. Points on a tree should match points on a tree, for example, and not points on car. Moreover, such a natural restriction is clearly human-like - a human would generally quickly eliminate candidate regions for matching based on semantics. Employing semantic information is not only efficient but natural. It is also timely - due to the recent advances in semantic classification capabilities. This paper advances this theme by demonstrating that state of the art registration techniques, in particular ones that rely on "preservation of length under rigid motion" as an underlying matching consistency constraint, can be augmented with semantic information. Semantic identity is of course also preserved under rigid-motion, but also under wider motions present in a scene. We demonstrate that not only the potential obstacle of cost of semantic segmentation, and the potential obstacle of the unreliability of semantic segmentation; are both no impediment to achieving both speed and accuracy in fully automatic registration of large scale point clouds.