 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerteNet -- A Multi-Context Hybrid CNN Transformer for Accurate Vertebral Landmark Localization in Lateral Spine DXA Images
Feb 04, 2025



Lateral Spine Image (LSI) analysis is important for medical diagnosis, treatment planning, and detailed spinal health assessments. Although modalities like Computed Tomography and Digital X-ray Imaging are commonly used, Dual Energy X-ray Absorptiometry (DXA) is often preferred due to lower radiation exposure, seamless capture, and cost-effectiveness. Accurate Vertebral Landmark Localization (VLL) on LSIs is important to detect spinal conditions like kyphosis and lordosis, as well as assessing Abdominal Aortic Calcification (AAC) using Inter-Vertebral Guides (IVGs). Nonetheless, few automated VLL methodologies have concentrated on DXA LSIs. We present VerteNet, a hybrid CNN-Transformer model featuring a novel dual-resolution attention mechanism in self and cross-attention domains, referred to as Dual Resolution Self-Attention (DRSA) and Dual Resolution Cross-Attention (DRCA). These mechanisms capture the diverse frequencies in DXA images by operating at two different feature map resolutions. Additionally, we design a Multi-Context Feature Fusion Block (MCFB) that efficiently integrates the features using DRSA and DRCA. We train VerteNet on 620 DXA LSIs from various machines and achieve superior results compared to existing methods. We also design an algorithm that utilizes VerteNet's predictions in estimating the Region of Interest (ROI) to detect potential abdominal aorta cropping, where inadequate soft tissue hinders calcification assessment. Additionally, we present a small proof-of-concept study to show that IVGs generated from VLL information can improve inter-reader correlation in AAC scoring, addressing two key areas of disagreement in expert AAC-24 scoring: IVG placement and quality control for full abdominal aorta assessment. The code for this work can be found at https://github.com/zaidilyas89/VerteNet.
GLMHA A Guided Low-rank Multi-Head Self-Attention for Efficient Image Restoration and Spectral Reconstruction
Oct 01, 2024



Image restoration and spectral reconstruction are longstanding computer vision tasks. Currently, CNN-transformer hybrid models provide state-of-the-art performance for these tasks. The key common ingredient in the architectural designs of these models is Channel-wise Self-Attention (CSA). We first show that CSA is an overall low-rank operation. Then, we propose an instance-Guided Low-rank Multi-Head selfattention (GLMHA) to replace the CSA for a considerable computational gain while closely retaining the original model performance. Unique to the proposed GLMHA is its ability to provide computational gain for both short and long input sequences. In particular, the gain is in terms of both Floating Point Operations (FLOPs) and parameter count reduction. This is in contrast to the existing popular computational complexity reduction techniques, e.g., Linformer, Performer, and Reformer, for whom FLOPs overpower the efficient design tricks for the shorter input sequences. Moreover, parameter reduction remains unaccounted for in the existing methods.We perform an extensive evaluation for the tasks of spectral reconstruction from RGB images, spectral reconstruction from snapshot compressive imaging, motion deblurring, and image deraining by enhancing the best-performing models with our GLMHA. Our results show up to a 7.7 Giga FLOPs reduction with 370K fewer parameters required to closely retain the original performance of the best-performing models that employ CSA.
AACLiteNet: A Lightweight Model for Detection of Fine-Grained Abdominal Aortic Calcification
Sep 25, 2024



Cardiovascular Diseases (CVDs) are the leading cause of death worldwide, taking 17.9 million lives annually. Abdominal Aortic Calcification (AAC) is an established marker for CVD, which can be observed in lateral view Vertebral Fracture Assessment (VFA) scans, usually done for vertebral fracture detection. Early detection of AAC may help reduce the risk of developing clinical CVDs by encouraging preventive measures. Manual analysis of VFA scans for AAC measurement is time consuming and requires trained human assessors. Recently, efforts have been made to automate the process, however, the proposed models are either low in accuracy, lack granular level score prediction, or are too heavy in terms of inference time and memory footprint. Considering all these shortcomings of existing algorithms, we propose 'AACLiteNet', a lightweight deep learning model that predicts both cumulative and granular level AAC scores with high accuracy, and also has a low memory footprint, and computation cost (Floating Point Operations (FLOPs)). The AACLiteNet achieves a significantly improved one-vs-rest average accuracy of 85.94% as compared to the previous best 81.98%, with 19.88 times less computational cost and 2.26 times less memory footprint, making it implementable on portable computing devices.
SCOL: Supervised Contrastive Ordinal Loss for Abdominal Aortic Calcification Scoring on Vertebral Fracture Assessment Scans
Jul 22, 2023Abdominal Aortic Calcification (AAC) is a known marker of asymptomatic Atherosclerotic Cardiovascular Diseases (ASCVDs). AAC can be observed on Vertebral Fracture Assessment (VFA) scans acquired using Dual-Energy X-ray Absorptiometry (DXA) machines. Thus, the automatic quantification of AAC on VFA DXA scans may be used to screen for CVD risks, allowing early interventions. In this research, we formulate the quantification of AAC as an ordinal regression problem. We propose a novel Supervised Contrastive Ordinal Loss (SCOL) by incorporating a label-dependent distance metric with existing supervised contrastive loss to leverage the ordinal information inherent in discrete AAC regression labels. We develop a Dual-encoder Contrastive Ordinal Learning (DCOL) framework that learns the contrastive ordinal representation at global and local levels to improve the feature separability and class diversity in latent space among the AAC-24 genera. We evaluate the performance of the proposed framework using two clinical VFA DXA scan datasets and compare our work with state-of-the-art methods. Furthermore, for predicted AAC scores, we provide a clinical analysis to predict the future risk of a Major Acute Cardiovascular Event (MACE). Our results demonstrate that this learning enhances inter-class separability and strengthens intra-class consistency, which results in predicting the high-risk AAC classes with high sensitivity and high accuracy.
Fast Semantic-Assisted Outlier Removal for Large-scale Point Cloud Registration
Feb 21, 2022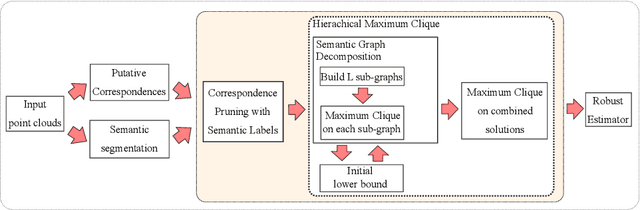
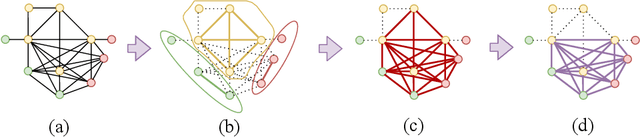

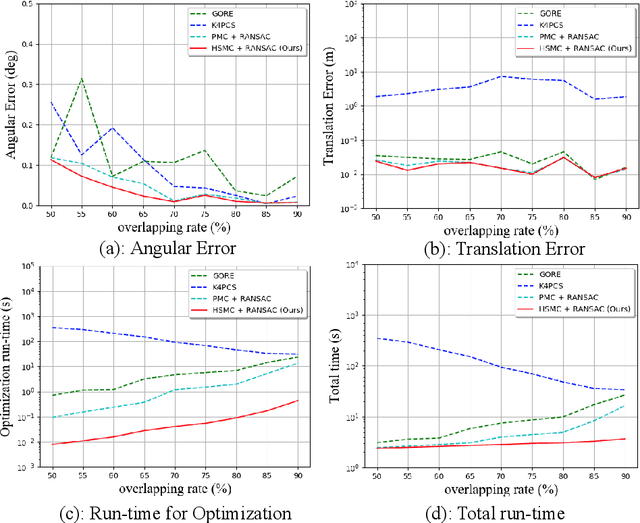
With current trends in sensors (cheaper, more volume of data) and applications (increasing affordability for new tasks, new ideas in what 3D data could be useful for); there is corresponding increasing interest in the ability to automatically, reliably, and cheaply, register together individual point clouds. The volume of data to handle, and still elusive need to have the registration occur fully reliably and fully automatically, mean there is a need to innovate further. One largely untapped area of innovation is that of exploiting the {\em semantic information} of the points in question. Points on a tree should match points on a tree, for example, and not points on car. Moreover, such a natural restriction is clearly human-like - a human would generally quickly eliminate candidate regions for matching based on semantics. Employing semantic information is not only efficient but natural. It is also timely - due to the recent advances in semantic classification capabilities. This paper advances this theme by demonstrating that state of the art registration techniques, in particular ones that rely on "preservation of length under rigid motion" as an underlying matching consistency constraint, can be augmented with semantic information. Semantic identity is of course also preserved under rigid-motion, but also under wider motions present in a scene. We demonstrate that not only the potential obstacle of cost of semantic segmentation, and the potential obstacle of the unreliability of semantic segmentation; are both no impediment to achieving both speed and accuracy in fully automatic registration of large scale point clouds.
Maximum Consensus by Weighted Influences of Monotone Boolean Functions
Dec 10, 2021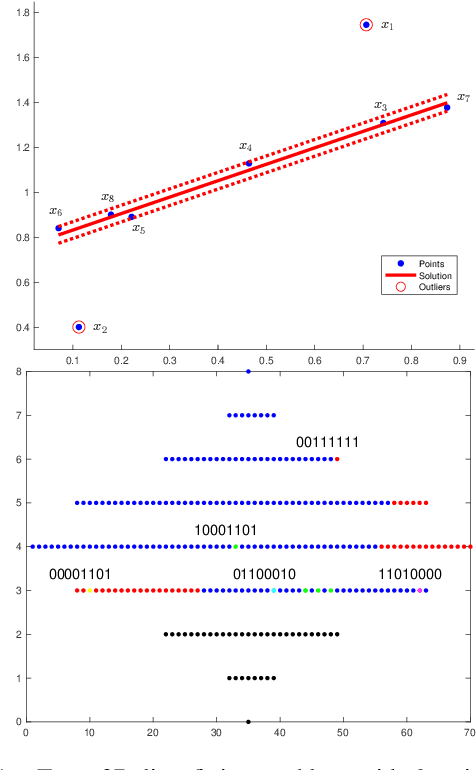
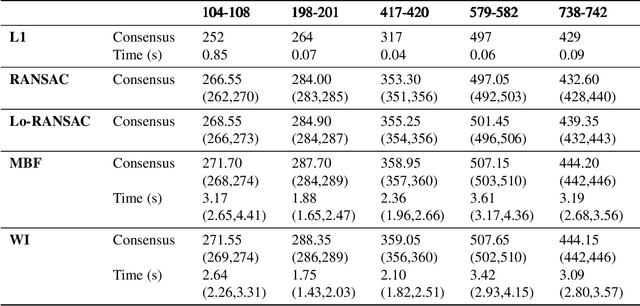
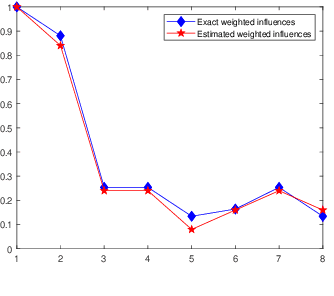
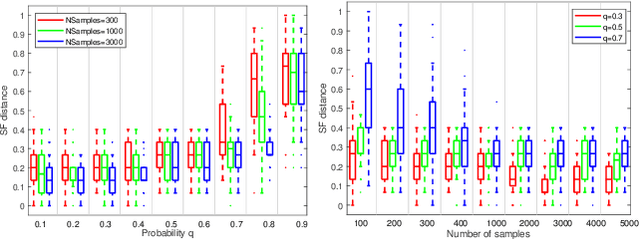
Robust model fitting is a fundamental problem in computer vision: used to pre-process raw data in the presence of outliers. Maximisation of Consensus (MaxCon) is one of the most popular robust criteria and widely used. Recently (Tennakoon et al. CVPR2021), a connection has been made between MaxCon and estimation of influences of a Monotone Boolean function. Equipping the Boolean cube with different measures and adopting different sampling strategies (two sides of the same coin) can have differing effects: which leads to the current study. This paper studies the concept of weighted influences for solving MaxCon. In particular, we study endowing the Boolean cube with the Bernoulli measure and performing biased (as opposed to uniform) sampling. Theoretically, we prove the weighted influences, under this measure, of points belonging to larger structures are smaller than those of points belonging to smaller structures in general. We also consider another "natural" family of sampling/weighting strategies, sampling with uniform measure concentrated on a particular (Hamming) level of the cube. Based on weighted sampling, we modify the algorithm of Tennakoon et al., and test on both synthetic and real datasets. This paper is not promoting a new approach per se, but rather studying the issue of weighted sampling. Accordingly, we are not claiming to have produced a superior algorithm: rather we show some modest gains of Bernoulli sampling, and we illuminate some of the interactions between structure in data and weighted sampling.
Generating Dataset For Large-scale 3D Facial Emotion Recognition
Sep 16, 2021
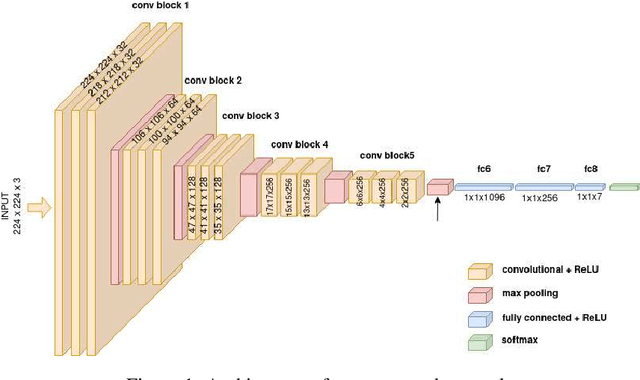

The tremendous development in deep learning has led facial expression recognition (FER) to receive much attention in the past few years. Although 3D FER has an inherent edge over its 2D counterpart, work on 2D images has dominated the field. The main reason for the slow development of 3D FER is the unavailability of large training and large test datasets. Recognition accuracies have already saturated on existing 3D emotion recognition datasets due to their small gallery sizes. Unlike 2D photographs, 3D facial scans are not easy to collect, causing a bottleneck in the development of deep 3D FER networks and datasets. In this work, we propose a method for generating a large dataset of 3D faces with labeled emotions. We also develop a deep convolutional neural network(CNN) for 3D FER trained on 624,000 3D facial scans. The test data comprises 208,000 3D facial scans.
Unsupervised Learning for Robust Fitting:A Reinforcement Learning Approach
Mar 05, 2021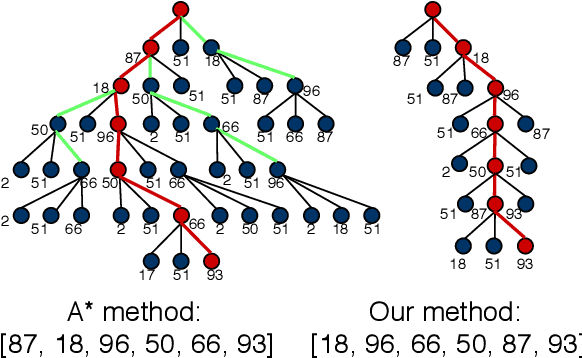
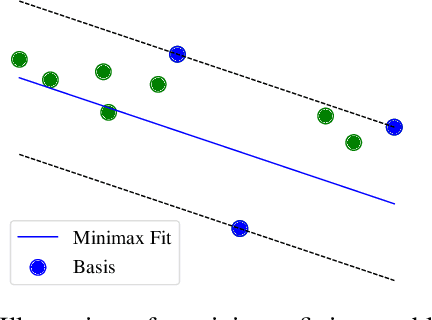
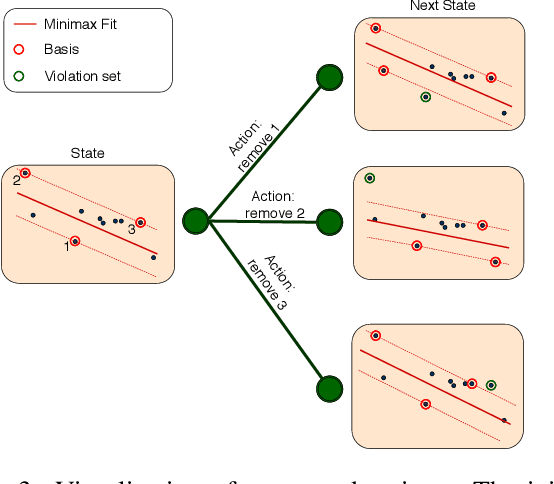
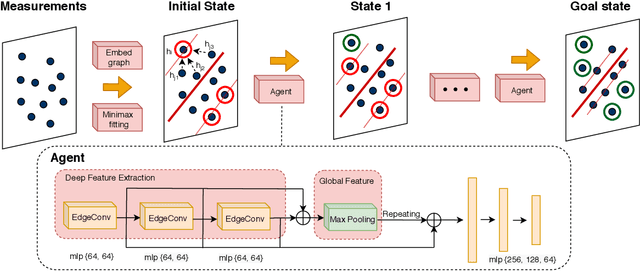
Robust model fitting is a core algorithm in a large number of computer vision applications. Solving this problem efficiently for datasets highly contaminated with outliers is, however, still challenging due to the underlying computational complexity. Recent literature has focused on learning-based algorithms. However, most approaches are supervised which require a large amount of labelled training data. In this paper, we introduce a novel unsupervised learning framework that learns to directly solve robust model fitting. Unlike other methods, our work is agnostic to the underlying input features, and can be easily generalized to a wide variety of LP-type problems with quasi-convex residuals. We empirically show that our method outperforms existing unsupervised learning approaches, and achieves competitive results compared to traditional methods on several important computer vision problems.
Relation Graph Network for 3D Object Detection in Point Clouds
Nov 30, 2019



Convolutional Neural Networks (CNNs) have emerged as a powerful strategy for most object detection tasks on 2D images. However, their power has not been fully realised for detecting 3D objects in point clouds directly without converting them to regular grids. Existing state-of-art 3D object detection methods aim to recognize 3D objects individually without exploiting their relationships during learning or inference. In this paper, we first propose a strategy that associates the predictions of direction vectors and pseudo geometric centers together leading to a win-win solution for 3D bounding box candidates regression. Secondly, we propose point attention pooling to extract uniform appearance features for each 3D object proposal, benefiting from the learned direction features, semantic features and spatial coordinates of the object points. Finally, the appearance features are used together with the position features to build 3D object-object relationship graphs for all proposals to model their co-existence. We explore the effect of relation graphs on proposals' appearance features enhancement under supervised and unsupervised settings. The proposed relation graph network consists of a 3D object proposal generation module and a 3D relation module, makes it an end-to-end trainable network for detecting 3D object in point clouds. Experiments on challenging benchmarks ( SunRGB-Dand ScanNet datasets ) of 3D point clouds show that our algorithm can perform better than the existing state-of-the-art methods.
Point Attention Network for Semantic Segmentation of 3D Point Clouds
Sep 27, 2019
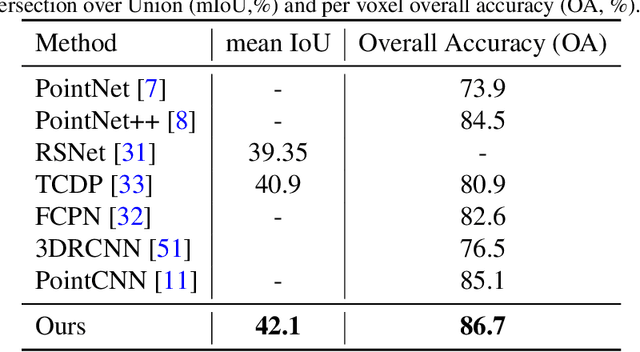


Convolutional Neural Networks (CNNs) have performed extremely well on data represented by regularly arranged grids such as images. However, directly leveraging the classic convolution kernels or parameter sharing mechanisms on sparse 3D point clouds is inefficient due to their irregular and unordered nature. We propose a point attention network that learns rich local shape features and their contextual correlations for 3D point cloud semantic segmentation. Since the geometric distribution of the neighboring points is invariant to the point ordering, we propose a Local Attention-Edge Convolution (LAE Conv) to construct a local graph based on the neighborhood points searched in multi-directions. We assign attention coefficients to each edge and then aggregate the point features as a weighted sum of its neighbors. The learned LAE-Conv layer features are then given to a point-wise spatial attention module to generate an interdependency matrix of all points regardless of their distances, which captures long-range spatial contextual features contributing to more precise semantic information. The proposed point attention network consists of an encoder and decoder which, together with the LAE-Conv layers and the point-wise spatial attention modules, make it an end-to-end trainable network for predicting dense labels for 3D point cloud segmentation. Experiments on challenging benchmarks of 3D point clouds show that our algorithm can perform at par or better than the existing state of the art methods.