 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Attention Network for Semantic Segmentation of 3D Point Clouds
Sep 27, 2019
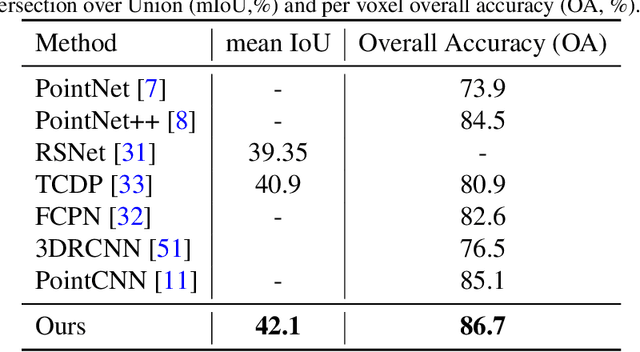


Convolutional Neural Networks (CNNs) have performed extremely well on data represented by regularly arranged grids such as images. However, directly leveraging the classic convolution kernels or parameter sharing mechanisms on sparse 3D point clouds is inefficient due to their irregular and unordered nature. We propose a point attention network that learns rich local shape features and their contextual correlations for 3D point cloud semantic segmentation. Since the geometric distribution of the neighboring points is invariant to the point ordering, we propose a Local Attention-Edge Convolution (LAE Conv) to construct a local graph based on the neighborhood points searched in multi-directions. We assign attention coefficients to each edge and then aggregate the point features as a weighted sum of its neighbors. The learned LAE-Conv layer features are then given to a point-wise spatial attention module to generate an interdependency matrix of all points regardless of their distances, which captures long-range spatial contextual features contributing to more precise semantic information. The proposed point attention network consists of an encoder and decoder which, together with the LAE-Conv layers and the point-wise spatial attention modules, make it an end-to-end trainable network for predicting dense labels for 3D point cloud segmentation. Experiments on challenging benchmarks of 3D point clouds show that our algorithm can perform at par or better than the existing state of the art methods.