 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect initial orbit determination
Aug 28, 2023Initial orbit determination (IOD) is an important early step in the processing chain that makes sense of and reconciles the multiple optical observations of a resident space object. IOD methods generally operate on line-of-sight (LOS) vectors extracted from images of the object, hence the LOS vectors can be seen as discrete point samples of the raw optical measurements. Typically, the number of LOS vectors used by an IOD method is much smaller than the available measurements (\ie, the set of pixel intensity values), hence current IOD methods arguably under-utilize the rich information present in the data. In this paper, we propose a \emph{direct} IOD method called D-IOD that fits the orbital parameters directly on the observed streak images, without requiring LOS extraction. Since it does not utilize LOS vectors, D-IOD avoids potential inaccuracies or errors due to an imperfect LOS extraction step. Two innovations underpin our novel orbit-fitting paradigm: first, we introduce a novel non-linear least-squares objective function that computes the loss between the candidate-orbit-generated streak images and the observed streak images. Second, the objective function is minimized with a gradient descent approach that is embedded in our proposed optimization strategies designed for streak images. We demonstrate the effectiveness of D-IOD on a variety of simulated scenarios and challenging real streak images.
ROSIA: Rotation-Search-Based Star Identification Algorithm
Oct 02, 2022
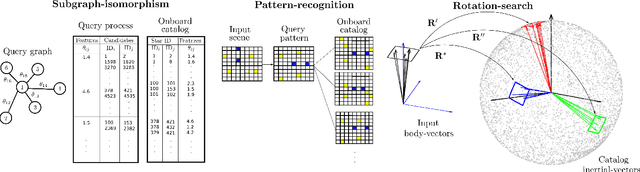

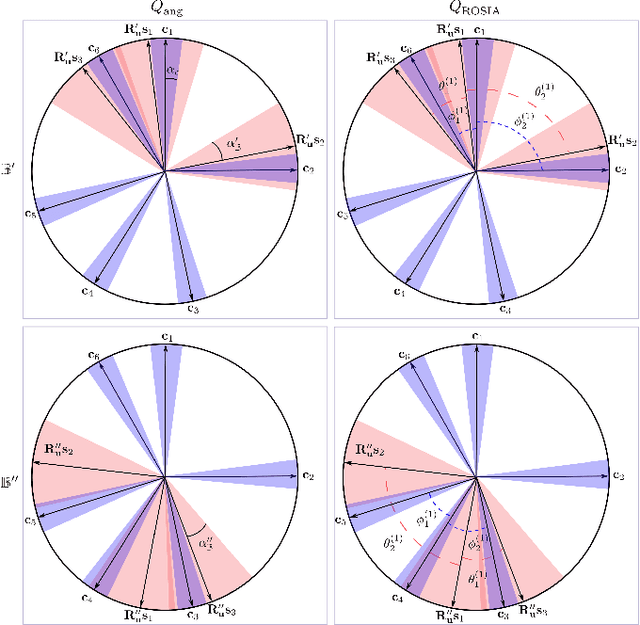
Solving the star identification (Star-ID) problem with a rotation-search-based approach eliminates the conventional heuristics in the established paradigms, i.e., the subgraph-isomorphic-based and pattern-recognition-based methods. However, it is not trivial to execute such an approach efficiently. Here, we present ROSIA, which seeks the optimal rotation alignment that maximally matches the input and catalog stars in their respective coordinates. ROSIA searches the rotation space systematically with the Branch-and-Bound (BnB) method. Crucially affecting the runtime feasibility of ROSIA is the upper bound function that prioritizes the search space. In this paper, we make a theoretical contribution by proposing a tight (provable) upper bound function that allows a 400x speed up compared to an existing formulation. Coupling the bounding function with an efficient evaluation scheme that leverages stereographic projection and the R-tree data structure, ROSIA achieves real-time operational speed with state-of-the-art performances under different sources of noise.
Monocular Rotational Odometry with Incremental Rotation Averaging and Loop Closure
Oct 05, 2020
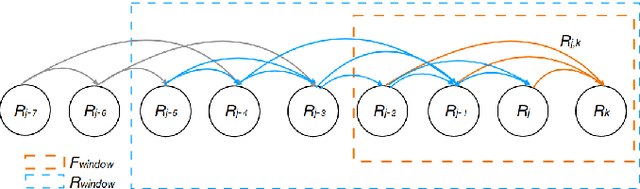
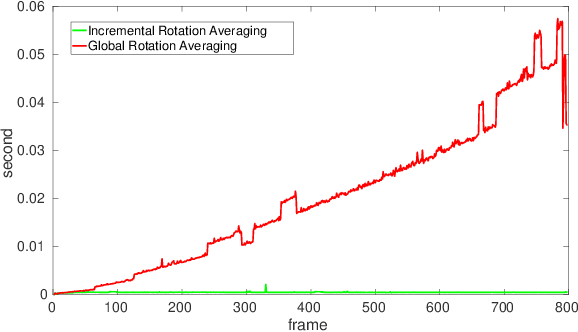
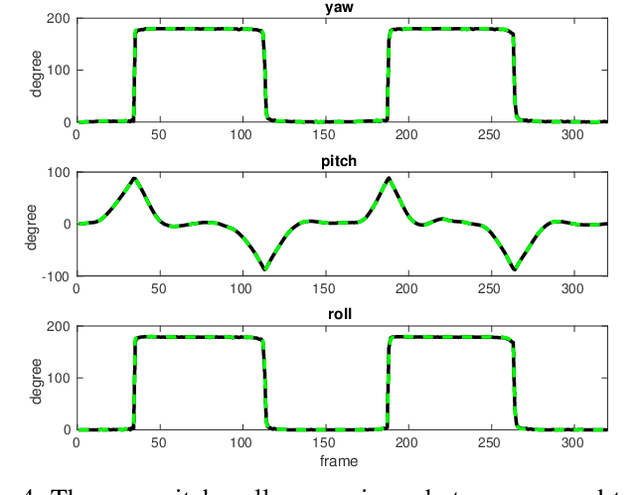
Estimating absolute camera orientations is essential for attitude estimation tasks. An established approach is to first carry out visual odometry (VO) or visual SLAM (V-SLAM), and retrieve the camera orientations (3 DOF) from the camera poses (6 DOF) estimated by VO or V-SLAM. One drawback of this approach, besides the redundancy in estimating full 6 DOF camera poses, is the dependency on estimating a map (3D scene points) jointly with the 6 DOF poses due to the basic constraint on structure-and-motion. To simplify the task of absolute orientation estimation, we formulate the monocular rotational odometry problem and devise a fast algorithm to accurately estimate camera orientations with 2D-2D feature matches alone. Underpinning our system is a new incremental rotation averaging method for fast and constant time iterative updating. Furthermore, our system maintains a view-graph that 1) allows solving loop closure to remove camera orientation drift, and 2) can be used to warm start a V-SLAM system. We conduct extensive quantitative experiments on real-world datasets to demonstrate the accuracy of our incremental camera orientation solver. Finally, we showcase the benefit of our algorithm to V-SLAM: 1) solving the known rotation problem to estimate the trajectory of the camera and the surrounding map, and 2)enabling V-SLAM systems to track pure rotational motions.
ICDAR 2019 Competition on Large-scale Street View Text with Partial Labeling -- RRC-LSVT
Sep 17, 2019


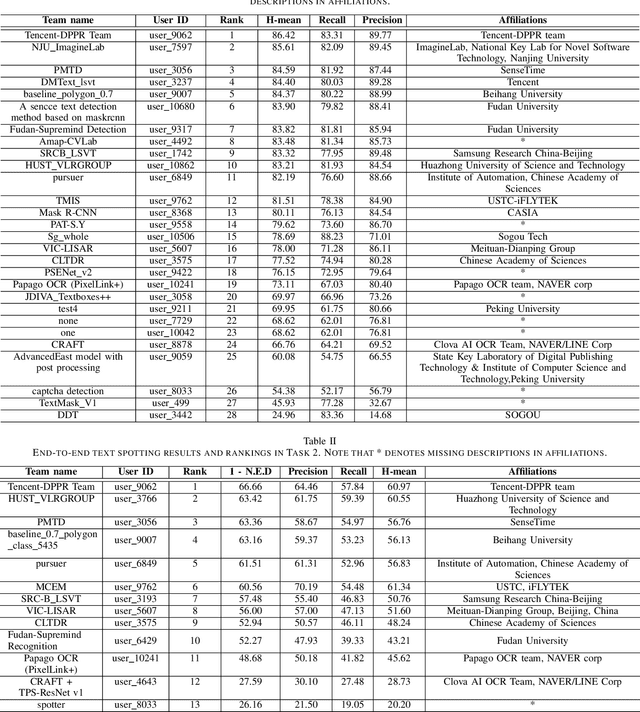
Robust text reading from street view images provides valuable information for various applications. Performance improvement of existing methods in such a challenging scenario heavily relies on the amount of fully annotated training data, which is costly and in-efficient to obtain. To scale up the amount of training data while keeping the labeling procedure cost-effective, this competition introduces a new challenge on Large-scale Street View Text with Partial Labeling (LSVT), providing 50, 000 and 400, 000 images in full and weak annotations, respectively. This competition aims to explore the abilities of state-of-the-art methods to detect and recognize text instances from large-scale street view images, closing the gap between research benchmarks and real applications. During the competition period, a total of 41 teams participated in the two proposed tasks with 132 valid submissions, i.e., text detection and end-to-end text spotting. This paper includes dataset descriptions, task definitions, evaluation protocols and results summaries of the ICDAR 2019-LSVT challenge.
ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text (RRC-ArT)
Sep 16, 2019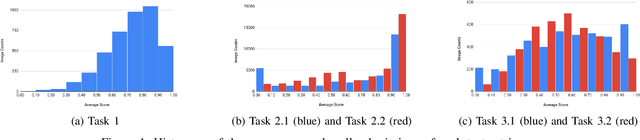



This paper reports the ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text (RRC-ArT) that consists of three major challenges: i) scene text detection, ii) scene text recognition, and iii) scene text spotting. A total of 78 submissions from 46 unique teams/individuals were received for this competition. The top performing score of each challenge is as follows: i) T1 - 82.65%, ii) T2.1 - 74.3%, iii) T2.2 - 85.32%, iv) T3.1 - 53.86%, and v) T3.2 - 54.91%. Apart from the results, this paper also details the ArT dataset, tasks description, evaluation metrics and participants methods. The dataset, the evaluation kit as well as the results are publicly available at https://rrc.cvc.uab.es/?ch=14