 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Visual Information Extraction in Real World: New Dataset and Novel Solution
Jan 24, 2021

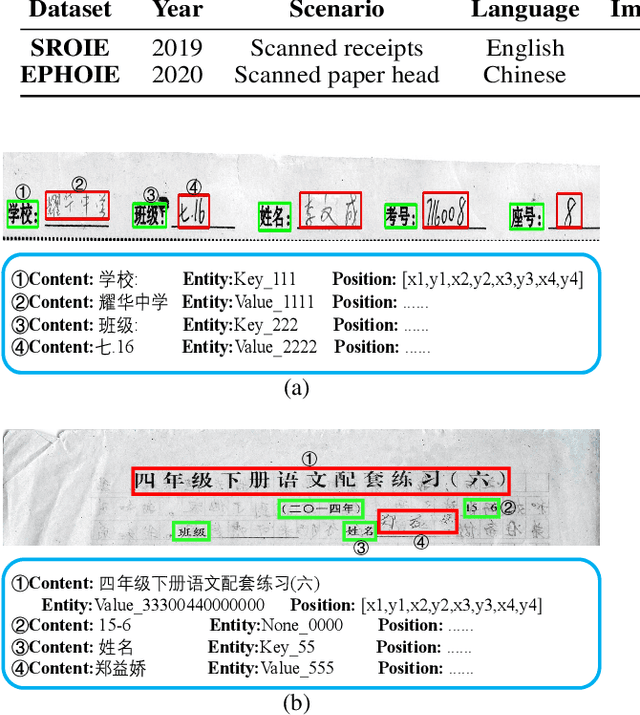
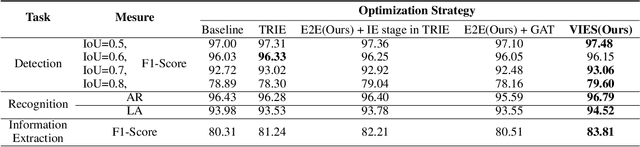
Visual information extraction (VIE) has attracted considerable attention recently owing to its various advanced applications such as document understanding, automatic marking and intelligent education. Most existing works decoupled this problem into several independent sub-tasks of text spotting (text detection and recognition) and information extraction, which completely ignored the high correlation among them during optimization. In this paper, we propose a robust visual information extraction system (VIES) towards real-world scenarios, which is a unified end-to-end trainable framework for simultaneous text detection, recognition and information extraction by taking a single document image as input and outputting the structured information. Specifically, the information extraction branch collects abundant visual and semantic representations from text spotting for multimodal feature fusion and conversely, provides higher-level semantic clues to contribute to the optimization of text spotting. Moreover, regarding the shortage of public benchmarks, we construct a fully-annotated dataset called EPHOIE (https://github.com/HCIILAB/EPHOIE), which is the first Chinese benchmark for both text spotting and visual information extraction. EPHOIE consists of 1,494 images of examination paper head with complex layouts and background, including a total of 15,771 Chinese handwritten or printed text instances. Compared with the state-of-the-art methods, our VIES shows significant superior performance on the EPHOIE dataset and achieves a 9.01% F-score gain on the widely used SROIE dataset under the end-to-end scenario.
Exploring the Capacity of Sequential-free Box Discretization Network for Omnidirectional Scene Text Detection
Dec 20, 2019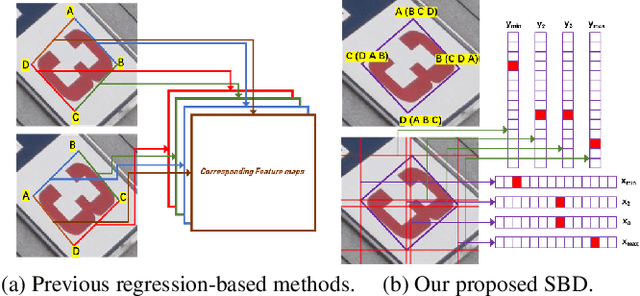
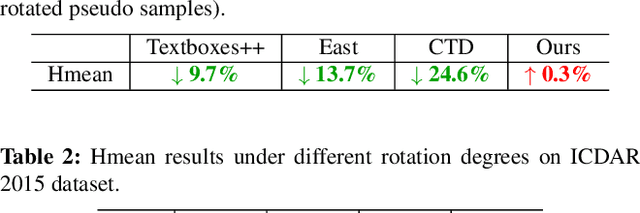
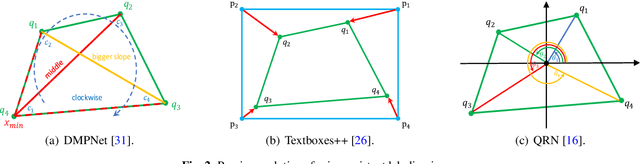

Omnidirectional scene text detection has received increasing research attention. Previous methods directly predict words or text lines of quadrilateral shapes. However, most methods neglect the significance of consistent labeling, which is important to maintain a stable training process, especially when a large amount of data are included. For the first time, we solve the problem in this paper by proposing a novel method termed Sequential-free Box Discretization (SBD). The proposed SBD first discretizes the quadrilateral box into several key edges, which contains all potential horizontal and vertical positions. In order to decode accurate vertex positions, a simple yet effective matching procedure is proposed to reconstruct the quadrilateral bounding boxes. It departs from the learning ambiguity which has a significant influence during the learning process. Exhaustive ablation studies have been conducted to quantitatively validate the effectiveness of our proposed method. More importantly, built upon SBD, we provide a detailed analysis of the impact of a collection of refinements, in the hope to inspire others to build state-of-the-art networks. Combining both SBD and these useful refinements, we achieve state-of-the-art performance on various benchmarks, including ICDAR 2015, and MLT. Our method also wins the first place in text detection task of the recent ICDAR2019 Robust Reading Challenge on Reading Chinese Text on Signboard, further demonstrating its powerful generalization ability. Code is available at https://tinyurl.com/sbdnet.
ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text (RRC-ArT)
Sep 16, 2019



This paper reports the ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text (RRC-ArT) that consists of three major challenges: i) scene text detection, ii) scene text recognition, and iii) scene text spotting. A total of 78 submissions from 46 unique teams/individuals were received for this competition. The top performing score of each challenge is as follows: i) T1 - 82.65%, ii) T2.1 - 74.3%, iii) T2.2 - 85.32%, iv) T3.1 - 53.86%, and v) T3.2 - 54.91%. Apart from the results, this paper also details the ArT dataset, tasks description, evaluation metrics and participants methods. The dataset, the evaluation kit as well as the results are publicly available at https://rrc.cvc.uab.es/?ch=14
Tightness-aware Evaluation Protocol for Scene Text Detection
Mar 27, 2019
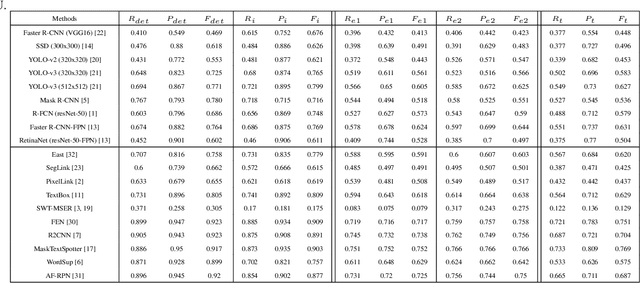

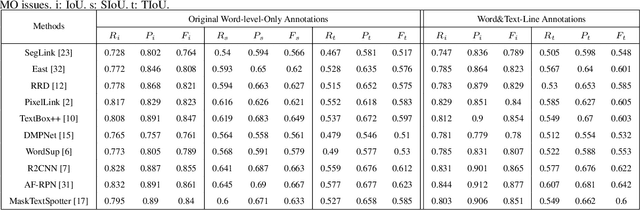
Evaluation protocols play key role in the developmental progress of text detection methods. There are strict requirements to ensure that the evaluation methods are fair, objective and reasonable. However, existing metrics exhibit some obvious drawbacks: 1) They are not goal-oriented; 2) they cannot recognize the tightness of detection methods; 3) existing one-to-many and many-to-one solutions involve inherent loopholes and deficiencies. Therefore, this paper proposes a novel evaluation protocol called Tightness-aware Intersect-over-Union (TIoU) metric that could quantify completeness of ground truth, compactness of detection, and tightness of matching degree. Specifically, instead of merely using the IoU value, two common detection behaviors are properly considered; meanwhile, directly using the score of TIoU to recognize the tightness. In addition, we further propose a straightforward method to address the annotation granularity issue, which can fairly evaluate word and text-line detections simultaneously. By adopting the detection results from published methods and general object detection frameworks, comprehensive experiments on ICDAR 2013 and ICDAR 2015 datasets are conducted to compare recent metrics and the proposed TIoU metric. The comparison demonstrated some promising new prospects, e.g., determining the methods and frameworks for which the detection is tighter and more beneficial to recognize. Our method is extremely simple; however, the novelty is none other than the proposed metric can utilize simplest but reasonable improvements to lead to many interesting and insightful prospects and solving most the issues of the previous metrics. The code is publicly available at https://github.com/Yuliang-Liu/TIoU-metric .
EnsNet: Ensconce Text in the Wild
Dec 03, 2018
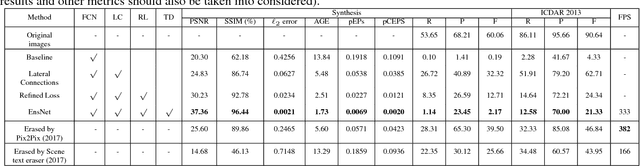
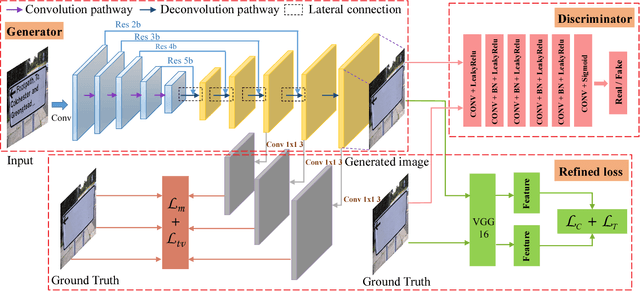
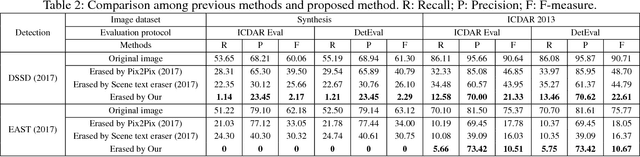
A new method is proposed for removing text from natural images. The challenge is to first accurately localize text on the stroke-level and then replace it with a visually plausible background. Unlike previous methods that require image patches to erase scene text, our method, namely ensconce network (EnsNet), can operate end-to-end on a single image without any prior knowledge. The overall structure is an end-to-end trainable FCN-ResNet-18 network with a conditional generative adversarial network (cGAN). The feature of the former is first enhanced by a novel lateral connection structure and then refined by four carefully designed losses: multiscale regression loss and content loss, which capture the global discrepancy of different level features; texture loss and total variation loss, which primarily target filling the text region and preserving the reality of the background. The latter is a novel local-sensitive GAN, which attentively assesses the local consistency of the text erased regions. Both qualitative and quantitative sensitivity experiments on synthetic images and the ICDAR 2013 dataset demonstrate that each component of the EnsNet is essential to achieve a good performance. Moreover, our EnsNet can significantly outperform previous state-of-the-art methods in terms of all metrics. In addition, a qualitative experiment conducted on the SMBNet dataset further demonstrates that the proposed method can also preform well on general object (such as pedestrians) removal tasks. EnsNet is extremely fast, which can preform at 333 fps on an i5-8600 CPU device.