 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsNet: Ensconce Text in the Wild
Paper and Code

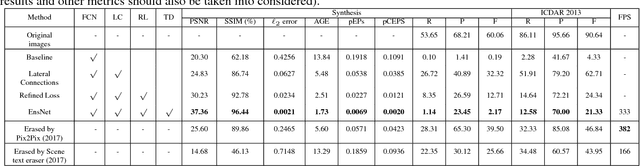
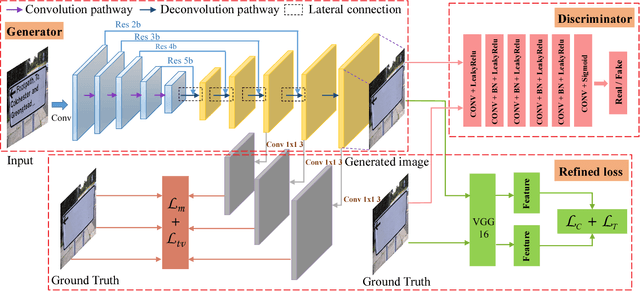
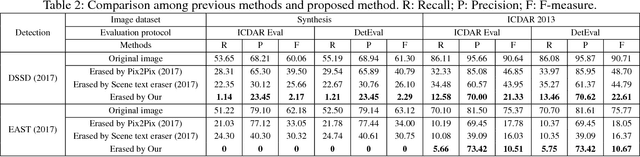
A new method is proposed for removing text from natural images. The challenge is to first accurately localize text on the stroke-level and then replace it with a visually plausible background. Unlike previous methods that require image patches to erase scene text, our method, namely ensconce network (EnsNet), can operate end-to-end on a single image without any prior knowledge. The overall structure is an end-to-end trainable FCN-ResNet-18 network with a conditional generative adversarial network (cGAN). The feature of the former is first enhanced by a novel lateral connection structure and then refined by four carefully designed losses: multiscale regression loss and content loss, which capture the global discrepancy of different level features; texture loss and total variation loss, which primarily target filling the text region and preserving the reality of the background. The latter is a novel local-sensitive GAN, which attentively assesses the local consistency of the text erased regions. Both qualitative and quantitative sensitivity experiments on synthetic images and the ICDAR 2013 dataset demonstrate that each component of the EnsNet is essential to achieve a good performance. Moreover, our EnsNet can significantly outperform previous state-of-the-art methods in terms of all metrics. In addition, a qualitative experiment conducted on the SMBNet dataset further demonstrates that the proposed method can also preform well on general object (such as pedestrians) removal tasks. EnsNet is extremely fast, which can preform at 333 fps on an i5-8600 CPU device.