 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Prompt-Refined In-Context System Modelling for Financial Retrieval
Nov 18, 2025With the rapid progress of large language models (LLMs), financial information retrieval has become a critical industrial application. Extracting task-relevant information from lengthy financial filings is essential for both operational and analytical decision-making. The FinAgentBench dataset formalizes this problem through two tasks: document ranking and chunk ranking. We present PRISM, a training-free framework that integrates refined system prompting, in-context learning (ICL), and a lightweight multi-agent system. Each component is examined extensively to reveal their synergies: prompt engineering provides precise task instructions, ICL supplies semantically relevant few-shot examples, and the multi-agent system models coordinated scoring behaviour. Our best configuration achieves an NDCG@5 of 0.71818 on the restricted validation split. We further demonstrate that PRISM is feasible and robust for production-scale financial retrieval. Its modular, inference-only design makes it practical for real-world use cases. The source code is released at https://bit.ly/prism-ailens.
Text in the Dark: Extremely Low-Light Text Image Enhancement
Apr 22, 2024



Extremely low-light text images are common in natural scenes, making scene text detection and recognition challenging. One solution is to enhance these images using low-light image enhancement methods before text extraction. However, previous methods often do not try to particularly address the significance of low-level features, which are crucial for optimal performance on downstream scene text tasks. Further research is also hindered by the lack of extremely low-light text datasets. To address these limitations, we propose a novel encoder-decoder framework with an edge-aware attention module to focus on scene text regions during enhancement. Our proposed method uses novel text detection and edge reconstruction losses to emphasize low-level scene text features, leading to successful text extraction. Additionally, we present a Supervised Deep Curve Estimation (Supervised-DCE) model to synthesize extremely low-light images based on publicly available scene text datasets such as ICDAR15 (IC15). We also labeled texts in the extremely low-light See In the Dark (SID) and ordinary LOw-Light (LOL) datasets to allow for objective assessment of extremely low-light image enhancement through scene text tasks. Extensive experiments show that our model outperforms state-of-the-art methods in terms of both image quality and scene text metrics on the widely-used LOL, SID, and synthetic IC15 datasets. Code and dataset will be released publicly at https://github.com/chunchet-ng/Text-in-the-Dark.
Extremely Low-light Image Enhancement with Scene Text Restoration
Apr 01, 2022
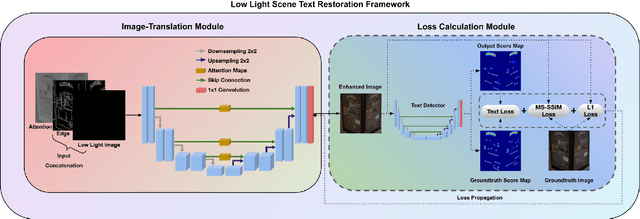


Deep learning-based methods have made impressive progress in enhancing extremely low-light images - the image quality of the reconstructed images has generally improved. However, we found out that most of these methods could not sufficiently recover the image details, for instance, the texts in the scene. In this paper, a novel image enhancement framework is proposed to precisely restore the scene texts, as well as the overall quality of the image simultaneously under extremely low-light images conditions. Mainly, we employed a self-regularised attention map, an edge map, and a novel text detection loss. In addition, leveraging synthetic low-light images is beneficial for image enhancement on the genuine ones in terms of text detection. The quantitative and qualitative experimental results have shown that the proposed model outperforms state-of-the-art methods in image restoration, text detection, and text spotting on See In the Dark and ICDAR15 datasets.
ICDAR 2021 Competition on Integrated Circuit Text Spotting and Aesthetic Assessment
Jul 12, 2021



With hundreds of thousands of electronic chip components are being manufactured every day, chip manufacturers have seen an increasing demand in seeking a more efficient and effective way of inspecting the quality of printed texts on chip components. The major problem that deters this area of research is the lacking of realistic text on chips datasets to act as a strong foundation. Hence, a text on chips dataset, ICText is used as the main target for the proposed Robust Reading Challenge on Integrated Circuit Text Spotting and Aesthetic Assessment (RRC-ICText) 2021 to encourage the research on this problem. Throughout the entire competition, we have received a total of 233 submissions from 10 unique teams/individuals. Details of the competition and submission results are presented in this report.
* Technical report of ICDAR 2021 Competition on Integrated Circuit Text Spotting and Aesthetic Assessment
On the General Value of Evidence, and Bilingual Scene-Text Visual Question Answering
Feb 26, 2020
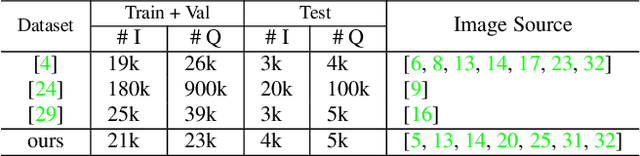

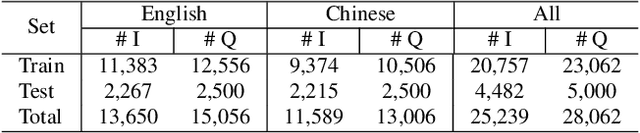
Visual Question Answering (VQA) methods have made incredible progress, but suffer from a failure to generalize. This is visible in the fact that they are vulnerable to learning coincidental correlations in the data rather than deeper relations between image content and ideas expressed in language. We present a dataset that takes a step towards addressing this problem in that it contains questions expressed in two languages, and an evaluation process that co-opts a well understood image-based metric to reflect the method's ability to reason. Measuring reasoning directly encourages generalization by penalizing answers that are coincidentally correct. The dataset reflects the scene-text version of the VQA problem, and the reasoning evaluation can be seen as a text-based version of a referring expression challenge. Experiments and analysis are provided that show the value of the dataset.
ICDAR 2019 Competition on Large-scale Street View Text with Partial Labeling -- RRC-LSVT
Sep 17, 2019


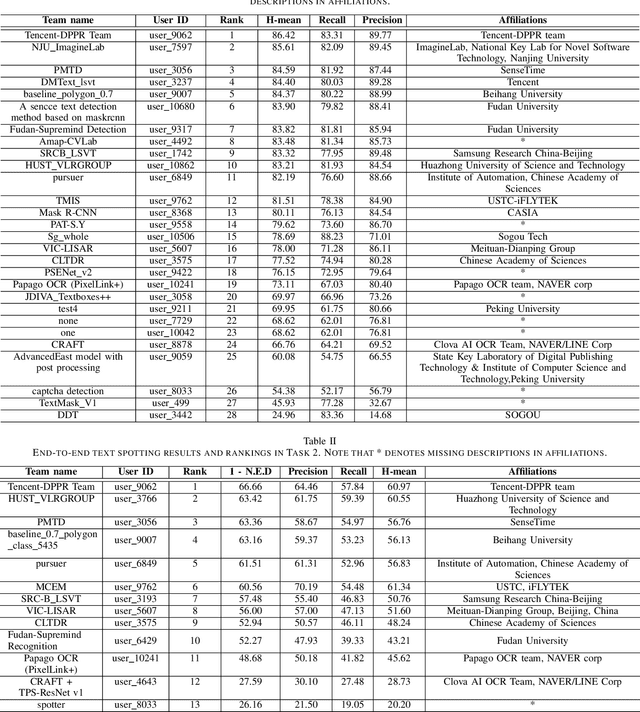
Robust text reading from street view images provides valuable information for various applications. Performance improvement of existing methods in such a challenging scenario heavily relies on the amount of fully annotated training data, which is costly and in-efficient to obtain. To scale up the amount of training data while keeping the labeling procedure cost-effective, this competition introduces a new challenge on Large-scale Street View Text with Partial Labeling (LSVT), providing 50, 000 and 400, 000 images in full and weak annotations, respectively. This competition aims to explore the abilities of state-of-the-art methods to detect and recognize text instances from large-scale street view images, closing the gap between research benchmarks and real applications. During the competition period, a total of 41 teams participated in the two proposed tasks with 132 valid submissions, i.e., text detection and end-to-end text spotting. This paper includes dataset descriptions, task definitions, evaluation protocols and results summaries of the ICDAR 2019-LSVT challenge.
ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text (RRC-ArT)
Sep 16, 2019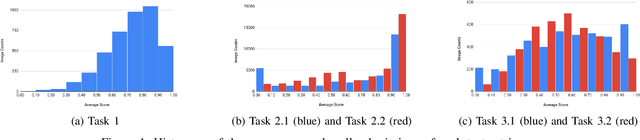



This paper reports the ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text (RRC-ArT) that consists of three major challenges: i) scene text detection, ii) scene text recognition, and iii) scene text spotting. A total of 78 submissions from 46 unique teams/individuals were received for this competition. The top performing score of each challenge is as follows: i) T1 - 82.65%, ii) T2.1 - 74.3%, iii) T2.2 - 85.32%, iv) T3.1 - 53.86%, and v) T3.2 - 54.91%. Apart from the results, this paper also details the ArT dataset, tasks description, evaluation metrics and participants methods. The dataset, the evaluation kit as well as the results are publicly available at https://rrc.cvc.uab.es/?ch=14